An advertising executive wants to estimate the mean weekly amount of time consumers spend watching television. Based upon previous studies, the standard deviation is assumed to be 18 minutes. The executive wants to estimate, with 95% confidence, the mean weekly amount of time to within 5 minutes. What sample size is needed?
Answers
The sample size required is approximately 47. Hence, option B is the correct answer.
Given the standard deviation is assumed to be 18 minutes, the desired margin of error is 5 minutes.
We want to estimate the mean weekly amount of time consumers spend watching television with a 95% confidence level.
The formula for the sample size is as follows:
\([\ Large n=\frac{{Z}^2\cdot {\sigma }^{2}}{E^2}\]\)
where
\(n = sample sizeZ = z-score, i.e., 1.96 (for a 95% confidence level)σ = standard deviation\)
E = margin of error, i.e., 5 minutes
Putting in the values,
\([\begin{aligned}n&= \frac{{(1.96)}^{2}\cdot {(18)}^{2}}{{(5)}^{2}} \\&= 46.6096 \end{aligned}\].\)
Therefore, the sample size required is approximately 47.
Hence, option B is the correct answer.
To know more about standard deviation visit:
https://brainly.com/question/13498201
#SPJ11
Related Questions
Find x.
I need the answer asap, please.
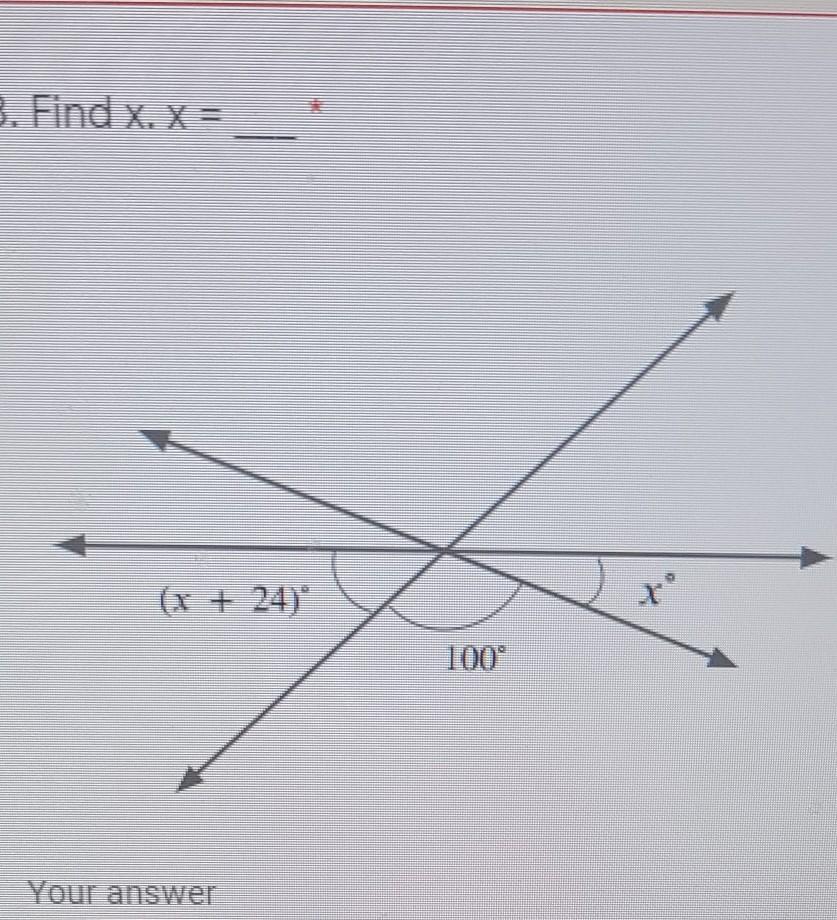
Answers
Answer:
x=28
Step-by-step explanation:
x+24+100+x=180
x+124+x=180
2x+124=180
2x=180-124
2x=56
divide both side by number attached to the x
therefore x=28
Find all the points in the form (1, y, z) which are equivalent
to the points (2, -1, 0) and (0, -2, 1)
Answers
The point in the form (1, y, z) that is equivalent to the given points is (1, 3/5, 3/5).
To find all the points in the form (1, y, z) that are equivalent to the points (2, -1, 0) and (0, -2, 1), we can use the concept of vector equivalence.
Let's consider the vector from (1, y, z) to (2, -1, 0). This vector is (2-1, -1-y, 0-z) = (1, -1-y, -z).
Similarly, the vector from (1, y, z) to (0, -2, 1) is (0-1, -2-y, 1-z) = (-1, -2-y, 1-z).
Since these two vectors are equivalent, we can set them equal to each other:
(1, -1-y, -z) = (-1, -2-y, 1-z)
Simplifying this equation, we get:
y - z = 0
2y + 3z = 3
Therefore, all points in the form (1, y, z) that are equivalent to the given points are given by the equations:
y = z
2y + 3z = 3
Solving this system of equations, we get:
y = 3/5
z = 3/5
So the point in the form (1, y, z) that is equivalent to the given points is (1, 3/5, 3/5).
Know more about vectors here:
https://brainly.com/question/30958460
#SPJ11
What is the percent for seniors?

