A punter kicks the football 40{~m}(-44{yards}) and it takes 4.1{sec} from the kick to the catch. How fast does the ball move in the horizontal direction right after
Answers
The ball moves at an average speed of approximately 9.76 meters per second (10.66 yards per second) in the horizontal direction right after the kick.
To calculate the speed of the ball in the horizontal direction, we can use the formula: speed = distance / time. The distance kicked by the punter is given as 40 meters (44 yards), and the time taken for the ball to travel from the kick to the catch is given as 4.1 seconds. Dividing the distance by the time, we get an average speed of approximately 9.76 meters per second (10.66 yards per second) in the horizontal direction.
This speed represents the ball's velocity solely in the horizontal direction, disregarding any vertical motion or acceleration due to external factors like air resistance. It implies that immediately after the kick, assuming a straight path, the ball maintains a constant horizontal speed of around 9.76 meters per second (10.66 yards per second) until it is caught.
Learn more about average speed: brainly.com/question/4931057
#SPJ11
Related Questions
20 points!
Which word best describes the degree of overlap between the two data sets?
moderate
low
none
high

Answers
please help will mark brainliest

Answers
Answer:
A. (-4,2)
Step-by-step explanation:
A ________ is the value of a statistic that estimates the value of a parameter a critical value b standard error c. level of confidence d point estimate Question 2 Mu is used to estimate X True False Question 3 Beta is used to estimate p True False
Answers
A point estimate is the value of a statistic that estimates the value of a parameter. Question 2 is false and question 3 is true.
Question 1: A point estimate is the value of a statistic that estimates the value of a parameter.A point estimate is a single number that is used to estimate the value of an unknown parameter of a population, such as a population mean or proportion
Question 2: False
Mu (μ) is not used to estimate X. Mu represents the population mean, while X represents the sample mean. The sample mean, X, is used as an estimate of the population mean, μ.
Question 3: True
Beta (β) is indeed used to estimate the population proportion (p) when conducting hypothesis testing on a sample. Beta represents the probability of making a Type II error, which occurs when we fail to reject a null hypothesis that is actually false. By calculating the probability of a Type II error, we indirectly estimate the population proportion, p, under certain conditions and assumptions.
Learn more about point estimate at:
brainly.com/question/30310597
#SPJ11
Which expression represents the length of QR?
Answers
Answer:
jsjdkfnfnfkdkfkfkfkidkffbgngngkgk
Is length 25 inches and the width 2 inches 50 inches
Answers
Answer:
if it is the area your talking about, but if it is the perimeter its 54
Step-by-step explanation:
Guided Practice
Determine whether the function rule models discrete data, continuous data, or neither.
A hardware store sells bolts for $.35 apiece. The function C(p) = 0.35p relates the total cost of the bolts to the number p purchased.
A.
neither
B.
continuous data
C.
discrete data
Answers
Answer:
C.
discrete data
Step-by-step explanation:
The given function is:
C(p) = 0.95p
Where p represents the number of bolts purchased. We can calculate the cost based on the number of bolts purchased.
An important distinction between discrete and continuous data is that the continuous data is measured while discrete data is calculated or counted. Since we are obtaining the data by calculation, it must be discrete data.
The function can take on only specific values. For example for p=0, C is 0 and for p=1 the value of C is 0.95. The function cannot take any value in between 0 and 0.95. This is a characteristic of discrete function. A continuous function can take all possible values in an interval.
Therefore, the answer to this question is: The Function models discrete data.
Exercise 11. 3. 1: Applying the pigeonhole principle - heights and times. About Apply the pigeonhole principle to answer the following questions. If the pigeonhole principle can not be applied, give a specific counterexample. (a) A team of three high jumpers all have a personal record that is at least 6 feet and less than 7 feet. Is it necessarily true that two of the team members must have personal records that are within four inches of each other
Answers
To apply the pigeonhole principle, we need to determine the number of pigeonholes and the number of pigeons. The pigeonhole principle cannot be applied to this question.
