-13 = \(\frac{r}{9}\) +8
what is r?
Answers
Answer:
\( - 13= \frac{r}{9} + 8 \\ \frac{r}{9} = - 13 - 8 \\ \frac{r}{9} = - 21 \\ r = 9 \times - 21 \\ r = - 189\)
I hope I helped you^_^
Related Questions
if the alpha level is changed from 0.05 to 0.01, what effect does this have on beta?
Answers
Answer:
beta increases
Step-by-step explanation:
find the sum of the series 1+2+4+5+7+8+10+11+...+299
Answers
Answer:
30,000
Step-by-step explanation:
Three spheres each with charge Q uniformly distributed through its volume Rank the spheres according to the magnitude of the electric field they produced at point P (greatest firstl P (1) (2) (3) Select one: a. 3 > 2 > 1 b. all tie c. 1>2>3 d. 1 and 2 tie > 3 e. 2 > 3 >1
Answers
The correct ranking of the spheres according to the magnitude of the electric field they produce at point P (greatest first) is: 1 > 2 > 3. The answer is option C.
Since all three spheres have the same charge Q and radius, the magnitude of the electric field at point P due to each sphere is proportional to 1/d^2, where d is the distance between the center of the sphere and point P. Therefore, the sphere closest to point P will produce the greatest electric field at that point.
Assuming that the three spheres are arranged in a straight line with sphere 1 being the closest to point P and sphere 3 being the farthest, we can rank the spheres according to the magnitude of the electric field they produce at point P as follows:
Sphere 1 produces the greatest electric field at point P since it is the closest to it.
Sphere 2 produces the second greatest electric field at point P since it is farther away from point P than sphere 1 but closer than sphere 3.
Sphere 3 produces the smallest electric field at point P since it is the farthest from it.
To learn more about probability click on,
https://brainly.com/question/11994012
#SPJ4
why might a researcher choose purposive sampling over systematic sampling? group of answer choices purposive sampling is always cheaper. external validity is not vital to the researcher’s study. only purposive sampling allows the researcher to study a particular type of participant. the researcher does not have to specify a population of interest ahead of time
Answers
The correct answer is Option C. A researcher might choose purposive sampling over systematic sampling for several reasons. One key reason is that purposive sampling allows the researcher to study a particular type of participant.
This means that the researcher can select individuals who possess specific characteristics or traits that are relevant to their study.
By handpicking participants, the researcher can ensure that the sample represents the specific population they are interested in studying, which is particularly useful when investigating rare or hard-to-reach populations.
On the other hand, systematic sampling involves selecting participants at regular intervals from a larger population.
This method may not provide the same level of control in selecting participants based on specific characteristics.
While systematic sampling can be more efficient in terms of time and cost, it may not be suitable for certain research objectives that require a targeted approach.
It is important to note that neither method is inherently cheaper or more expensive than the other, and the choice between them depends on the research objectives and the specific population under investigation.
Therefore, option A is incorrect.
Option B is also incorrect because external validity is still important in research regardless of the sampling method chosen.
Option D is also incorrect since researchers using purposive sampling must still specify their population of interest.
Thus, the correct answer is option C.
For more questions on researcher
https://brainly.com/question/32544768
#SPJ8
DRIVERS ED(TRUE OR FALSE) When passing another vehicle you must be able to complete the pass by returning to the right side before coming within a distance of at least 100 feet of any oncoming vehicles.
True
False
Answers
Answer:
It
Step-by-step explanation:
Is true because if you didn’t, who know what would happen
here is concern that regular customers will find out about the special order, and in order to retain all of the x company's regular customers, the regular selling price would have to be reduced by $0.32. if the selling price were reduced and next year's unit sales turn out to be the same as this year's sales, firm profits would fall by
Answers
Profit fall in one year = 116.8$
What is profit?
In accounting, a profit is an income that is given to the owner throughout a successful market producing process. Profitability, which is the owner's primary interest in the income-formation process of market production, is measured by profit. There are several profit metrics that are frequently used.
