A 2 liter drink costs $0.15 per deciliter. How much will the drink cost? please i need the answer for a quiz thats due tommarow
Answers
The 2 liter drink would cost $3, we converted liters to deciliters to make sure that we could properly calculate the cost per unit
To calculate the cost of the 2 liter drink, we first need to determine how many deciliters are in 2 liters. Since 1 liter equals 10 deciliters, 2 liters would equal 20 deciliters.
The cost of the drink per deciliter is given as $0.15. To calculate the total cost of the drink, we multiply the cost per deciliter by the total number of deciliters, which is: $0.15/deciliter x 20 deciliters = $3, Therefore, the 2 liter drink would cost $3.
It's important to note that when dealing with units of measurement, it's crucial to ensure that the units are properly converted and consistent. In this case, we converted liters to deciliters to make sure that we could properly calculate the cost per unit (per deciliter).
To Know More about multiply click here
brainly.com/question/25114566
#SPJ11
Related Questions
According to the empirical rule, in a normally distributed set of data, approximately what percent of the scores will be within 1 standard deviation (-1 to +1) away from the mean? 40% 95% 68% 75%
Answers
The answer is approximately 68% of the scores in a normally distributed set of data will fall within one standard deviation (-1 to +1) of the mean, according to the empirical rule.
According to the empirical rule, approximately 68% of the scores in a normally distributed set of data will fall within one standard deviation (i.e., within -1 to +1 standard deviation) of the mean. This is also known as the 68-95-99.7 rule or the three-sigma rule, which states that:
Approximately 68% of the data falls within one standard deviation of the mean. Approximately 95% of the data falls within two standard deviations of the mean. Approximately 99.7% of the data falls within three standard deviations of the mean.
Therefore, the answer to the question is 68%.
To know more about empirical rule:
https://brainly.com/question/30700783
#SPJ4
given two sorted arrays of sizes m and n respectively, design an algorithm that returns the median of the (m n) numbers in these two arrays in o(log(m n)) time.
Answers
To find the median of two sorted arrays of sizes m and n, we need to merge the two arrays into one sorted array and then find the median of that array. However, we can't simply merge the two arrays using a linear approach as it would take O(m+n) time, which doesn't meet the requirement of O(log(m+n)) time. Instead, we can use a binary search algorithm to find the median in O(log(m+n)) time.
The basic idea is to compare the medians of the two arrays and eliminate half of the elements from one or both of the arrays based on their comparison with the median. We keep doing this until we are left with only one or two elements, and then we can easily calculate the median.
Here's how the algorithm works:
1. Initialize two pointers, one for each array, and set their values to the beginning and end of the respective arrays.
2. Calculate the midpoints of the two arrays and compare their values.
3. If the median of the first array is greater than the median of the second array, then we know that the median of the combined array will be in the first half of the first array and the second half of the second array. So we can eliminate the second half of the second array and the first half of the first array by adjusting the pointers accordingly.
4. If the median of the second array is greater than the median of the first array, then we know that the median of the combined array will be in the second half of the first array and the first half of the second array. So we can eliminate the first half of the second array and the second half of the first array by adjusting the pointers accordingly.
5. Repeat steps 2-4 until we are left with only one or two elements.
6. If we are left with one element, then that element is the median. If we are left with two elements, then the median is the average of the two elements.
This algorithm runs in O(log(m+n)) time because we are eliminating half of the elements in each iteration, which results in a logarithmic time complexity.
Learn more about medians here:
https://brainly.com/question/28060453
#SPJ11
given: m||n, angle 1 is congruent to angle 3
prove: k||L
Answers
The complete proof of the parallel lines k and l is:
m || n ⇒ Given∠1 ≅ ∠3 ⇒ alternate interior angle theorem∠1 ≅ ∠3 ⇒ Given∠2 ≅ ∠3 ⇒ Transitive Propertyk || l ⇒ ProvedHow to determine the proof of the anglesThe complete question is added as an attachment
With the given information and the image attached below, we can state that the two lines are parallel
Then go ahead to use the angle theorems and transitive properties to complete the proof
So, the complete proof is:
Statement Reasonm || n ⇒ Given∠1 ≅ ∠3 ⇒ alternate interior angle theorem∠1 ≅ ∠3 ⇒ Given∠2 ≅ ∠3 ⇒ Transitive Propertyk || l ⇒ ProvedRead more about congruence proof at:
brainly.com/question/2102943
#SPJ1