In this case, the" holes" are the high minidresses and the" lockers" are the ranges of particular records. Let's assume that the range of particular records is from 6 bases( 72 elevation) to 7 bases( 84 elevation). The difference between the upper and lower bounds of the range is
84- 72 = 12 elevation.
We can divide this range into five subintervals of length2.4 elevation( 72,74.4),(74.4,76.8),(76.8,79.2),(79.2,81.6), and(81.6, 84).
Since there are only five subintervals, but we've three high minidresses, it isn't inescapably true that two of the platoon members must have particular records that are within four elevation of each other. For illustration, if the three high minidresses have particular records of 6 bases 3 elevation( 75 elevation), 6 bases 7 elevation( 79 elevation), and 7 bases( 84 elevation), also none of them have particular records within four elevation of each other.
Learn more about pigeonhole principle at
https://brainly.com/question/29242775
#SPJ4
The probability of a student spending time reading is 0.59, and the probability of a student doing well on an exam and spending time reading is 0.58. What is the probability of a student doing well on an exam given that the student spends time reading
Answers
The probability of a student doing well on an exam given that they spend time reading is approximately 0.983 or 98.3%.
To calculate the probability of a student doing well on an exam given that the student spends time reading, we need to use conditional probability.
Let's denote:
P(R) as the probability of a student spending time reading (P(R) = 0.59),
P(E) as the probability of a student doing well on an exam (P(E)),
P(E|R) as the probability of a student doing well on an exam given that they spend time reading (P(E|R) = 0.58).
The formula for conditional probability is:
P(E|R) = P(E and R) / P(R).
Given that P(E and R) = 0.58 (the probability of a student doing well on an exam and spending time reading) and P(R) = 0.59 (the probability of a student spending time reading), we can substitute these values into the formula:
P(E|R) = 0.58 / 0.59 = 0.983.
Therefore, the probability of a student doing well on an exam given that the student spends time reading is approximately 0.983 or 98.3%.
To know more about probability, visit:
https://brainly.com/question/29120105
#SPJ11
Please help me on this question. First to answer will be the brainliest :D
Solve for t.
6t - 7 = 7t
Answers
Answer:
t=−7
Step-by-step explanation:
FIRST
Mr. rosario is preparing a 12.4 pound veal roast for 16 guests. if each serving is about the same, how much veal roast will each guest receive?
Answers
Each guest receive 352 gm veal roast.
What is a pound used to measure?The pound is a unit of measurement used in the U. S. customary system and the British imperial system to measure weight. One familiar use of pounds is measuring how much a person weights.
We know that,
1 pound = 453.592 gm
12.4 pound = ? gm
12.4 pound = 12.4×453.592
= 5624.541 gm
Total number of guest = 16
Then,
Each guest receive veal roast = \(\frac{5624.541 gm}{16}\)
= 352 gm
Hence, Each guest receive veal roast is 352 gm.
To learn more about pound from the given link:
https://brainly.com/question/25973294
#SPJ4
Will mark brainliest!plz help
EXTRA POINTS!
Answer both questions...
Scientists discovered the ozone layer was depleting at a rapid rate. At the beginning of the study the ozone layer was 3 millimeters thick. Throughout the study it depleted at a rate of 0.04 Millimeters per week.
Which function can be used to find the thickness of the ozone layer in meteres x days sconce the study ?
A) T(x)=-0.04(x+3)
B) T(x)=0.04(x+3)
C) T(x)=0.04x+3
D) T(x)=-0.04x+3

Answers
Answer:
1. D
2. D
Step-by-step explanation:
Answer:
i thinks it's D im not so sure but i think it's D
Hana i planning a park day for the next month to give her friend ome exercie! The local park open it path for biker every 12 day and open it’ lake for paddling every 8 day. Today, both the biking and paddling option are open. Which two number entence will help Hana pick the next date where both the bike lane and lake padding will be open?
