Angles jhi and gjh are inscribed angles. we have that m∠jhi = one-half b and m∠gjh = one-halfa by the . angle jhi is an exterior angle of triangle . because the measure of an exterior angle is equal to the sum of the measures of the remote interior angles, m∠jhi = m∠jgi m∠gjh. by the , one-halfb = m∠jgi one-halfa. using the subtraction property, m∠jgi = one-halfb " one-halfa. therefore, m∠jgi = one-half(b " a) by the distributive property.
Answers
As we have proved that m∠JGI = One-half(b – a), where a and b represent the degree measures of arcs FH and JI by using the angle.
To begin the proof, we need to recall a few key facts about angles and arcs. First, we know that an angle formed by two radii of a circle is always congruent to another angle formed by two radii of the same circle. This means that if we draw radii from the center of the circle to points F, G, and H, we know that ∠FGH is congruent to ∠FOH and ∠FGO.
Next, we need to consider the relationship between angles and arcs. We know that the measure of an angle formed by two radii of a circle is equal to one-half the measure of the arc intercepted by that angle.
Now, let's apply these facts to the situation at hand. We know that ∠FGH is congruent to ∠FOH and ∠FGO, so we can say that:
m∠FGO = m∠FGH - m∠FOH
We also know that the measure of ∠FOH is equal to one-half the measure of arc FH, so we can substitute that in to get:
m∠FGO = m∠FGH - (1/2)m(arc FH)
Similarly, we can say that:
m∠JGO = m∠JGH - m∠JHO
And we know that the measure of ∠JHO is equal to one-half the measure of arc JI, so we can substitute that in to get:
m∠JGO = m∠JGH - (1/2)m(arc JI)
Now, we want to find the measure of ∠JGI. We can do this by subtracting the measures of ∠FGO and ∠JGO from the measure of ∠FGJ:
m∠JGI = m∠FGJ - m∠FGO - m∠JGO
As per the distributive property, we have proved that the value of
=> m∠JGI = One-half(b – a)
To know more about angle here
https://brainly.com/question/28451077
#SPJ4
Complete Question:
Prove that m∠JGI = One-half(b – a), where a and b represent the degree measures of arcs FH and JI.
Related Questions
help please ineed this

Answers
Answer:
(3,1)
Step-by-step explanation:
Serena’s average speed during her training run was 8 kilometers per hour over the 2 hours that she ran. What was the total distance that she ran?
Use the formula d = rt, where d represents the distance, r represents the rate, and t represents the time.
4 km
Answers
Step-by-step explanation:
so, we just enter the given data into the given formula. and then calculate. it does not get easier than that.
d = 8km/h × 2h = 16km
Serena ran 16km in these 2 hours.
Answer:
the correct answer is 16km
Step-by-step explanation:
pl.z dont delete this
- 3x-4y=31
-2x + y = 6
Solve the system(by substitution)
Answers
Answer:
x = -5
y = -4
Step-by-step explanation:
|a+1) (3) [8pts] Use the formula = n(n+1) to calculate the sum. DO NOT use the formula for the sum of the terms of an arithmetic sequence. 501 +502 +503 +504 + ... + 10,000
Answers
Using the formula n(n+1), the sum of the terms from 501 to 10,000 is calculated to be 49,502,501.Subtracting the sum from 1 to 500 yields the desired result.
To find the sum of the terms from 501 to 10,000 using the formula n(n+1), we first need to determine the values of n. In this case, the first term, 501, corresponds to n = 500 (since n is obtained by subtracting 1 from the given term). The last term, 10,000, corresponds to n = 9,999.
Now we can apply the formula: n(n+1)/2. Plugging in the values, we get (500)(500+1)/2 for the sum from 501 to 500, which equals 250,500. Similarly, for the sum from 501 to 10,000, we calculate (9,999)(9,999+1)/2, resulting in 49,950,000.
However, since we want the sum starting from 501, we need to subtract the sum from 1 to 500. Using the same formula, (500)(500+1)/2, we obtain 125,250 for the sum from 1 to 500. Subtracting this value from the sum from 501 to 10,000, we get 49,950,000 - 125,250 = 49,824,750.
Therefore, the sum of the terms from 501 to 10,000 using the formula n(n+1) is 49,824,750.
To learn more about sum of the terms click here brainly.com/question/30032665
#SPJ11
McDonald's sells about 150 hamburgers every 3 seconds. How many seconds will it take McDonald's to sell 6,400 hamburgers
Answers
Answer:
6250
Step-by-step explanation:
Hope the answer is correct.