Let cost price = C
And selling price before reducing = S
Profit for 1 day = S-C
Now, After reducing selling price to = S-0.32
Profit= S - 0.32 - C for 1 day
Profit fall by = (S-C)-(S - 0.32 - C)
= S - C - S + 0.32 + C
Profit fall by = 0.32 for 1 day
Profit fall by one year = 0.32×365
= 116.8$
Learn more about profit link below.
https://brainly.com/question/1078746
#SPJ4
if there is no association between two variables, what should be the value of the slope of the regression line
Answers
If there is no association between two variables, then the slope of the regression line would be zero.
This means that there is no linear relationship between the two variables, and the value of one variable does not predict or influence the value of the other variable. In other words, the regression line would be a horizontal line with a slope of zero.
It is important to note that the absence of a linear relationship between two variables does not necessarily mean that there is no relationship between them.
There could be other types of relationships that are not captured by a linear model, such as nonlinear or non-monotonic relationships, or interactions between variables.
It is also possible that there is no relationship at all between the two variables. In any case, if there is no linear relationship, the slope of the regression line would be zero.
To know more about Regression , visit
https://brainly.com/question/31629167
#SPJ4
For the given confidence level and values of x and n, find the following, x=46, n=98, confidence level 99.8% Part 1 of 3 Part 3 of 3 (c) Find the margin of error. Round the answers to at least four decimal places, if necessary. The margin of error for the given data is .1415 х 5
Answers
The margin of error is 0.1415, where z is the critical value for the desired confidence level,
The margin of error can be calculated using the formula: Margin of error = z * (standard deviation / sqrt(n))
where z is the critical value for the desired confidence level, standard deviation is the population standard deviation (which can be estimated using the sample standard deviation), and n is the sample size.
For a 99.8% confidence level, the critical value is 2.967. Using the given values of x and n, we can calculate the sample proportion as 46/98 = 0.4694.
To estimate the population standard deviation, we can assume that the sample proportion is a good estimate of the population proportion, and use the formula:
standard deviation = sqrt(p*(1-p)/n)
where p is the sample proportion. Substituting the values, we get: standard deviation = sqrt(0.4694*(1-0.4694)/98) = 0.0519
Now we can plug in the values into the margin of error formula to get: Margin of error = 2.967 * (0.0519 / sqrt(98)) = 0.1415
Therefore, the margin of error is 0.1415.
It is important to note that the margin of error represents the amount by which the sample proportion may differ from the population proportion with a certain level of confidence.
It is also important to remember that the margin of error is not the same as the sampling error, which is the difference between the sample mean and the population mean.
The margin of error can be used to determine the sample size required for a given level of precision, or to compare different sample sizes to determine which is more likely to yield a representative sample.
To know more about value click here
brainly.com/question/30760879
#SPJ11
Which is the best way to write the underlined parts of sentences 2 and 3?
(2) They have a special finish. (3) The finish helps the
swimmer glide through the water.
Click for the passage, "New Swimsuits."
OA. Leave as is.
B. a special finish that helps
C. a special finish, but the finish helps
D. a special finish so the finish helps
Answers
Answer:
Option B is the best way to write the underlined parts of sentences 2 and 3.
Sentence 2: They have a special finish that helps.
Sentence 3: The finish helps the swimmer glide through the water.
Option B provides a clear and concise way to connect the two sentences and convey the idea that the special finish of the swimsuits helps the swimmer glide through the water. It avoids any ambiguity or redundancy in the language.
Membership to a music club costs $165. Members
pay $25 per music lesson and nonmembers pay $40
per music lesson. How many music lessons would
have to be taken for the cost to be the same for
members and nonmembers?
plz my time is running out
Answers
Answer:
11 music lessons.
Step-by-step explanation:
We know that membership costs $165 and members pay $25 per music lesson.
So, we can write the following expression:
\(165+25m\)
The 165 represents the one-time membership fee and the 25m represents the cost for m music lessons.
We know that non-members pay no membership fee but their cost per lesson is $40. So:
\(40m\)
Represents the cost for non-members for m music lessons.
We want to find how many music lessons would have to be taken for the cost to be the same for both members and non-members. So, we can set the expressions equal to each other:
\(165+25m=40m\)
And solve for m. Let's subtract 25m from both sides:
\(165=15m\)
Now, divide both sides by 15:
\(m=11\)
So, at the 11th music lesson, members and non-members will pay the same.