Answers
For the given frequency table the percent of seniors is 10%.
What is frequency table?A frequency table counts the occurrences of each value or range of values in a dataset to organise and summarise the data. It is frequently employed in statistics to give a brief summary of the data and to spot patterns or trends.
The data is initially separated into equal-sized intervals called "classes" in order to construct a frequency table. Following that, a count of the data points belonging to each class is made, and the results are reported in a table manner. Columns for the classes, the frequency (count) of each class, and occasionally the relative frequency or percentage of each class can all be found in the table.
The total frequency is from the given table is:
1 + 2 + 5 + 2 = 10
The frequency of seniors is 1, so the percentage of seniors is:
(1/10) x 100% = 10%
Hence, for the given frequency table the percentage of seniors is 10%.
Learn more about frequency table here:
https://brainly.com/question/31189964
#SPJ1
express the confidence interval .222 < p < .888 in the form p - e
Answers
The confidence interval .222 < p < .888 can be expressed as p - e, where p = 0.555 and e = 0.333.
In a confidence interval, the point estimate represents the best estimate of the true population parameter, and the margin of error represents the range of uncertainty around the point estimate.
To express the given confidence interval in the form p - e, we need to find the point estimate and the margin of error.
The point estimate is the midpoint of the interval, which is the average of the upper and lower bounds. In this case, the point estimate is (0.222 + 0.888) / 2 = 0.555.
To find the margin of error, we need to consider the distance between the point estimate and each bound of the interval.
Since the interval is symmetrical, the margin of error is half of the range.
Therefore, the margin of error is (0.888 - 0.222) / 2 = 0.333.
Now we can express the confidence interval .222 < p < .888 as the point estimate minus the margin of error, which is 0.555 - 0.333 = 0.222.
Therefore, the confidence interval .222 < p < .888 can be expressed as p - e, where p = 0.555 and e = 0.333.
Learn more about confidence interval here:
https://brainly.com/question/31748686
#SPJ11
There are 4 colas, 1 ginger, 7 root beers, and 6 cherry sodas in a cooler. What are the odds of choosing a ginger ale? Give your answer in a proportion in lower terms.
Answers
Answer:
Step-by-step explanation:
the odds of choosing a ginger ale is 1/21
To find the proportion, add all the numbers together, and put that as the denominator. Put the number that you are trying to find the proportion of as the numerator
I need help please x+6=8+7
Answers
Answer:
9
Step-by-step explanation:
8+7=15
15-6=9
Step-by-step explanation:
x+6=8+7
-6 -6 -6
x= 2+1 i think this is the answer
How do you dilate points at a point?
Answers
To dilate a point at a point, you start by selecting a center of dilation and a scale factor.
Then, for each point that you want to dilate, you do the following:
Draw a line segment from the center of dilation to the point.Multiply the length of this line segment by the scale factor.Draw a line segment from the center of dilation to the new point, using the length that you just calculated.The new point is the point that you arrive at when you complete this line segment.For example, if you wanted to dilate point P by a scale factor of 2, with the center of dilation at O, you would draw a line segment from O to P, double its length, and then draw a new line segment from O to the new point, using the new length that you calculated. The new point would be the point that you arrive at when you complete this line segment.
Learn more about Scale Factor here:
https://brainly.com/question/25722260
#SPJ4
Please help me. I need help please