Answers
If a local park is open for biking every 12 day open for paddling every 8 day and if today the park is open for both options, then the next date when the park will be open will be on the 24th day. So Hana should pick 24th day from today next.
Every 12 day the local park is open its path for biking and every 8 day they open their lake or paddling. That is in every multiple of 12 days the biking option is available and every multiple of 8 days the paddling option is available.
If today both the biking and paddling option are open, then the next day where both options will be open can be determined by calculating the least common multiple of 12 and 8.
12 = 2×2×3
8 = 2×2×2
LCM (12, 8) = 2×2×2×3
LCM(12, 8) = 24
LCM of 12 and 8 is 24. So 24 days from today, the park will be open for both options.
To know more on LCM
https://brainly.com/question/20739723
#SPJ4
Find the abscissa on the curve x2=2y which is nearest
to a
point (4, 1).
Answers
The abscissa on the curve x^2 = 2y which is nearest to the point (4,1) is x = √(3/8).
Given the equation x^2 = 2y.
The coordinates of the point are (4,1).We have to find the abscissa on the curve that is nearest to this point.So, let's solve this question:
To find the abscissa on the curve x2 = 2y which is nearest to the point (4,1), we need to apply the distance formula.In terms of x, the formula for the distance between a point on the curve and (4,1) can be written as:√[(x - 4)^2 + (y - 1)^2]But since x^2 = 2y, we can substitute 2x^2 for y:√[(x - 4)^2 + (2x^2 - 1)^2].
Now we need to find the value of x that will minimize this expression.
We can do this by finding the critical point of the function: f(x) = √[(x - 4)^2 + (2x^2 - 1)^2]To do this, we take the derivative of f(x) and set it equal to zero: f '(x) = (x - 4) / √[(x - 4)^2 + (2x^2 - 1)^2] + 4x(2x^2 - 1) / √[(x - 4)^2 + (2x^2 - 1)^2] = 0.
Now we can solve for x by simplifying this equation: (x - 4) + 4x(2x^2 - 1) = 0x - 4 + 8x^3 - 4x = 0x (8x^2 - 3) = 4x = √(3/8)The abscissa on the curve x^2 = 2y that is nearest to the point (4,1) is x = √(3/8).T
he main answer is that the abscissa on the curve x^2 = 2y which is nearest to the point (4,1) is x = √(3/8).
The abscissa on the curve x^2 = 2y which is nearest to the point (4,1) is x = √(3/8).
To know more about abscissa visit:
brainly.com/question/32034993
#SPJ11
ahah can someone help like fr- I hate school ☝

Answers
Answer:
Reflection
Step-by-step explanation:
Reflection since they are congruent, and just flipping it would bring one triangle perfectly on to the other.
I sympathize with you on the school issue. :P Hope that helps!
Answer:
Translation
Step-by-step explanation:
1+2-5*67-8
Need it now please
Answers
Answer:
-340
Step-by-step explanation:
Hey there!
1 + 2 - 5 * 67 - 8
= 3 - 5 * 67 - 8
= 3 - 335 - 8
= -332 - 8
= -340
Therefore, your answer is: -340
Good luck on your assignment & enjoy your day!
~Amphitrite1040:)
On Tuesday, the number of orange cakes Aadil needs in his sample is 5 correct to the nearest whole number. Aadil takes at random a cake from the 750 cakes made on Tuesday. b) What is the lower bound of the probability that the cake is an orange cake, giving your answer as a decimal?
Answers
Answer:
A) 210 B) 0.18
Step-by-step explanation:
got it right
assume the weight of a randomly chosen american passenger car is a uniformly distributed random variable ranging from 1,568 pounds to 4,980 pounds.
Answers
The weight of a randomly chosen American passenger car is assumed to be uniformly distributed between 1,568 pounds and 4,980 pounds. This means that any weight within this range is equally likely to be chosen.