To develop the formula for s(M1-M2) we consider three points:
-Each of the two sample means represents it own population mean, but in each case there is some error.
-The amount of error associated with each sample mean is measured by the estimated standard error of M.
-For the independent-measures t statistic, we want to know the total amount of error involved in using two sample means to approximate two population means.
-To do this, if the samples are the same size, we will find the error from each sample separately and then add the two errors together.
-When the samples are of different sized, a pooled or average estimate, that allows the bigger sample to carry more weight in determining the final value, is used
Answers
when developing the formula for s(M1-M2), we consider the amount of error for each sample mean, the estimated standard error of M as a statistic, and use an average estimate when dealing with different sample sizes. This helps us determine the total amount of error when using two sample means to approximate two population means.
The independent-measures t statistic is used to determine the total amount of error when using two sample means to approximate two population means. To develop the formula for s(M1-M2), we consider the following points:
1. Each of the two sample means represents its own population mean, but there is some error involved in each case. This error is referred to as the "amount of error."
2. The "amount of error" associated with each sample mean is measured by the estimated standard error of M (sM). This statistic helps us understand how much the sample means may deviate from their respective population means.
3. To find the total amount of error involved in using two sample means to approximate two population means, we consider the size of each sample. If the samples are the same size, we can find the error from each sample separately and add the two errors together.
4. When the samples are of different sizes, a "pooled" or "average estimate" is used to account for the different sample sizes. This approach allows the larger sample to carry more weight in determining the final value of the t statistic.
In summary, when developing the formula for s(M1-M2), we consider the amount of error for each sample mean, the estimated standard error of M as a statistic, and use an average estimate when dealing with different sample sizes. This helps us determine the total amount of error when using two sample means to approximate two population means.
Visit here to learn more about standard error:
brainly.com/question/13179711
#SPJ11
An oil tanker can be emptied by the main pump in 4 hours. An auxiliary pump can empty the tanker in 9 hours.If the main pump is started at 6 PM, when should the auxiliary pump be started so that the tanker is emptied by 9 PM,The auxiliary pump should be started at
Answers
Explanation
To solve the question, we will be aware that
There are 3 hours between 6PM and 9PM ,
The main pump's emptying rate is 1/4 tanker per hour. It will be open
the entire 3 hours, so it will empty 3/4 of the tank.
this means that the auxiliary pump must empty the remaining 1/4
Thus
\(rate\text{ in tanker per hour }\times time\text{ required=}\frac{1}{4}tank\)Thus, we will have
\(\frac{1}{4}\times3\text{ hours =45 minutes}\)Therefore
The auxiliary pump should start by 6pm + 45 minutes = 6:45pm
A scientist measures the depth of the water in a pond each month. The pond is considered full at 0 m. She compares her measures to the height of the water when the pond is considered full and records the change in depth in a table

Answers
The months in which the depths decreased are:
Between April and May
Between June and July
How to solve function tables?The change in depth between April and May is calculated as:
Change in depth = -0.28 - (-0.15) = -0.13 m
Thus, there was a decrease in depth between april and may
The change in depth between May and June is calculated as:
Change in depth = -0.08 - (-0.28) = 0.20 m
Thus, there was an increase in depth between May and June
The change in depth between June and July is calculated as:
Change in depth = -0.01 - (-0.05) = 0.07 m
Thus, there was a decrease in depth between June and July.
Read more about function tables at: https://brainly.com/question/20053217
#SPJ1
The complete question is:
A scientist measures the depth of the water in a pond each month. The pond is considered full at 0 m. She compares her measures to the height of the water when the pond is considered full and records the change in depth in a table
Between which months did the depth of water decrease?
Explain the difference between a sample and a census. Every 10 years, the U.S. Census Bureau takes a census. What does that mean?
Answers
The U.S. Census Bureau takes a census every 10 years, which means that they attempt to count every person living in the United States and collect data on various demographic and social characteristics.
A sample is a subset of a larger population, selected in a way that it represents the characteristics of the population from which it is drawn. The purpose of sampling is to estimate or infer something about the population based on the characteristics of the sample.
On the other hand, a census is a survey or count that attempts to measure every member of a population.
In a census, data is collected on every individual or item in a population, rather than just a representative sample.
If you wanted to estimate the average income of households in a city, you could select a sample of households and estimate the average income based on the incomes of the sampled households.
This would be an example of sampling.
Alternatively, you could conduct a census of every household in the city, collecting income data from every household, and calculate the exact average income of all households in the city.