Answers
Answer:
Step-by-step explanation:
x^2=2^2+13^(1/2)^2
x^2=4+13
x^2=17
x=4.1 (to nearest tenth)
Look at the triangular prism below. Each triangular face of the prism has a base of 3 centimeters (cm)and a height of 4 cm. The length of the prism is 12 cm.
What is the volume of this triangular prism?

Answers
Answer:
chupapi muñeño
Step-by-step explanation:
Answer:
144 cm?
Step-by-step explanation:
V
\(v = l \times w \times h \\ v =12 \times 4 \times 3 \\ v = 12 \times 12 \\ v = 144\)
Please help find slope

Answers
Answer:
Select two points
7/-2 and 5/-1
subtract y1 from y2 to figure out y's change
7 - 5 = 2 change in y
now we subtract x1 from x2 to figure out x's change
-2 - ( -1 ) = -1 change in x
The slope will just be the results of the change in y and x but in the order of rise/run
2/-1 = -2 is the slope
A big ship drops its anchor. E represents the anchor's elevation relative to the water's surface (in meters) as a function of time t (in seconds).
E=−2.4t+75
How far does the anchor drop every 5 seconds?
Answer:12
Answers
Distance for the anchor drop every 5 seconds is,
⇒ E = 63 meters
What is mean by Multiplication?Multiplication means to add number to itself a particular number of times. Multiply will be viewed as a process of repeated addition.
Given that;
A big ship drops its anchor.
Here, E represents the anchor's elevation relative to the water's surface (in meters) as a function of time t (in seconds).
E = - 2.4t + 75
Now, Distance for the anchor drop every 5 seconds is,
Put t = 5;
E = - 2.4t + 75
E = - 2.4 × 5 + 75
E = - 12 + 75
E = 63 meters
Learn more about the multiplication visit:
brainly.com/question/10873737
#SPJ1
Can someone help me on this math question its confusing ill give brainly when right!!!

Answers
Answer:
x=5
Step-by-step explanation:
x=\(\sqrt{25}\)
x=5
Which of the following values are solutions to the inequality - 8 - 4x > 1?
I.-10 II. -1 III. 6
Answers
The solution of the linear inequation -8 - 4x > 1 is x < \(-\frac{9}{4}\)
-10 satisfies the given linear inequation
Inequation shows the comparision between two algebraic expressions by connecting the two algebraic expressions by >, <, ≥, ≤
A one degree inequation is known as linear inequation.
The given linear inequation is
-8 - 4x > 1
Now,
-8 - 4x > 1
-4x > 1 + 8
-4x > 9
x < \(-\frac{9}{4}\)
-10 satisfies the given linear inequation
To learn more about linear inequation, refer to the link-
https://brainly.com/question/24372553
#SPJ1
What is the domain of the function on the graph?