In this scenario, the weight of a randomly chosen American passenger car is modeled as a uniformly distributed random variable. A uniform distribution is characterized by a constant probability density function within a specific range. In this case, the range is defined as 1,568 pounds to 4,980 pounds.
A uniform distribution implies that each weight within the given range has an equal probability of being selected. This means that a car weighing 1,568 pounds has the same likelihood of being chosen as a car weighing 4,980 pounds. The distribution is "uniform" because the probability is evenly spread across the entire range.
By assuming a uniformly distributed random variable for the weight of American passenger cars, we can make predictions and analyze various statistical properties. For example, we can calculate the probability of a car weighing within a certain range or estimate the average weight of randomly chosen cars. This assumption provides a simple and convenient model for understanding the weight distribution of American passenger cars in a probabilistic framework.
Learn more about weight here:
https://brainly.com/question/31659519
#SPJ11
suppose the covariance between x1 and x2 is 3, the covariance between x1 and x3 is 2, and the covariance between x2 and x3 is 1. also suppose the standard deviations of x1, x2, and x3 are 3, 2, and 2, respectively. calculate the covariance matrix and the correlation matrix.
Answers
To calculate the covariance matrix and the correlation matrix, we need to arrange the covariances and standard deviations in a matrix form.
Let's denote the covariance matrix as C and the correlation matrix as R.
The covariance matrix C is given by:
C = [cov(x1, x1) cov(x1, x2) cov(x1, x3)]
[cov(x2, x1) cov(x2, x2) cov(x2, x3)]
[cov(x3, x1) cov(x3, x2) cov(x3, x3)]
The correlation matrix R is calculated by dividing each covariance by the product of the corresponding standard deviations:
R = [cov(x1, x1)/(σ1 * σ1) cov(x1, x2)/(σ1 * σ2) cov(x1, x3)/(σ1 * σ3)]
[cov(x2, x1)/(σ2 * σ1) cov(x2, x2)/(σ2 * σ2) cov(x2, x3)/(σ2 * σ3)]
[cov(x3, x1)/(σ3 * σ1) cov(x3, x2)/(σ3 * σ2) cov(x3, x3)/(σ3 * σ3)]
Now, let's substitute the given values into the formulas:
C = [cov(x1, x1) cov(x1, x2) cov(x1, x3)]
[cov(x2, x1) cov(x2, x2) cov(x2, x3)]
[cov(x3, x1) cov(x3, x2) cov(x3, x3)]
C = [cov(x1, x1) 3 2]
[3 cov(x2, x2) 1]
[2 1 cov(x3, x3)]
R = [cov(x1, x1)/(σ1 * σ1) cov(x1, x2)/(σ1 * σ2) cov(x1, x3)/(σ1 * σ3)]
[cov(x2, x1)/(σ2 * σ1) cov(x2, x2)/(σ2 * σ2) cov(x2, x3)/(σ2 * σ3)]
[cov(x3, x1)/(σ3 * σ1) cov(x3, x2)/(σ3 * σ2) cov(x3, x3)/(σ3 * σ3)]
R = [cov(x1, x1)/(3 * 3) cov(x1, x2)/(3 * 2) cov(x1, x3)/(3 * 2)]
[cov(x2, x1)/(2 * 3) cov(x2, x2)/(2 * 2) cov(x2, x3)/(2 * 2)]
[cov(x3, x1)/(2 * 3) cov(x3, x2)/(2 * 2) cov(x3, x3)/(2 * 2)]
Simplifying further:
C = [cov(x1, x1) 3 2]
[3 cov(x2, x2) 1]
[2 1 cov(x3, x3)]
R = [cov(x1, x1)/9 cov(x1, x2)/6 cov(x1, x3)/6]
[cov(x2, x1)/6 cov(x2, x2)/4 cov(x2, x3)/4]
[cov(x3, x1)/6 cov(x3, x2)/4 cov(x3, x3)/4]
Now, let's substitute the given covariance values into the matrices:
C = [cov(x1, x1) 3 2]
[3 cov(x2, x2) 1]
[2 1 cov(x3, x3)]
R = [cov(x1, x1)/9 cov(x1, x2)/6 cov(x1, x3)/6]
[cov(x2, x1)/6 cov(x2, x2)/4 cov(x2, x3)/4]
[cov(x3, x1)/6 cov(x3, x2)/4 cov(x3, x3)/4]
We don't have the exact values for cov(x1, x1), cov(x2, x2), and cov(x3, x3), so we cannot calculate the specific covariance matrix and correlation matrix. However, you can substitute the respective covariance values to obtain the final matrices.