The purpose of the census is to provide a complete and accurate count of the population, which can then be used to allocate political representation and government funding, as well as to provide data for research and planning purposes.
For similar questions on census
https://brainly.com/question/25846785
#SPJ11
Ian has $6000. He wants to buy a car within $1500 of this amount. Define a variable, write an open sentence, and find
the range of car prices. ANSWER ASAP SDJLB
Answers
Can you please mark me as brainilist please
Please help me with my math yes or no question

Answers
Answer:
no
Step-by-step explanation:
Please help solve the equation and please don’t take advantage of the points.

Answers
Answer:
m=2/3, b=4
Step-by-step explanation:
Using the rise over run method, you can count from two points. Also since this line is positive. The b is found by seeing where the line crosses the y axis. It crosses at 4.
AB= (1, y, -2) BC= (2x, -3, z), AC= (1, 4, x+y) find the values of x, y, and z
Answers
AB + BC = AC
(1, y, -2) + (2x, -3, z) = (1, 4, x+y)
Breaking down each component, we get:
1 + 2x = 1 → 2x = 0 → x = 0
y - 3 = 4 → y = 7
-2 + z = x + y → z = x + y + 2
Therefore, the values of x, y, and z are:
x = 0
y = 7
z = x + y + 2 = 9
81x^6-(y+1)^2 what are the U and V
Answers
The simplified form of the expression \(81x^6 - (y + 1)^2\) in terms of U and V is 729x^6 - V^2.
In this question, we are given specific values for U and V and asked to express the given expression in terms of those values.
To simplify the expression using the given values, we substitute \(U = 3x^3\)and V = y + 1 into the original expression:
\(81x^6 - (y + 1)^2\)
Replacing U and V:
\(81(3x^3)^2 - (V)^2\)
Simplifying:
\(81 \times 9x^6 - V^2\)
\(729x^6 - V^2\)
Therefore, the simplified form of the expression \(81x^6 - (y + 1)^2\) in terms of U and V is\(729x^6 - V^2.\)
In this way, we can represent the original expression in a simplified form using the assigned values for U and V.
For similar question on expression.
https://brainly.com/question/723406
#SPJ8
Consider the expression: \(81x^6 - (y + 1)^2\)
If\(U = 3x^3\) and V = y + 1, what is the simplified form of the expression in terms of U and V?
In this question, we are given specific values for U and V and asked to express the given expression in terms of those values.
When testing partial correlation, the impact of a third variable is ______. a. added. b. removed. c. deleted. d. reduced
Answers
When testing partial correlation, the impact of a third variable is removed.
Partial correlation is a statistical technique used to assess the relationship between two variables while controlling for the influence of one or more additional variables, known as the third variable(s) or covariate(s). The aim of partial correlation is to determine the strength and direction of the association between two variables after accounting for the potential confounding effect of other variables.
By controlling for the influence of third variable(s), partial correlation allows researchers to isolate the unique relationship between the two variables of interest, while holding constant the effects of other variables that may be correlated with both the variables being studied. This helps to assess the direct association between the two variables of interest, beyond the potential influence of other variables.
Partial correlation is commonly used in research and statistics when the relationship between two variables of interest may be confounded by the presence of other variables that could affect the results. It is a valuable tool for examining the specific association between two variables while accounting for the potential influence of other factors, thereby providing a more accurate and nuanced understanding of the relationship between those variables.
To learn more about research, refer below:
https://brainly.com/question/18723483
#SPJ11
WHY DO U HATE ME?? ALSO HELP IN PIC!!!!!!!!!!!!
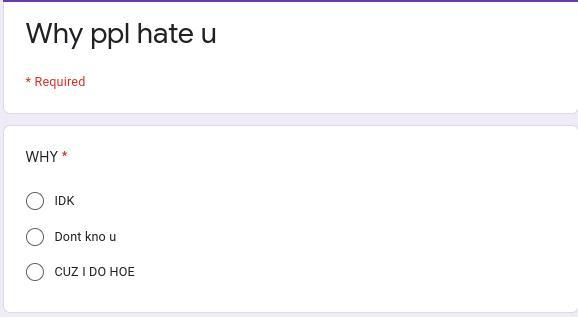
Answers
Answer:
Don't know u is correct. Also I'm not a h0* how rude >:(
Answer:
None of the above because I love you
Step-by-step explanation:
I don't hate you and if some people do they must have there reasons which I don't know, but some people just hate for no reason and if they can hate for no reason some people can love for no reason.