The continuous random variable V has a probability density function given by: 6 f(v) = for 3 ≤ ≤7,0 otherwise. 24 What is the expected value of V? Number
Answers
The expected value of the continuous random variable V is 5. The expected value of V is 5, indicating that, on average, we expect the value of V to be around 5.
To calculate the expected value of a continuous random variable V with a given probability density function (PDF), we integrate the product of V and the PDF over its entire range.
The PDF of V is defined as:
f(v) = 6/24 = 0.25 for 3 ≤ v ≤ 7, and 0 otherwise.
The expected value of V, denoted as E(V), can be calculated as:
E(V) = ∫v * f(v) dv
To find the expected value, we integrate v * f(v) over the range where the PDF is non-zero, which is 3 to 7.
E(V) = ∫v * (0.25) dv, with the limits of integration from 3 to 7.
E(V) = (0.25) * ∫v dv, with the limits of integration from 3 to 7.
E(V) = (0.25) * [(v^2) / 2] evaluated from 3 to 7.
E(V) = (0.25) * [(7^2 / 2) - (3^2 / 2)].
E(V) = (0.25) * [(49 / 2) - (9 / 2)].
E(V) = (0.25) * (40 / 2).
E(V) = (0.25) * 20.
E(V) = 5.
Therefore, the expected value of the continuous random variable V is 5.
The expected value represents the average value or mean of the random variable V. It is the weighted average of all possible values of V, with each value weighted by its corresponding probability. In this case, the expected value of V is 5, indicating that, on average, we expect the value of V to be around 5.
Learn more about random variable here
https://brainly.com/question/17217746
#SPJ11
HELP!
Does the data in the table show a proportional relationship?

Answers
Answer:
No, is the answer. :)
Step-by-step explanation:
Susan will buy 42 comic books from Nathan for $0.75 per comic book. After the purchase, Nathan will have 1,752 comic books left in his collection. Which equation can Nathan use to find w, the number of comic books Nathan originally had in his collection?
Answers
The equation that Nathan can use to find w, the number of comic books Nathan originally had in his collection is w - 42 = 1752.
How to illustrate the equation?From the information, Susan will buy 42 comic books from Nathan for $0.75 per comic book. After the purchase, Nathan will have 1,752 comic books left in his collection.
Let the the number of comic books Nathan originally had in his collection be w.
This will be illustrated as:
w - 42 = 1752
w = 1752 + 42.
w = 1794
He originally had 1794 books.
Learn more about equations on:
brainly.com/question/2972832
#SPJ1
Please help me I am really confused and need help with this.

Answers
Answer:
Step-by-step explanation:
y=10
what are differences or similarities between everyday logic and mathematical logic?
Answers
The main difference between everyday logic and mathematical logic is that everyday logic is based on general observations and opinions, while mathematical logic is based on precise statements and facts.
Differences:
- Everyday logic is based on common sense and intuition, while mathematical logic is based on strict rules and formulas.
- Everyday logic is often used to make decisions or solve problems in daily life, while mathematical logic is used to solve complex mathematical problems.
- Everyday logic can be subjective and influenced by personal beliefs or experiences, while mathematical logic is objective and follows a set of universally accepted principles.
Similarities:
- Both everyday logic and mathematical logic use reasoning to draw conclusions.
- Both everyday logic and mathematical logic rely on evidence and facts to support their conclusions.
- Both everyday logic and mathematical logic can be used to solve problems and make decisions.
In conclusion, while everyday logic and mathematical logic have some similarities in terms of their use of reasoning and evidence, they differ in their approach and application. Everyday logic is based on common sense and intuition, while mathematical logic is based on strict rules and formulas.
Know more about mathematical logic here:
https://brainly.com/question/28052598
#SPJ11
Which exponential function grows at a faster rate than the quadratic function for zero is less than X is less than three
Answers
Answer:
43.35 years
why?
From the above question, we are to find Time t for compound interest
The formula is given as :
t = ln(A/P) / n[ln(1 + r/n)]
A = $2500
P = Principal = $200
R = 6%
n = Compounding frequency = 1
First, convert R as a percent to r as a decimal
r = R/100
r = 6/100
r = 0.06 per year,
Then, solve the equation for t
t = ln(A/P) / n[ln(1 + r/n)]
t = ln(2,500.00/200.00) / ( 1 × [ln(1 + 0.06/1)] )
t = ln(2,500.00/200.00) / ( 1 × [ln(1 + 0.06)] )
t = 43.346 years
(credit to VmariaS)
In 2010, a total of 2187 of the employees at
Leo's company owned a petrol car.
In 2013, there were 1536 employees with
petrol cars.
Assuming this number decreases
exponentially, work out how many employees
owned a petrol car in 2019.
Give your answer to the nearest integer.