Learn more about covariance matrix here : brainly.com/question/30697803
#SPJ11
1) Jerry put $20,000 in a savings account paying 8% annual interest
compounded monthly. At this rate how much money will be saved in th
account after 10 years?
Answers
Putting $20,000 at 8% annual interest & monthly getting compounded , the amount of money that jerry will after 10 years is approximately $44,040.
Given :
present value (P) = $20,000
interest rate (r) = 8%
compounding monthly (n) = 12
Time (t) = 10 years
To find : Future value after 10 years when interest monthly gets compounded
Now,
we know the formula is
future value = present value × (1 + interest rate)^years
= P × ( 1 + r / n )^ nt
inserting values in the given formula we get,
future value = $20,000 × ( 1 + 8% / 12 )^ 10 × 12
= $20,000 × ( 1 + 8 / 1200 )^ 120
= $20,000 × (1 + 0.0066)^120
= $20,000 × ( 1.0066)^120
= $20,000 × 2.2020
= $44,040
Hence the amount saved by jerry after 10 years at the annual interest of 8% when money monthly is getting compounded with $20.000 will be $44,040.
Learn more about interest getting compounded at different rates & times here
https://brainly.com/question/24924853
#SPJ9
plz help me with math :)

Answers
Answer:
it would be 3 in the first box and 24 in the other
Step-by-step explanation:
because the ratio is 3 years to 24 montsh most of the time the larger number is on the left and the smaller number is on the right and 3 years is more than 24 months 24 months is only two years
Adrianna's skateboard weighs 5 pounds and their motorcycle weighs 156 times as much. How much does the motorcycle weigh?
A. 680 pounds
B. 780 pounds
Adrianna loads their skateboard on a trailer that weighs 234 pounds.
What is the total weight of the trailer and skateboard in ounces?
____ ounces(s)
Answers
The total weight of the Motorcycle Weight trailer and skateboard is 3824 ounces.
To find the weight of the motorcycle, we can multiply the weight of the skateboard by 156.
Weight of the motorcycle = Weight of the skateboard * 156
Weight of the motorcycle = 5 pounds * 156
Weight of the motorcycle = 780 pounds
Therefore, the motorcycle weighs 780 pounds.
To find the total weight of the trailer and skateboard in ounces, we need to convert pounds to ounces. There are 16 ounces in 1 pound.
Weight of the trailer = 234 pounds * 16 ounces/pound
Weight of the trailer = 3744 ounces
Weight of the skateboard = 5 pounds * 16 ounces/pound
Weight of the skateboard = 80 ounces
Total weight of the trailer and skateboard = Weight of the trailer + Weight of the skateboard
Total weight of the trailer and skateboard = 3744 ounces + 80 ounces
Total weight of the trailer and skateboard = 3824 ounces
Therefore, the total weight of the Motorcycle Weight trailer and skateboard is 3824 ounces.