You may be a complete stranger to me but I love you
Find a formula for the polynomial (x) with degree 3, real coefficients, zeros at x =-6 and 3+i and y-intercept (0,30). Write the polynomial in expanded form.
Answers
The polynomial with degree 3, real coefficients, zeros at x = -6 and 3+i, and a y-intercept of (0,30) is given by f(x) = (x + 6)(x - 3 - i)(x - 3 + i).
To find the polynomial with the given conditions, we start by using the zero-product property. Since the zeros are x = -6, 3+i, and 3-i, the corresponding factors of the polynomial are (x + 6), (x - 3 - i), and (x - 3 + i).
Now, to obtain the expanded form of the polynomial, we multiply these factors together:
f(x) = (x + 6)(x - 3 - i)(x - 3 + i)
Expanding this expression, we get:
f(x) = (x + 6)(x^2 - 3x + ix - 3x + 9 - 3i - ix + 3i - i^2)
Simplifying further, we have:
f(x) = (x + 6)(x^2 - 6x + 9 + 1)
f(x) = (x + 6)(x^2 - 6x + 10)
Multiplying the binomials, we obtain:
f(x) = x^3 - 6x^2 + 10x + 6x^2 - 36x + 60
Combining like terms, the expanded form of the polynomial is:
f(x) = x^3 - 26x + 60
Learn more about polynomial here:
https://brainly.com/question/11536910
#SPJ11
What is the area of the circle below? (area answer units are mi?)

Answers
Answer:
314.16 mi
Step-by-step explanation:
Answer:
The answer is 314.16
Step-by-step explanation:
A member of the junior varsity swim team will be elected as President. Each member is equally likely to be elected. The probability that a sophomore is elected is $3/2$ times the probability that a freshman is elected. Everyone on the junior varsity swim team is either a freshman or sophomore. What fraction of the swim team are sophomores?
Answers
Using the probability concept, it is found that 60% of the swim team are sophomores.
What is a probability?A probability is given by the number of desired outcomes divided by the number of total outcomes.
The sum of the probabilities of all outcomes of an event is of 1, hence:
P(freshman) + P(sophomore) = 1.
The probability that a sophomore is elected is $3/2$ times the probability that a freshman is elected, hence:
x + 3/2x = 1.
5/2x = 1
5x = 2
x = 0.4.
Thus:
40% of the swim team is composed by freshman.60% of the swim team is composed by sophomores.More can be learned about probabilities at https://brainly.com/question/14398287
#SPJ1
help me please quick!!!

Answers
Answer:
y is 12 degrees
x is 30 degrees
Step-by-step explanation:
If angle ABC is equal to angle MNC, that means 5y equals to 60 degrees. 60 divided by 5 equals 12. So, y equals 12 degrees
2x and 4x equals 180 degrees. So, 180 divided by 6 equals to 30. So x equals 30 degrees
Answer:
x = 30, y = 12
Step-by-step explanation:
2 similar equilateral triangles, each corner is 60 degrees.
2x = 60 degrees
divide by 2
x = 30 degrees
5y = 60 degrees
divide by 5
y = 12 degrees
This can be verified by checking 4x + 2x which gives you 180 degrees forming that straight line angle.
The Triangle Vertex Deletion problem is defined as follows:
Given: an undirected graph G =(V,E) , with |V| = n, and an integer k >= 0 .
. Question: Is there a set of at most k vertices in whose deletion results in deleting all triangles in G?
(a) Give a simple recursive backtracking algorithm that runs in O(3k p(n)) where p(n) is a low-degree polynomial corresponding to the time needed to determine whether a certain vertex belongs to a triangle in G
. (b) Selecting a vertex that belongs to two different triangles can result in a better algorithm. Using this idea, provide an improved algorithm whose running time O(2,562n p(n)) is in where 2.652 is the positive root of the x2 = x+4
Answers
(a) A recursive backtracking algorithm (O(3^k * p(n))) is proposed for the Triangle Vertex Deletion problem, aiming to find a set of at most k vertices that can remove all triangles in a graph G. (b) An improved algorithm (O(2.562^n * p(n))) selects vertices belonging to multiple triangles, enhancing the efficiency of the Triangle Vertex Deletion problem.