Further Notes:
This means that if a person would only like to take 10 or less lessons, the non-membership is best because there is no initial fee.
However, if a person would like to take 12 or more lessons, than the membership is best because the membership has a lower cost per lesson than the non-membership.
And we're done!
Question
Ahmet borrows $700 and is charged compound interest at 15% per year. How much will he have to pay back in total after 6
years?
Give your answer to two decimal places.
Answers
Answer:
I did 700 - 15% times that answer by 6 and u get that big answer.

The required amount Ahmet needs to pay after 6 years is $1619.14.
What is compound interest?Compound interest is the interest on deposits computed on both the initial principal and the interest earned over time.
Amount = principal[1 + r/n]ⁿᵃ
Principal = P rate= r Time =a , n = compounding frequency
Here,
From the given data,
P = 700, r = 15% and t = 6 (n =1)
Now,
Amount = principal[1 + r/n]ⁿᵃ
Amount = 700(1 + 0.15)⁶
Amount = $1619.14
Thus, the required amount Ahmet needs to pay after 6 years is $1619.14.
Learn more about compound interest here: https://brainly.com/question/14295570
#SPJ2
Brady, Dana, Elijah, and Gianna took part in the school play. Before the start of the play, they each guessed the number of people who would come to see the play. Brady guessed 292 people, Dana guessed 325 people, Elijah guessed 340 people, and Gianna guessed 371 people. It turned out that Dana's guess was the closest, Elijah's guess was the second closest, and Brady's guess was the farthest from the actual number. What is the actual number of people who came to see the play?
Answers
Answer:
332
Step-by-step explanation:
Since Dana had the closest guess with 325 people and Elijah had the second closest guess with 340 people we know that the actual number of guests is close to these values. Since Brady had the farthest guess then that means that the actual number of guests is higher than 325 and lower than 340. Therefore the actual number of guests can only be 332 as it is between Dana and Elijah's guesses but still favoring Dana, and also being farthest from Brady's guess.
Jessie buys picture frames for $5 each and marks them up 25%. How much profit did he make?
Answers
Answer:
The profit from each picture frame = $1.25
Step-by-step explanation:
The buying price for each picture frame = $5
As Jessie marks them up 25%.
Selling price = 5 + (25% × 5)
= 5 + (0.25 × 5)
= 5 + 1.25
= 6.25
As the selling price of each frame = $6.25
Buying price = $5
Thus, profit = selling price - buying price
= $6.25 - $5
= $1.25
Therefore, the profit from each picture frame = $1.25
Given m|n, find the value of x.
t
m
(9x+23)
(10x+6)°
Someone help?

Answers
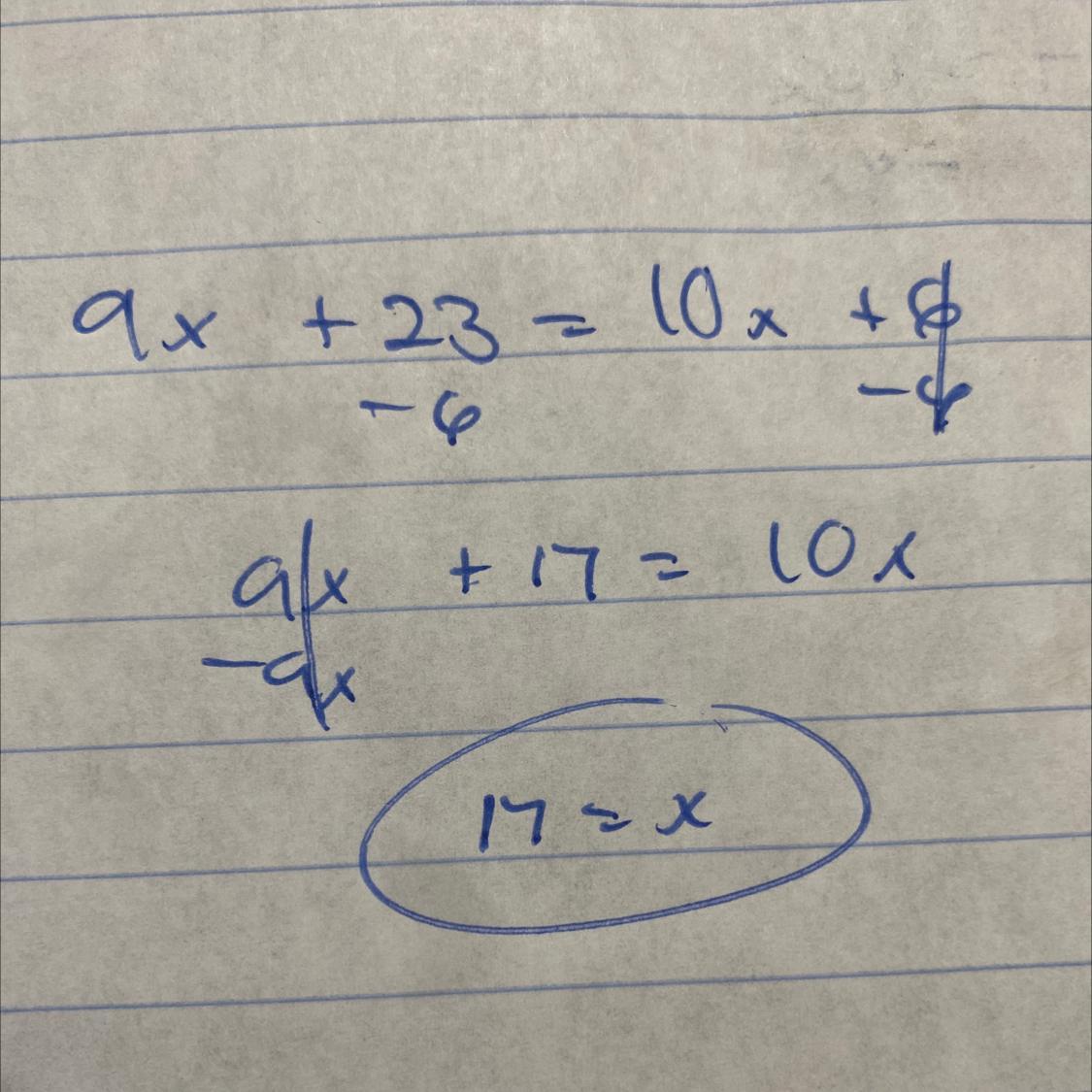
Last week the number of bacteria in a petri dish was 2.25×102. This week the number of bacteria in the petri dish is 2.75×105. How many times more bacteria are in the petri dish this week?
Round the decimal to the nearest tenth.There are
____ × 10____
times more bacteria in the petri dish this week compared to last week.
Answers
Answer:
Step-by-step explanation:
2.75 x 10⁵ ) / (2.25 x 10² )= (2.75 / 2.25) x 10⁵⁻²= 1.2 x 10³ times .(That's 1,200 times as many.)
what is 19.2 x 10^9 minutes in hours ANSWER ASAP PLSS
Answers
Answer:
19200000000
Step-by-step explanation:
1000000000 is 10^9. Then that times 19.2 is 19200000000.
(Hope this helped and have a great day)
(please mark this brainliest)
Wesley wants to run 19 miles this week. If he runs 4.2 miles each day, how many days does he need to run to meet his goal?
Answers
The mileage of Alyssa's car is a measure of how far the car has traveled per unit fuel.The best method and reasoning to calculate the gas mileage is: D. 243.8 miles ÷ 7.71 gallon s
How many days must he run to reach his objective?The mileage of Alyssa's car is a measure of how far the car has traveled per unit fuel.
The best method and reasoning to calculate the gas mileage is:
D. 243.8 miles ÷ 7.71 gallon s
because dividing a quantity with units of miles by a quantity with units of gallons gives a quantity with units of miles per gallon.
The mileage of the car is calculated by dividing the number of miles traveled by the amount of gas used.
mileage
= 243.8 /7.71
From the given parameters;
The unit of miles traveled is miles
The unit of gallons used is gallons
Because the miles traveled is divided by the gallons used, then the unit of the mileage would be miles per gallon
To learn more about mileage refer
https://brainly.com/question/24937565
#SPJ1
A day is a unit of time and cannot be divided into a fraction, Therefore Wesley would need to run for at least 5 days to meet his goal of 19 miles.