For such more questions on Motorcycle Weight
https://brainly.com/question/30666109
#SPJ8
Use the Properties of Equality to solve each equation
A - 6 = 19
A. 25
B.13
C.-13
D. -25
Answers
+6 +6
a= 25
the answer is A. 25
Answer:
A-6 =19
A= 19+6
A= 25
what will increase the width of a confidence interval? increase confidence level. b) increase number in sample c) decrease confidence level. d) decrease variance
Answers
Increasing the width of a confidence interval can be achieved by:
a) Increasing the confidence level: A higher confidence level requires a wider interval to capture the true population parameter with greater certainty.
b) Decreasing the number in the sample: A smaller sample size results in less precision and a wider confidence interval due to increased sampling variability.
c) Increasing the variance: A larger variance implies greater dispersion in the data, which requires a wider confidence interval to accommodate the increased uncertainty.
Learn more about dispersion here:
https://brainly.com/question/13995700
#SPJ11
Increasing the confidence level or decreasing the sample size would increase the width of a confidence interval. c
Conversely, decreasing the confidence level or increasing the sample size would decrease the width of the confidence interval.
Decreasing the variance of the data would also decrease the width of the confidence interval.
As it would make the data points more tightly clustered around the mean, reducing the uncertainty of the estimate.
On the other hand, a smaller confidence level or a larger sample size would result in a narrower confidence interval.
The breadth of the confidence interval would be reduced if the data's volatility was reduced.
The data points would become more closely packed around the mean, lowering the estimate's level of uncertainty.
For similar questions on interval
https://brainly.com/question/30354015
#SPJ11
by the definition of supplementary angles, the base angles of the top isosceles triangle have the measure of

Answers
Answer:
128
Step-by-step explanation:
Top Triangle
Let the base angles of the top triangle = y
y + 102 = 180
y = 78
The vertex
Is found by adding the two base angles together and subtract that from 180
y + y + vertex = 180
78 + 78 + vertex = 180
156 + vertex = 180
vertex = 180 - 156
vertex = 24 degrees
Bottom Triangle
Because the base angles are connected by a vertically opposite angle on the bottom triangle, both base angles are 26
Therefore 26 + 26 + x = 180
52 + x = 180
x = 180 - 52
x = 128
64 cm
64 cm
48°
*nor drawn to scale
What is the value of x?
o
A. 42°
B. 48°
Ο Ο Ο
C 64°
O D. 84
URGENT PLS I WILL GIVE MAX POINTS PLEASE

Answers
Answer: D
Step-by-step explanation:
My Teacher gave me the answer
The two non-parallel sides of an isosceles trapezoid are each 7 feet long. The longer of the two bases measures 22 feet long. The sum of the base angles is 140°.Show all your work and explain how you arrived at your answer. Round answers to the nearest hundredth.
Answers
the length of diagonal BD is approximately 11.49 feet.
Let's label the isosceles trapezoid as ABCD, where AB is the longer base and CD is the shorter base. We know that AB = 22 feet and the non-parallel sides (BC and AD) are each 7 feet long.
Since ABCD is an isosceles trapezoid, we know that the base angles (the angles formed by the longer base and each of the non-parallel sides) are congruent. Let's label each of these angles as x.
We also know that the sum of the base angles of a trapezoid is 360°. Since ABCD is an isosceles trapezoid with two congruent base angles and a sum of 140°, we can set up an equation:
2x + 140° = 360°
Subtracting 140° from both sides, we get:
2x = 220°
Dividing by 2, we get:
x = 110°
So each base angle of ABCD measures 110°.