(a) A simple recursive backtracking algorithm for the Triangle Vertex Deletion problem can be formulated as follows:
1. Start with an empty set S of deleted vertices.
2. If all triangles are deleted (i.e., no triangle exists in G), return true.
3. If k = 0, return false since no more vertices can be deleted.
4. Select a vertex v from V.
5. Remove v from V and add it to S.
6. Recursively check if deleting v results in deleting all triangles. If so, return true.
7. Restore v in V and remove it from S.
8. Recursively check if not deleting v results in deleting all triangles. If so, return true.
9. If neither step 6 nor step 8 returned true, move to the next vertex in V and repeat steps 4-9.
10. If no vertex leads to the deletion of all triangles, return false.
The time complexity of this algorithm is O(3^k * p(n)), where p(n) is the time needed to determine if a vertex belongs to a triangle.
(b) To improve the algorithm, we can exploit the idea of selecting a vertex that belongs to two different triangles. The improved algorithm can be defined as follows:
1. Start with an empty set S of deleted vertices.
2. If all triangles are deleted (i.e., no triangle exists in G), return true.
3. If k = 0, return false since no more vertices can be deleted.
4. Select a vertex v that belongs to at least two different triangles.
5. Remove v from V and add it to S.
6. Recursively check if deleting v results in deleting all triangles. If so, return true.
7. Restore v in V and remove it from S.
8. Recursively check if not deleting v results in deleting all triangles. If so, return true.
9. If neither step 6 nor step 8 returned true, move to the next vertex in V and repeat steps 4-9.
10. If no vertex leads to the deletion of all triangles, return false.
The time complexity of this improved algorithm is O(2.562^n * p(n)), where 2.562 is the positive root of the equation x^2 = x + 4.
To know more about backtracking refer here:
https://brainly.com/question/33169337#
#SPJ11
please answer my last question got ignored

Answers
Answer:
A. 136 sq. cm.
Step-by-step explanation:
First find the area of the rectangle:
16 times 7 is 112
13-7 is 6
16-8 is 8
The formula for the area of a triangle is ab/2
thus:
6 times 8 is 48/2
Which is 24
Add 112 with 24
Which is 136
Thus the answer is A. 136 sq. cm.
Hope this helps!
Adi bought a bag for $25 and sold it at a loss of 10%. Find the selling price of the bag.
Answers
Answer:
The selling price of the bag is $22.5
Step-by-step explanation:
Buying Price = $25,
Selling Price = ?
Since they sold it at a loss of 10%,
So, they sold it for a price 10% less than the buying price,
or at 90% or 0.9 of the buying price,
so,
Selling Price = (0.9)(25) = $22.5
Use the distributive property to remove the parentheses. Thankyou!
2(v - 5)
3(u - 2)
7(3 + v)
Answers
Answer:
1) 2v-10
2) 3u-6
3) 21 + 7v
Step-by-step explanation:
Using the distibutive property all you have to do is have the number on the of the parenthesis multiply itself to each component in your parenthesis.
An estimator is consistent if as the sample size decreases, the value of the estimator approaches the value of the parameter estimated. (True or False)
Answers
The statement "An estimator is consistent if as the sample size decreases, the value of the estimator approaches the value of the parameter estimated" is False.
Consistency is an important property of estimators in statistics. An estimator is consistent if its value approaches the true value of the parameter being estimated as the sample size increases.
In other words, if we repeatedly take samples from the population and compute the estimator, the values we obtain will be close to the true parameter value.
This is an essential characteristic of a good estimator, as it ensures that as more data is collected, the estimation error decreases.
However, as the sample size decreases, the value of the estimator is more likely to deviate from the true value of the parameter. The reason for this is that a small sample size may not be representative of the population, and as a result, the estimation error may increase.
As a consequence, the statement is false. In conclusion, consistency is a property that an estimator possesses when its value converges to the true value of the parameter as the sample size grows.
As the sample size decreases, the estimator may become less reliable, leading to an increase in the estimation error.
For similar question on parameter:
https://brainly.com/question/12393177
#SPJ11
1315) Imagine some DEQ: y'=f(x,y), which is not given in this exercise.
Use Euler integration to determine the next values of x and y, given the current values: x=2, y=8 and y'=9. The step size is delta_X= 5. 2 answers
Refer to the LT table. f(t)=6. Determine tNum,a,b and n. 4 answers
Answers
To use Euler integration to determine the next values of x and y, given the current values x=2, y=8, and y'=9, with a step size of delta_X=5, we can use the following formula:
x_new = x_current + delta_X
y_new = y_current + delta_X * y'
Using the given values, we have:
x_new = 2 + 5 = 7
y_new = 8 + 5 * 9 = 53
Therefore, the next values of x and y using Euler integration with a step size of delta_X=5 are x=7 and y=53.