Answers
If the α significance level is changed from 0.10 to 0.01 when calculating a Confidence Interval for a parameter, the width of the confidence interval will: a. Decrease b. Increase c. Stay the same d. Vary depending on the data
Answers
If the α significance level is changed from 0.10 to 0.01 when calculating a confidence interval for a parameter, the width of the confidence interval will decrease.
Explanation: A confidence interval is an interval estimation of the unknown parameter and it is usually a range of values that is constructed using the sample data in such a way that the true value of the parameter lies within the range with some degree of confidence. Confidence intervals are used to estimate the true value of the parameter from a sample. The width of the confidence interval will be affected by the sample size, the variability of the population data, and the level of significance (α). If the level of significance is changed from 0.10 to 0.01, the width of the confidence interval will decrease because the level of significance is inversely proportional to the confidence level.
So, decreasing the level of significance will result in a smaller interval because the level of confidence will be higher. Therefore, the correct option is a) decrease.
To know more about variability , click here:
https://brainly.com/question/15740935
#SPJ11
How do you find the scale factor of a dilation with a center of dilation?
Answers
The scale factor of dilation can be found by using the formula\((x_0=\frac{kx_1-x_2}{k-1}, y_0=\frac{ky_1-y_2}{k-1})\).
What is dilation?
A dilation is a transformation that creates an image that has the same shape as the original but is larger.
• An enlargement is a dilation that produces a larger image.
• A reduction is a dilation that produces a smaller image.
• A dilation expands or contracts the original figure.
A dilation is a stretch or a shrink in the size and location of a figure or point.
The scale factor in a dilation is the amount by which the figure is stretched or shrunk.
The center of dilation is a reference point used to appropriately scale the dilation of a figure. Given a point on the pre-image, \((x_1, y_1)\)and a corresponding point on the dilated image \((x_2, y_2)\)and the scale factor,
k, the location of the center of dilation, \((x_0,y_0)\) is
\((x_0=\frac{kx_1-x_2}{k-1}, y_0=\frac{ky_1-y_2}{k-1})\)
Hence, the scale factor of dilation can be found by using the formula\((x_0=\frac{kx_1-x_2}{k-1}, y_0=\frac{ky_1-y_2}{k-1})\).
To learn more about dilation, visit:
brainly.com/question/11914738
#SPJ4
If the price of a school bus increased at the same rate as the CPI from 1970 to 1984, how much did a school bus cost in 1984?
Answers
The cost of a bus in 1984 is =$ 7360 and in 1992 is $28140.and CPI in 1950 is 20.5.
The consumer price index (CPI) is the index that shows how much prices have changed over time. This index mainly focuses on the retailer prices for market players. Usually, this index increases due to inflation.
Part(1)
% change in CPI (1984-70)
\(=\frac{36.8-100}{100} \\=-63.2 \ percentage \\=-0.632\)
Cost of bus = 20000(1-0.632)=$ 7360
Part II
% change in CPI (1984-92)
\(=\frac{140.7-199}{100}\)
=40.7%
= 0.407
cost of a bus in 1992 = 20,000(1+0.407)
= $28140
part (3)
% change in CPI (1950-84)=% change in price
\(\frac{100-x}{x}*100=[[20000-4100]/4100]*100\\100-x=3.878x\\=x=20.5\\the\ cpi\ in\ 1950\ was \ 20.5.\)
The complete question is -
In 1984, a school bus cost $20,000. To answer each of the parts below, assume that the consumer price index (CPI) was 36.8 in 1970, 100 in 1984, and 140.7 in 1992.
Part I: If the price of a school bus increased at the same rate as the CPI from 1970 to 1984, how much did a school bus cost in 1970? By how much did the price of a school bus increase from 1970 to 1984?
Part II: If the price of a school bus increased at the same rate as the CPI from 1984 to 1992, how much did a school bus cost in 1992? By how much did the price of a school bus increase from 1984 to 1992?
Part III: If a school bus cost $4100 in 1950, and if the price of a school bus increased at the same rate as the CPI from 1950 to 1984, what was the CPI to the nearest tenth in 1950?
learn more about.consumer price index (CPI)
https://brainly.com/question/8416975
#SPJ4
The line graph shows the poluution rate of a certain lake from 1950 to 2000. Use the graph to answer the question. Percentage of pollution by Volume (+ SP) 4.0% 3.0% 2.0% 1.0% 0.0% 1950 1960 1970 1980 1990 2000 Find an estimate for the percent of pollution by volume of the lake in 1960. A. 3% OB. 2.5% OC. 2% D. 1%

Answers
The introduction of harmful chemicals into the air is known as air pollution.
What are the primary sources of air pollution?The chief causes of man-made air pollution include vehicle emissions, fuel oils and natural gas used to heat houses, byproducts of manufacturing and electricity generation, notably coal-fueled power plants, and odors from chemical manufacture.Industrial emissions, automobile emissions, and any other place where fossil fuels are burnt are all sources of atmospheric pollution, or air pollution. Another major contaminant that can cause ozone depletion is methane, which is released by landfills and cattle.
Air pollution can have long-term harmful consequences, such as acid rain, which pollutes the Earth’s bodies of water and ruins infrastructure.
To learn more about Air pollution to refer:
https://brainly.com/question/21683809
#SPJ1
WILL MARK BRAINLIEST

Answers
Answer:
30
Step-by-step explanation:
60(highest) - 30(lowest) = 30(range)
Find the area of the shaded region in the figure below if the radius of the outer circle is 8 and the
radius of the inner circle is 2. Keep your answer in terms of it.