Answers
we can expect that approximately 815 employees owned a petrol car in 2019 (rounded to the nearest integer).
How to solve exponential function?We can model the number of employees owning petrol cars in the years 2010 and 2013 using the exponential decay formula:
\($$N(t) = N_0 e^{-kt}$$\)
where N(t) is the number of employees owning petrol cars at time t, \($N_0$\) is the initial number of employees owning petrol cars (in 2010), k is the decay constant, and t is the time elapsed since 2010 (in years).
We can use the given information to find the value of k:
In 2013 (3 years after 2010), the number of employees owning petrol cars decreased from 2187 to 1536:
\($$1536 = 2187 e^{-3k}$$\)
Dividing both sides by 2187 gives:
\($$e^{-3k} = \frac{1536}{2187}$$\)
Taking the natural logarithm of both sides gives:
\($$-3k = \ln\left(\frac{1536}{2187}\right)$$\)
Solving for k gives:
\($k = -\frac{1}{3} \ln\left(\frac{1536}{2187}\right) \approx 0.1565$$\)
Now we can use the exponential decay formula to find the number of employees owning petrol cars in 2019 (9 years after 2010):
\($$N(9) = 2187 e^{-0.1565 \cdot 9} \approx 815$$\)
Therefore, we can expect that approximately 815 employees owned a petrol car in 2019 (rounded to the nearest integer).
To know more about Exponential function visit:
brainly.com/question/14355665
#SPJ1
Please fill in the blank

Answers
Answer: 926
Step-by-step explanation:
1. 920- 444= 476
2. 476+450= 926
3. 926
Answer:926
Step-by-step explanation:because 920 - 444 = 476 + 450 = 926
the manager of a supermarket tracked the amount of time needed for customers to be served by the cashier. after checking with his statistics professor, he concluded that the checkout times are exponentially distributed with a mean of 5.5 minutes. what propotion of customers require more than 12 minutes to check out?
Answers
Approximately 0.357 or 35.7% of customers require more than 12 minutes to check out.
Since the checkout times are exponentially distributed with a mean of 5.5 minutes, we can use the exponential distribution formula to find the probability that a customer will take more than 12 minutes to check out:
P(X > 12) = 1 - P(X ≤ 12)
where X is the checkout time.
To find P(X ≤ 12), we can use the cumulative distribution function (CDF) of the exponential distribution, which is:
F(x) = 1 - e^(-λx)
where λ is the rate parameter of the distribution. For an exponential distribution with mean μ, the rate parameter λ is equal to 1/μ.
So, in our case, λ = 1/5.5 = 0.1818, and we can calculate P(X ≤ 12) as:
P(X ≤ 12) = F(12) = 1 - e^(-0.1818 × 12) ≈ 0.643
Therefore, the probability that a customer will take more than 12 minutes to check out is:
P(X > 12) = 1 - P(X ≤ 12) ≈ 1 - 0.643 ≈ 0.357
To learn more about statistics click on,
https://brainly.com/question/15291758
#SPJ4
Check all of the ordered pairs that satisfy the equation below.
y =
-
O A. (25._)
B. (40, 24)
C. (30, 12)
D. (50,20)
E. (14,35)
F. (10.4)
Answers
sarah is playing a game in which she rolls a number cube 20 times the results are recorded in the chart below. what is the experimental probability of rolling a 1 or a 2? answers 0.3, 0.45, 0.65, 1.25.
Answers
The experimental probability of rolling a 1 or a 2 is 0.2.
Hence, Option A is correct.
We know that,
The experimental probability of an event is defined as the number of times the event occurred divided by the total number of trials.
In this case,
The event is rolling a 1 or a 3,
Which occurred ⇒ 3 + 1
= 4 times.
Given that there are total number of trials = 20.
Therefore,
The experimental probability of rolling a 1 or a 3 = 4/20,
= 1/5
= 0.2
Hence, the required probability is 0.2.
Learn more about the probability visit:
https://brainly.com/question/13604758
#SPJ1
The complete question is:
Sarah is playing a game in which she rolls a number cube 20 times. The results are recorded in the chart below. What is the experimental probability of rolling a 1 or a 3?
Number on cube:1,2,3,4,5,6
Number of times event occurs:3,6,1,5,3,2
A.0.2
B.0.3
C.0.6
D.0.83
I need help again please help thanks