Learn more about Euler integration here: brainly.com/question/32513975
#SPJ11
Given the equation y = -3x + 6, the slope is

Answers
Answer:
-3 I think...
Step-by-step explanation:
y=mx+b. where m is the slope, since -3 is the value for m, it is the slope
Jeremiah's retirement party will cost $656 if he invites 82 guests. If there are 91 guests, how much will Jeremiah's retirement party cost? Assume the relationship is directly proportional.
Answers
We can write a proportion to solve
82 guests 91 guests
------------------- = -------------
656 dollars x dollars
Using cross products
82x = 91 * 656
82x =59696
Divide each side by 82
82x/82 = 59696/82
x =728
The party with 91 guests will cost 728 dollars
A genetic experiment involving peas yielded one sample of offspring consisting of 437437 green peas and 129129 yellow peas. Use a 0.050.05 significance level to test the claim that under the same circumstances, 2727% of offspring peas will be yellow. Identify the null hypothesis, alternative hypothesis, test statistic, P-value, conclusion about the null hypothesis, and final conclusion that addresses the original claim. Use the P-value method and the normal distribution as an approximation to the binomial distribution.
Answers
Answer:
The null hypothesis: \(\mathbf{H_o: p=0.27}\)
The alternative hypothesis: \(\mathbf{H_1: p \neq 0.27}\)
Test statistics : z = −2.30
P-value: = 0.02144
Decision Rule: Since the p-value is lesser than the level of significance; then we reject the null hypothesis.
Conclusion: We accept the alternative hypothesis and conclude that under the same circumstances the proportion of offspring peas will be yellow is not equal to 0.27
Step-by-step explanation:
From the given information:
Let's state the null and the alternative hypothesis;
Since The claim is that 27% of the offspring peas will be yellow.
The null hypothesis state that the proportion of offspring peas will be yellow is equal to 0.27.
i.e
\(\mathbf{H_o: p=0.27}\)
The alternative hypothesis state that the proportion of offspring peas will be yellow is not equal to 0.27
\(\mathbf{H_1: p \neq 0.27}\)
The test statistics:
we are given 437 green peas and 129 yellow apples;
Hence;
\(\hat p = \dfrac{x}{n}\)
where ;
\(\hat p\) = sample proportion
x = number of success
n = total number of the sample size
\(\hat p = \dfrac{129}{437+129}\)
\(\hat p = \dfrac{129}{566}\)
\(\mathbf{\hat p = 0.2279}\)
Now; the test statistics can be computed as :
\(z = \dfrac { \hat p -p }{\sqrt {\dfrac{p(1-p)}{n} } }\)
\(z = \dfrac {0.2279 -0.27 }{\sqrt {\dfrac{0.27(1-0.27)}{566} } }\)
\(z = \dfrac {-0.043 }{\sqrt {\dfrac{0.27(0.73)}{566} } }\)
\(z = \dfrac {-0.043 }{\sqrt {\dfrac{0.1971}{566} } }\)
\(z = \dfrac {-0.043 }{\sqrt {3.48233216*10^{-4} } }\)
\(z = \dfrac {-0.043 }{0.01866} }\)
z = −2.30
C. P-value
P-value = P(Z < z)
P-value = P(Z< -2.30)
By using the P-value method and the normal distribution as an approximation to the binomial distribution.
from the table of standard normal distribution
move left until the first column is reached. Note the value as –2.0
move upward until the top row is reached. Note the value as 0.30
find the probability value as 0.010724 by the intersection of the row and column values gives the area to the left of
z = -2.30
P- value = 2P(z ≤ -2.30)
P-value = 2 × 0.01072
P - value = 0.02144
Decision Rule: Since the p-value is lesser than the level of significance; then we reject the null hypothesis.
Conclusion: We accept the alternative hypothesis and conclude that under the same circumstances the proportion of offspring peas will be yellow is not equal to 0.27
Find the domain of the square root of 2x−10
Answers
♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️
\( f(x) = \sqrt{2x - 10} \)
\(Domain \: \: : \: 2x - 10 \geqslant 0\)
Add sides 10
\(Domain \: \: : \: \: 2x - 10 + 10 \geqslant 10 \\ \)
\(Domain \: \: : \: \: 2x \geqslant 10\)
Divided sides by 2
\(Domain \: \: : \: \: \frac{2}{2}x \geqslant \frac{10}{2} \\ \)
\(Domain \: \: : \: \: x \geqslant 5\)
Done...
♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️♥️