Now we can use the law of cosines to find the length of the diagonal BD. Let's label the intersection of the diagonals as point E, and the length of BD as d. Then we have:
d^2 = 7^2 + 7^2 - 2(7)(7)cos(110°)
Simplifying, we get:
d^2 = 98 - 98cos(110°)
Using a calculator, we find that cos(110°) is approximately -0.34202. Substituting this value, we get:
d^2 = 98 - 98(-0.34202)
Simplifying, we get:
d^2 ≈ 131.88
Taking the square root of both sides, we get:
d ≈ 11.49
To learn more about angle visit:
brainly.com/question/28451077
#SPJ11
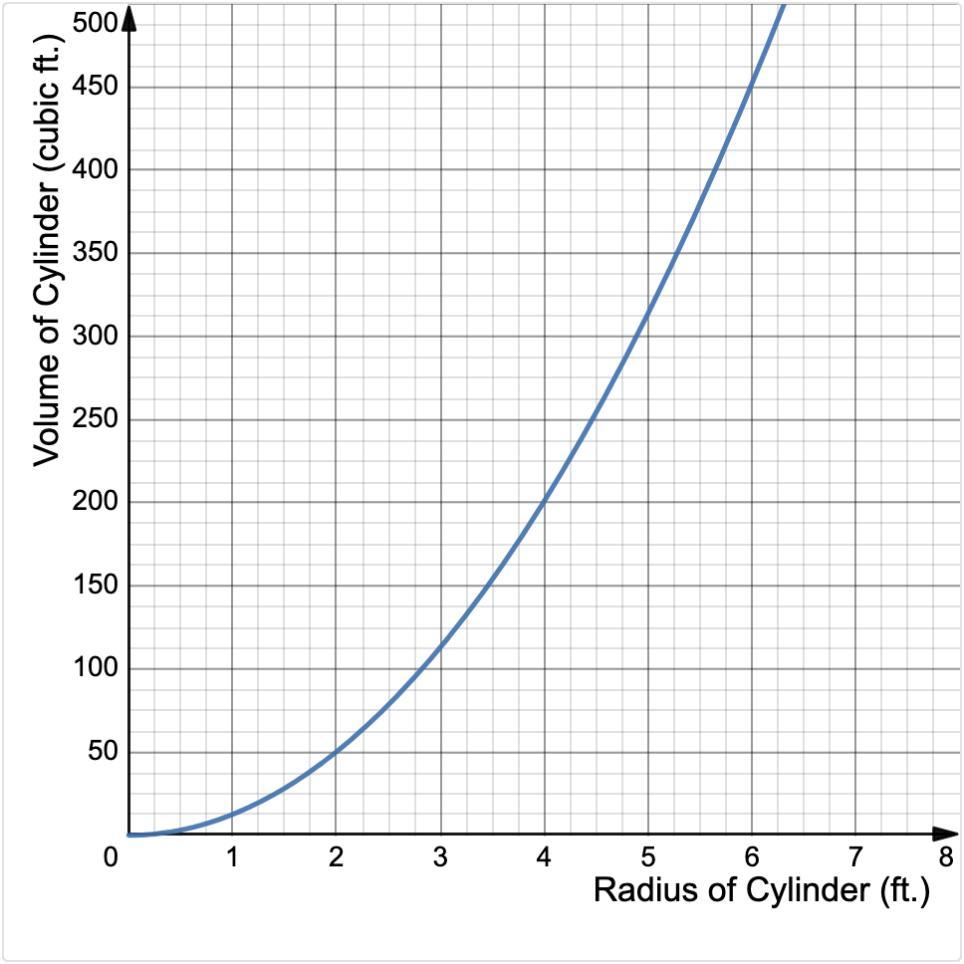
this function represents the relationship between the radius of cylinders with a height of feet and their volume. why is this relationship between radius and volume nonlinear?
Answers
The relationship between the radius and volume of a cylinder with a height of 4 feet is nonlinear because the volume of a cylinder is given by the formula V = πr²h, where r is the radius and h is the height. In this case, the height is fixed at 4 feet. As we change the radius, the volume changes in a nonlinear manner.
The volume increases much faster as the radius increases. This can be seen from the exponential nature of the formula, as the radius is squared. Therefore, even a small increase in the radius results in a substantial increase in the volume, making the relationship between radius and volume nonlinear.
In contrast, if the height were to be proportional to the radius, then the relationship between radius and volume would be linear. This is because the volume would be proportional to the product of the radius and height, which is a linear relationship.