How many days Wesley needs to run?To find out how many days Wesley needs to run to meet his goal, we need to divide the total distance he wants to run (19 miles) by the distance he runs each day (4.2 miles):
19 miles ÷ 4.2 miles/day = 4.52 days
Since a day is a unit of time and cannot be divided into a fraction, Wesley would need to run for at least 5 days to meet his goal of 19 miles.
To know more about fraction visit:
https://brainly.com/question/10354322
#SPJ1
the special two-item character sequence that represents special characters like \n is known as a(n) .
Answers
The special two-item character sequence that represents special characters like \n is known as an Escape Sequence. So the option B is correct.
An escape sequence is a sequence of characters that does not represent itself when used inside a character or string literal, but is translated into another character or a sequence of characters. It is used to signal an alternative interpretation of a series of characters. Common examples are the escape sequences used in C/C++ and other programming languages, such as "\n" for newline, "\t" for tab, and "\\" for a backslash. So the option B is correct.
To learn more about Escape Sequence link is here
brainly.com/question/14821549
#SPJ4
The complete question is:
The special two-item character sequence that represents special characters like \n is known as a(n) ?
a. backslash code
b. escape sequence
c. Unicode spec
d. literal character
12 stars / 30 balloons = x / 120 balloons
Answers
Answer: 48 stard
Step-by-step explanation:
12 stars = 30 balloons
? = 120 balloons
Solve
120/30 x 12 = 48
Answer:
48 stars
Step-by-step explanation:
This is an equation where you have to find an equivalent fraction.
So, it is given to us that 12/30 = something (x) /120.
So, what happened to 30 to make it 120 in the respective denominators? It was multiplied by 4.
So, that’s what you do to the numerator, multiply it by 4.
So 12 x 4 = 48.
Now put it back as a fraction 12/30 = 48/120
Roberto' employer offer a liding paid vacation. When he tarted work, he wa given three paid day of vacation. For each ix-month period he tay at the job, hi vacation i increaed by two day. Let x repreent the number of 6-month period worked and y repreent the total number of paid vacation day. Write an equation that mode the relationhip between thee two variable
Answers
An equation that mode the relationship between thee two variable is y=2x+3 .
Let x represent the number of 6-month period worked
Let y represent the total number of paid vacation day
According to the question,
When he started work, he was given three paid day of vacation. For each six-month period he pay at the job, his vacation is increased by two day.
Each year has 2 six-month periods. After 4.4 years Roberto will have worked 8.8 six-month periods. He will have been given vacation days for each of the 8 whole working periods he has completed. x=8 y=2*8+3 y=19
An equation that mode the relationship between thee two variable is y=2x+3 (Total vacation time equals 2 days times x plus the 3 days he was given at the start).
Learn more about linear equations in two variables at :
https://brainly.com/question/24085666
#SPJ4
Please help I need help please

Answers
Step-by-step explanation:
There are 84% out of 225. First find 10%. To do that divide the number by 10, so 225 ÷ 10 = 22.5 Next, do 22.5 x 8. Then you have 80%. Now, all that is need ed is the 4%. To get that, divide 225 by 100. Multiply the answer by 4 to get the 4%. Add the 80% and the 4% to get your answer. I really hope this helps. answers
Also, since I am just helping, I am un able to give you straight answers. I hope this also helps with work in the future.
pls help me!
Find f(1)

Answers
\(f(1) = -6\)
Step-by-step explanation:Given:
\(f(x) = \begin{cases} -(x +5)^2 &\text{for} &x \leqslant -3 \\ -2x -4 &\text{for} &-3 < x \leqslant 1 \\ 5 &\text{for} &x > 1 \end{cases}\)
\(f(1) = -2x -4 \space , \space x = 1 \\ f(1) = -2(1) -4 \\ f(1) = -2 -4 \\ f(1) = -6\)
Relational databases are heavily based on the mathematical concept of: A) Set Theory. B) Bet Theory. C) Get Theory. D) Met Theory.
Answers
Relational databases are heavily based on the mathematical concept of: Set Theory. The correct option is (A).
Relational databases are based on the principles of set theory, which deals with sets of elements and their relationships with each other. In a relational database, data is organized into tables, with each table representing a set of related data.