Answers
If p is portional to q and p =4.5 when q= 12 .
Find the relationship between p and q
P when q =16
Q when p= 2.4
Answers
The relationship between variables p and q is given by p = kq. Also, the value of the variable p when q = 16 is 6 and when p = 2.4, the variable q is 6.4.
How to determine the proportional relationship?Mathematically, a proportional relationship can be represented with the following mathematical expression:
p = kq
Where:
p and q are the variables.k represents the constant of proportionality.Next, we would determine the constant of proportionality (k) as follows:
Constant of proportionality (k) = p/q
Constant of proportionality (k) = 4.5/12
Constant of proportionality (k) = 0.375.
When q = 16, the variable p is given by:
p = kq
p = 0.375 × 16
p = 6.
When p = 2.4, the variable q is given by:
q = p/k
q = 2.4/0.375
q = 6.4
Read more on proportionality here: brainly.com/question/12866878
#SPJ1
If the demand equation for a certain commodity is given by the equation: 550p + q = 86,000 where p is the price per unit; at what price is there unitary elasticity? Round your answer off to two decimal places. p =_____________? (1 point)
Answers
By the demand equation for a certain commodity, the price at which there is unitary elasticity is approximately $78.18 per unit
To find the price at which there is unitary elasticity, we need to determine the price (p) when the elasticity of demand is equal to 1.
The elasticity of demand can be calculated using the formula:
E = (dq/dp) x (p/q)
Given the demand equation: 550p + q = 86,000, we can solve for q in terms of p:
q = 86,000 - 550p
Now, we differentiate q with respect to p to find dq/dp:
dq/dp = -550
Substituting these values into the elasticity formula:
1 = (-550) x (p / (86,000 - 550p))
Simplifying the equation:
p = (86,000 - 550p) / 550
Multiplying both sides by 550 to eliminate the denominator:
550p = 86,000 - 550p
Combining like terms:
1100p = 86,000
Dividing both sides by 1100:
p = 78.18
Therefore, the price at which there is unitary elasticity is approximately $78.18 per unit (rounded to two decimal places).
To know more about demand equation follow the link:
https://brainly.com/question/31384304
#SPJ4
Are these equivalent?
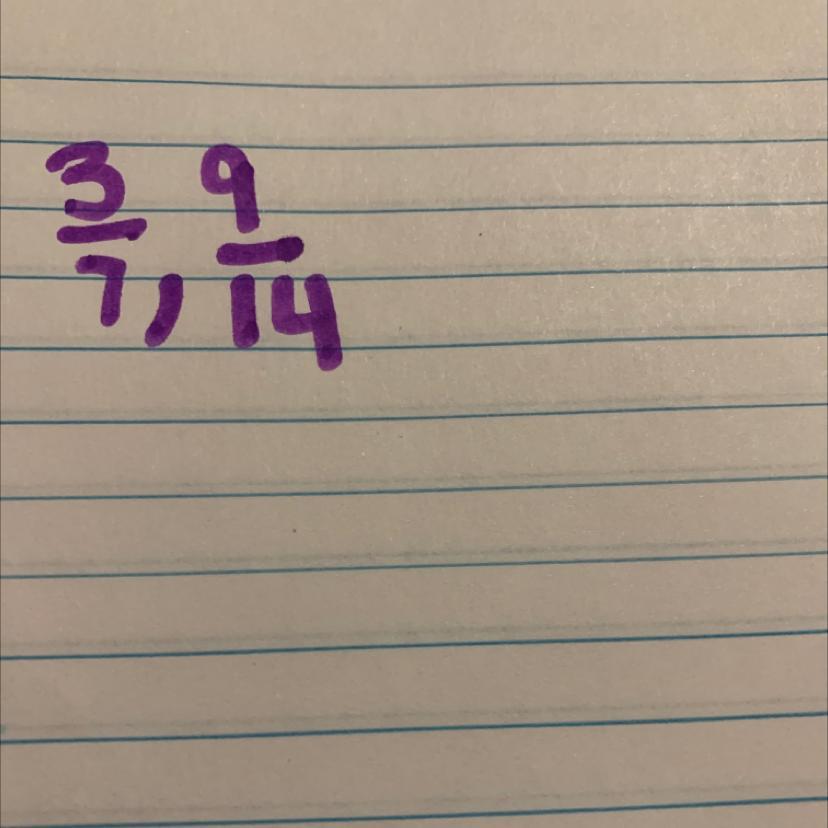
Answers
Answer:
No
Step-by-step explanation:
4 x 2 = 14
BUT
3 x 2 ≠ 9
they are not equal because if is simplify 3/7 you will not get 9/14 you will get 6/14
like this
3|7
6|14
Find the inverse function of f.
f(x) = 7x + 6
f −1(x) =
just put the answer
Answers
The inverse function of f(x) = 7x + 6 is f −1(x) = (x - 6) / 7. This inverse function allows us to obtain the original input value (x) when given the output value (f −1(x)).
To find the inverse function, we need to swap the roles of x and y and solve for y. Let's start with the equation f(x) = 7x + 6:
Step 1: Swap x and y:
x = 7y + 6
Step 2: Solve for y:
x - 6 = 7y
Divide both sides by 7:
(x - 6) / 7 = y
Step 3: Replace y with f −1(x):
f −1(x) = (x - 6) / 7
The resulting equation, f −1(x) = (x - 6) / 7, is the inverse function of f(x) = 7x + 6. It allows us to retrieve the original input value (x) when given the output value (f −1(x)). The inverse function "undoes" the actions of the original function, reversing the calculations performed by f(x).
Learn more about function here:
https://brainly.com/question/30721594
#SPJ11
Please help! (look at the image below!!)