Answers
Answer:
outer circle=22/7×8^2
=201.143
inner circle=22/7×2^2
=12.571
shaded portion= 201.143-12.571
=188.572cm^2
Answer:
60π
Step-by-step explanation:
What is the value of f(x1) when f(x) = 2x + 2?
Enter your answer in the box:
F(-1) = [____]
Answers
The value of f(-1) when f(x) is defined as given in the question is 0.
What is the substitution method?
One method for solving simultaneously linear equations using algebra is the substitution method. It involves changing the value of any one of the variables in one equation & applying it to another one.
Given, f(x) = 2x + 2 ......... (i)
Now, we need to find the value of f(-1), by substituting the value of x = -1 in above equation (i), then
f(-1) = 2*(-1) + 2 = -2+2 = 0
Hence, the required answer of f(-1) is 0.
To learn more about the substitution method
https://brainly.com/question/22340165
#SPJ1
Plz help me I rlly need it!

Answers
2. 17.7 is the mean
3. 25.5 is the median
4. mean > median
5. 28 is the range
which of the following quadrilaterals have four congruent sides?
A. parallelogram B. rectangle C. rhombus D. square
Answers
The quadrilateral that has four congruent sides is option D. square. A square is a special type of rectangle and rhombus, characterized by having all four sides of equal length.
A parallelogram (option A) is a quadrilateral with opposite sides that are parallel. While the opposite sides of a parallelogram are congruent, it does not guarantee that all four sides are equal.
A rectangle (option B) is a quadrilateral with four right angles. While opposite sides of a rectangle are congruent, it does not necessarily have four congruent sides unless it is also a square.
A rhombus (option C) is a quadrilateral with all sides of equal length. While a rhombus does have four congruent sides, it is not the only quadrilateral with this property.
Therefore, among the given options, the quadrilateral that has four congruent sides is the square (option D).
know more about quadrilaterals.
https://brainly.com/question/1626741
#SPJ11
determine the quadrant in which θ lies. csc(θ) > 0, tan(θ) < 0
Answers
θ lies in the second quadrant (QII).
Given that csc(θ) > 0 and tan(θ) < 0, we can determine the quadrant in which θ lies based on the signs of the trigonometric function. Recall the signs of trigonometric functions in each quadrant: In the first quadrant (QI), all trigonometric functions are positive. In the second quadrant (QII), only sin(θ) and csc(θ) are positive. In the third quadrant (QIII), only tan(θ) and cot(θ) are positive. In the fourth quadrant (QIV), only cos(θ) and sec(θ) are positive. Given that csc(θ) > 0, we can conclude that θ lies in either QI or QII since csc(θ) is positive in both quadrants. Now, considering that tan(θ) < 0, which means the tangent function is negative, we can narrow down the possibilities. In QI, both tan(θ) and csc(θ) are positive, so it does not satisfy the given condition tan(θ) < 0. Therefore, θ must lie in QII. In conclusion, θ lies in the second quadrant (QII).
Learn more about trigonometric functions and quadrants here:
https://brainly.com/question/10194287
#SPJ11
can i get help please so much :)

Answers
Median =75
Mode= 75
Range= 49
Answer:
Mean: 76.6 (rounded the original number- 76.571)
Median: 75
Mode: 75
Range: 49
Standard Deviation: 14.50 (i round it, original number- 14.4504)
Step-by-step explanation:
I calculated everything, please lemme know if any of it is wrong!
This is the last one i think