The tables are then related to each other through the use of keys, which allow for the establishment of relationships between different sets of data. The principles of set theory also govern the use of operations such as union, intersection, and difference, which can be used to manipulate the data in the tables.
Therefore, the mathematical concept of set theory is a fundamental part of the design and use of relational databases.
To know more about "Relational databases" refer here:
https://brainly.com/question/13262352#
#SPJ11
b) Solve
(i)
9x = 36
Answers
Answer:
4
Step-by-step explanation:
Answer:x=4
Step-by-step explanation:
Divide 9 by both sides
Construct a 90% confidence interval for the population mean, μ. Assume the population has a normal distribution. In a recent study of 22 eighth graders, the mean number of hours per week that they watched television was 20.5 with a standard deviation of 4.6 hours.
Answers
The 90% confidence interval for the population mean (µ) is approximately (18.89, 22.11) hours.
To construct a 90% confidence interval for the population mean (µ). We'll be using the information provided: sample size (n) = 22, sample mean (X) = 20.5, and sample standard deviation (s) = 4.6. Since the population has a normal distribution, we can follow these steps:
1. Determine the appropriate z-score for a 90% confidence interval. Using a standard normal distribution table or a calculator, we find that the z-score is 1.645.
2. Calculate the standard error (SE) by dividing the standard deviation (s) by the square root of the sample size (n).
\(SE= \frac{s}{\sqrt{n} } = \frac{4.6}{\sqrt{22} }=0.979\)
3. Multiply the z-score by the standard error to obtain the margin of error (ME). ME = 1.645 × 0.979 ≈ 1.610.
4. Subtract and add the margin of error from the sample mean to find the lower and upper bounds of the confidence interval. Lower bound = X - ME = 20.5 - 1.610 ≈ 18.89. Upper bound = X + ME = 20.5 + 1.610 ≈ 22.11.
So, the 90% confidence interval for the population mean (µ) is approximately (18.89, 22.11) hours.
To know more about "mean" refer here:
https://brainly.com/question/31101410#
#SPJ11
Find the slope of the tangent line to the polar curve r = 2 - sin(0) at the point specified by 0 = "/3. Slope=
Answers
The slope of the tangent line to the polar curve r = 2 - sin(θ) at the point specified by θ = π/3 is -1/2.
To find the slope of the tangent line to the polar curve r = 2 - sin(θ) at the point specified by θ = π/3, we need to first find the derivative of r with respect to θ, and then evaluate it at θ = π/3.
Differentiating both sides of the polar equation with respect to θ, we get:
dr/dθ = d/dθ(2 - sinθ)
dr/dθ = -cosθ
So, the derivative of r with respect to θ is -cosθ.
Evaluating this derivative at θ = π/3, we get:
dr/dθ|θ=π/3 = -cos(π/3) = -1/2
Therefore, the slope of the tangent line to the polar curve r = 2 - sin(θ) at the point specified by θ = π/3 is -1/2.
Learn more about polar curve here:
https://brainly.com/question/28976035
#SPJ11
2.
A policeman took 2 hours to travel 100 miles. What speed was he travelling at?
Answers
Answer:
50 miles per hour!
Step-by-step explanation:
If 2 hours equal 100 miles, then 1 hour will be 50!
Hope this helped!
Answer:
speed = distance ÷ time
speed = 100 ÷ 2 = 50
= 59 mph
Step-by-step explanation:
just did the assignment on the edge
please help me 20 points

Answers
Add up the number of students within the random sample data:
32+26+28+22 = 108
We can then use proportional fractions / cross-multiply to answer the question.
In a sample size of 108 students, 32 of them preferred Movie A.
There are 900 students in total.
\(\frac{32}{108} =\frac{x}{900}\)
32*900 = 28800
108*x = 108x
108x = 28800
x = \(266\frac{2}{3}\) or \(\frac{800}{3}\)
In decimal form that is approximately 266.667 and round that to the nearest whole number, you get 267 students who would prefer Movie A.
What is the area of the composite figure shown?
A) 42.4m2
B) 41.7m2
C) 32.8m2
D) 63m2

Answers
Answer:
B
Step-by-step explanation:
Which statement is true?
Please help

Answers
Ans-6