Answers
The numbers arranged in order from least to greatest is: √146, 12.39, 12.62, 12⅝, and 12¾. The third option is correct.
What is ordering of numbersThe ordering of numbers refers to arranging numbers in a specific sequence based on their magnitude or value. The ordering of numbers is determined by their relative values. Comparisons are made between numbers to determine their position in the order.
12⅝ = 101/8 = 12.645
12.62 = 12.62
√146 = 12.0830
12.39 = 12.39
12¾ = 51/4 = 12.75
Therefore, the numbers arranged in order from least to greatest is: √146, 12.39, 12.62, 12⅝, and 12¾.
Read more about numbers here:https://brainly.com/question/1094377
#SPJ1
PLZZ HELP ME!!!
ANY LINKS WILL BE REPORTED
Find the volume of this object.

Answers
Answer:
24 will be your answer.
Step-by-step explanation:
NEED ASNSWER ASAP. The ratio of sugar to flour in a brownie recipe is 8:5. Kimo used 15 ounces of flour. How many ounces of sugar did Kimo use?
Answers
Answer:
5
Step-by-step explanation:
\(8:5=15:x\\8*x=15\\(8*x)/8=15/8\\x=1.875\\\\\frac{8}{5} *1.875=\frac{15}{x} \\\frac{8}{5} *1.875=3\\3=\frac{15}{x}\\x=5\)
Please help will give brainliest.