Answers
the slope is 3 because the y value increases by 3
A large population has mean 100 and standard deviation 16. What is the probability that the sample mean will be within plusminus 2 of the population mean if the sample size is n = 100? What is the probability that the sample mean will be within plusminus 2 of the population mean if the sample size is n = 400? What is the advantage of a larger sample size?
Answers
The probability that the sample mean will be within plus minus 2 of the population mean if the sample size is n = 100 between z-scores of 0 and 2.5 using a z-table.
The standard deviation of the sample distribution, commonly known as the standard error, can be computed using the formula given that the population mean is 100 and the standard deviation is 16:
Standard Error = Standard Deviation / sqrt(sample size)
Let's determine the likelihoods for sample sizes of n = 100 and n = 400:
For n = 100:
Standard Error = 16 / sqrt(100) = 16 / 10 = 1.6
We can determine the z-scores for the upper and lower boundaries to establish the likelihood that the sample mean will be within plus or minus 2 of the population mean:
Lower Bound z-score = (Sample Mean - Population Mean) / Standard Error
Lower Bound z-score = (100 - 100) / 1.6
Lower Bound z-score = 0
Upper Bound z-score = (Sample Mean - Population Mean) / Standard Error
Upper Bound z-score = (104 - 100) / 1.6
Upper Bound z-score = 4 / 1.6
Upper Bound z-score = 2.5
We can calculate the region under the normal distribution curve between z-scores of 0 and 2.5 using a z-table or statistical software. This shows the likelihood that the sample mean will be within +/- 2 standard deviations of the population mean.
For n = 400:
Standard Error = 16/√400
Standard Error = 16/20
Standard Error = 0.8
We determine the z-scores by following the same procedure as above:
Lower Bound z-score = (Sample Mean - Population Mean) / Standard Error
Lower Bound z-score = (100 - 100) / 0.8
Lower Bound z-score = 0
Upper Bound z-score = (Sample Mean - Population Mean) / Standard Error
Upper Bound z-score = (104 - 100) / 0.8
Upper Bound z-score = 4 / 0.8
Upper Bound z-score = 5
Once more, we may determine the region under the normal distribution curve between z-scores of 0 and 5 using a z-table or statistical software.
A larger sample size, like n = 400, has the benefit of a lower standard error. The sampling distribution of the sample mean will be more constrained and more closely resemble the population mean if the standard error is less.
As a result, there is a larger likelihood that the sample mean will be within +/- 2 of the population mean. In other words, the estimate of the population mean gets more accurate and dependable as the sample size grows.
To learn more about population mean link is here
brainly.com/question/30324262
#SPJ4
2. *
2 points
Which set of ordered pairs represents a function?
1) {(0,4),(2,4),(2,5)}
2) {(6,0),(5,0),(4,0)}
3) {(4,1),(6,2), (6,3),(5,0)}
4) {(0,4),(1,4),(0,5),(1,5)}
Option 1
Answers
Answer:
2
Step-by-step explanation:
This is the only set of ordered pairs that represents a function because if this function was graphed, it would pass the vertical line test. Looking at the ordered pairs, a function must not have more than one ordered pair that has the same x-coordinate values. All the other answer choices have 2 or more ordered pairs with the same x-values, meaning 2 is the correct answer.
(4x + 2) - 3(6x - 2)
A
13x - 3
B
-14x + 8
с
–5x+ 4
D 10x - 3

Answers
Answer:
B. -14x+8
Step-by-step explanation:
On a multiple choice test, each question has 5 possible answers. If you make a random guess on the first question, what is the probability that you are correct
Answers
The probability that you are correct by making a random guess is 1/5.
According to the given question.
On a multiple choice test, each question has 5 possible answers.
As we know that probability, is a measure of the likelihood of an event to occur. It is calculated by taking the ratios of favorable outcomes to the total number of outcomes.
Here, it is given that there are 5 possible answers of one question.
⇒ Total number of outcomes = 5
Also, only one answer will correct out of 5 possible answers.
Which means, total number of favorable outcomes = 1
Therefore, the probability that you are correct by making a random guess
= favorable outcomes/total number of outcomes
= 1/5
Hence, the probability that you are correct by making a random guess is 1/5.
Find out more information about probability here:
https://brainly.com/question/11234923
#SPJ4