Therefore, the nonlinear relationship between radius and volume, in this case, is due to the exponential nature of the formula for the volume of a cylinder and the fixed height of 4 feet.
To know more about volume of a cylinder, here
https://brainly.com/question/12667144
#SPJ4
--The given question is incomplete; the complete question is
"This function represents the relationship between the radius of cylinders with a height of 4 feet and their volumes. Why is this relationship between radius and volume nonlinear?"--
According to a newspaper report, in 2 million lie detector tests, 300,000 were estimated to have produced erroneous results. Assuming these figures to be correct, answer the following If ten tests were picked at random from these 2 million tests, what would be the chance that at least one of them produced an erroneous result
Answers
The result is approximately 0.839 or 83.9%.
In a newspaper report, it was mentioned that out of 2 million lie detector tests, an estimated 300,000 produced erroneous results. The probability of an erroneous result in these tests can be calculated using the given information. Let P (erroneous result) be the probability of an erroneous result in these tests.
P (erroneous result) = 300,000/2,000,000 = 0.15 Now we need to find the probability that at least one of the ten tests picked at random from these 2 million tests produced an erroneous result. Let P (at least one erroneous result in ten tests) be the probability of getting at least one erroneous result in ten tests.
P (at least one erroneous result in ten tests) = 1 - P (no erroneous result in ten tests)
P (no erroneous result in ten tests) = (1 - P (erroneous result))^10
P (no erroneous result in ten tests) = (1 - 0.15)^10
P (no erroneous result in ten tests) = 0.161
Therefore, P (at least one erroneous result in ten tests) = 1 - P (no erroneous result in ten tests)
P (at least one erroneous result in ten tests) = 1 - 0.161
P (at least one erroneous result in ten tests) = 0.839
So, the chance that at least one of the ten tests picked at random from these 2 million tests produced an erroneous result is approximately 0.839 or 83.9%.
Know more about probability here:
https://brainly.com/question/30034780
#SPJ11
need answers for questions A and B as soon as possible pleaseee

Answers
A) First, calculate the volume of cuboid A.
3x2x8 = 48 cm cubed
Cuboid B:
6x2xh = 48 cm cubed
Simplify:
12xh = 48 cm cubed
12x4 = 48 cm cubed
So, the height of cuboid B is 4 cm
B) Multiply the volume by 1,000:
4.5 L = 4,500 cubic cm
an online computer game company has 10,000 subscribers paying $8 per month. their research shows that for every 25-cent reduction in their fee, they will attract another 500 users. the table below models the revenue for several fee rates.what fee should the company charge to maximize their revenue? how do you know?
Answers
The fee should the companyfee should the company charge to maximize their revenue charge to maximize their revenue is $7.50.
To determine the fee that the online computer game company should charge to maximize their revenue, we need to calculate the revenue for each fee rate listed in the table below:
| Fee Rate | Number of Subscribers | Revenue |
|----------|----------------------|---------|
| $8.00 | 10,000 | $80,000 |
| $7.75 | 10,500 | $81,375 |
| $7.50 | 11,000 | $82,500 |
| $7.25 | 11,500 | $83,375 |
| $7.00 | 12,000 | $84,000 |
| $6.75 | 12,500 | $84,375 |
| $6.50 | 13,000 | $84,500 |
| $6.25 | 13,500 | $84,375 |
| $6.00 | 14,000 | $84,000 |
From the table, we can see that the revenue initially increases as the fee rate decreases, but then starts to decrease after $7.50. This is because although the number of subscribers increases with a lower fee rate, the decrease in revenue from each individual subscriber outweighs the increase in subscribers.
Therefore, the fee rate that would maximize revenue for the online computer game company is $7.50. This is the fee rate where the revenue is the highest, at $82,500. We know this is the optimal fee rate because any higher fee rate will result in fewer subscribers, and any lower fee rate will result in a decrease in revenue per subscriber.
Learn more about revenue at https://brainly.com/question/4528682
#SPJ11