Answers
Answer:
1st and 3rd options
Step-by-step explanation:
substitute the coordinates of each point into the left side and compare answer to right side.
(0, 2 )
2(2) - 0 = 4 - 0 = 4 > 1 ← solution
(8, \(\frac{1}{2}\) )
2(\(\frac{1}{2}\) ) - 8 = 1 - 8 = - 7 < 1 ← not a solution
(- 6, 3 )
2(3) - (- 6) = 6 + 6 = 12 > 1 ← solution
(- 7, - 3 )
2(- 3) - (- 7) = - 6 + 7 = 1 ← not a solution
Plz, help me!!!
How many solutions does the system of equations have?

Answers
Answer:
1 solution: x = 1 and y = 4
Im du.mb at this stuff, i dont know how to do it

Answers
Answer:
the correct answer will be 88
Answer:
Area of the shaded region 45.76 cm².
Step-by-step explanation:
Firstly, finding the area of rectangle by substituting the values in the formula :
\({\longrightarrow{\pmb{\sf{A_{(Rectangle)} = l \times b}}}}\)
→ A = Area→ l = length → b = breadth\(\begin{gathered} \qquad{\longrightarrow{\sf{A_{(Rectangle)} = l \times b}}}\\\\\qquad{\longrightarrow{\sf{A_{(Rectangle)} = 12\times 8}}}\\\\\qquad{\longrightarrow{\sf{A_{(Rectangle)} = 96}}}\\\\\qquad{\star{\boxed{\sf{\pink{A_{(Rectangle)} = 96 \: {cm}^{2}}}}}} \end{gathered}\)
Hence, the area of rectangle is 96 cm².
\(\rule{200}2\)
Secondly, finding the area of circle by substituting the values in the formula :
\({\longrightarrow{\pmb{\sf{A_{(Circle)} = \pi{r}^{2}}}}}\)
→ A = Area → π = 3.14 → r = radius\(\begin{gathered} \qquad{\longrightarrow{\sf{A_{(Circle)} = \pi{r}^{2}}}} \\ \\ \qquad{\longrightarrow{\sf{A_{(Circle)} = 3.14{(4)}^{2}}}} \\ \\ \qquad{\longrightarrow{\sf{A_{(Circle)} = 3.14{(4\times 4)}}}} \\ \\ \qquad{\longrightarrow{\sf{A_{(Circle)} = 3.14(16)}}} \\ \\ \qquad{\longrightarrow{\sf{A_{(Circle)} = 3.14 \times 16}}} \\ \\ \qquad{\longrightarrow{\sf{A_{(Circle)} \approx 50.24}}} \\ \\ \qquad{\star{\boxed{\sf{\purple{A_{(Circle)} \approx 50.24 \: {cm}^{2}}}}}} \end{gathered}\)
Hence, the area of circle is 50.24 cm².
\(\rule{200}2\)
Now, finding the area of shaded region by substituting the values in the formula :
\(\longrightarrow{\pmb{\sf{A_{(Shaded)} = A_{(Rectangle)} - A_{(Circle)}}}}\)
→ A = Area→ Rectangle → Circle\(\begin{gathered}{\quad{\longrightarrow{\sf{A_{(Shaded)} = A_{(Rectangle)} - A_{(Circle)}}}}}\\\\{\quad{\longrightarrow{\sf{A_{(Shaded)} = 96 - 50.24}}}}\\\\{\quad{\longrightarrow{\sf{A_{(Shaded)} \approx 45.76}}}}\\\\{\quad{\star{\boxed{\sf{\red{A_{(Shaded)} \approx 45.76 \: {cm}^{2}}}}}}} \end{gathered}\)
Hence, the area of shaded region is 45.76 cm².
\(\rule{300}{2.5}\)
How many different 7-place license plates are possible if the first 2 places are for letters and the other 5 for numbers probability?
Answers
The total number of possible 7-place license plates are 67600000.
Given: A 7-plate license plate. 2 places are for letters and 5 places are for numbers. To find how many different 7-plate license plates are possible
Let's solve the given problem:
The license plate has 7 places. 2 places are for letters and the remaining 5 places are for numbers.
Combination of letters: As there are no restrictions given in the question, so the first letter can be any alphabet out of the 26 alphabets (A, B, C, D, ......... Z). So the first place for the letter can be filled in ²⁶C₁ ways that are 26 ways. Also for the second place, as the letters can repeat so it can be filled in ²⁶C₁ ways too which are 26 ways. Therefore, the possible ways in which the place for two letters can be filled is 26 × 26 ways = 676 ways.Combination of numbers: As there are no restrictions given in the question so the first number can be any of the numbers out of the 10 numbers (10, 1, 2, 3, ....... 9). So the first number can be filled in ¹⁰C₁ = 10 ways. Similarly, as the numbers can repeat so the 2nd, 3rd, 4th and 5th numbers can be filled in ¹⁰C₁ ways that all the other places can be filled in 10 ways each. Therefore the total number of ways in which the place for 5 numbers can be filled is 10 × 10 × 10 × 10 × 10 ways = 100000 ways.Therefore, the total number of ways in which the 7-place license plate can fill are: Total possible ways in which the two letters can be filled × Total possible ways in which the 5 number places can be filled
= 676 × 100000
= 67600000 ways
Hence the total number of possible 7-place license plates are 67600000.
Know more about "permutations and combinations" here: https://brainly.com/question/13387529
#SPJ6
On a coordinate plane, triangle R S T has points (negative 5, 6), (3, 4), and (negative 2, 2). Which expression can be used to find the area of triangle RST? (8 ∙ 4) - One-half (10 12 16) (8 ∙ 4) - (10 12 16) (8 ∙ 4) - One-half (5 6 8) (8 ∙ 4) - (5 - 6 - 8).
Answers
Answer:
Step-by-step explanation:
its D, (8 x 4)-(5-6-8)
Please help I’ll give brainlieast

Answers
Answer:
Top one is A, then false, then C
Step-by-step explanation:
Ez
Find the area of the following figures (2/2)

Answers
The Total surface area of each given figure are:
g) 165 in²
h) 869 in²
i) 1146.57 ft²
j) 400 m²
How to find the surface area?g) The area of a triangle is given by the formula:
Area = ¹/₂ * base * height
Area of left triangle = ¹/₂ * 10 * 8 = 40 in²
Area of right triangle = ¹/₂ * 10 * 25 = 125 in²
Total surface area = 40 in² + 125 in²
Total surface area = 165 in²
h) This will be a total of the trapezium area and triangle area to get:
Total surface area = (¹/₂ * 22 * 19) + (¹/₂(22 + 38) * 22)
Total surface area = 209 + 660
Total surface area = 869 in²
i) Total surface area is:
T.S.A = (50 * 30) - ¹/₂(π * 15²)
T.S.A = 1146.57 ft²
j) Total surface area is:
TSA = 20 * 20 (This is because the removed semi circle is equal to the additional one and when we add it back to the square, it becomes a complete square)
TSA = 400 m²
Read more about Surface Area at: https://brainly.com/question/16519513
#SPJ1
Consider a population that consists of the 55 students enrolled in a statistics course at a large university. If the university registrar were to compile the grade point averages (GPAs) of all 55 students in the course and compute their average, the result would be a mean GPA of 3. 15. Note that this average is unknown to anyone; to collect the GPA information would violate the confidentiality of the students’ academic records.
Suppose that the professor who teaches the course wants to know the mean GPA of the students enrolled in his course. He selects a sample of students who are in attendance on the third day of class. The GPAs of the students in the sample are:
3. 89 4. 00 3. 85 3. 77 3. 81 3. 43 3. 28 3. 27 3. 56 3. 92
The instructor uses the sample average as an estimate of the mean GPA of his students. The absolute value of the error in the instructor’s estimate is:
a. 0. 53
b. 0. 22
c. 0. 52
d. 0. 14
Answers
The absolute value of the error in the instructor's estimate is 0.644.
To find the absolute value of the error in the instructor's estimate, we need to calculate the difference between the sample mean and the population mean.
Given:
Population mean (μ) = 3.15
Sample mean (\(\bar{X}\)) = (3.89 + 4.00 + 3.85 + 3.77 + 3.81 + 3.43 + 3.28 + 3.27 + 3.56 + 3.92) / 10
= 36.78/10
= 3.678
Absolute value of the error = |\(\bar{X}\) - μ|
|\(\bar{X}\) - μ| = |3.678 - 3.15| = 0.528
Therefore, the absolute value of the error in the instructor's estimate is 0.644.
Learn more about Mean here
https://brainly.com/question/31101410
#SPJ4