Convert 30 kilograms into gram
Answers
Related Questions
(d) The perimeter of the figure below is equal to 150 cm.
X
x+6
x+5
x+1
x+8
X+4
What is the length of the longest side of the polygon?
Use mathematics to explain how you determined your answer.
Use words, symbols, or both in your explanation.
Answers
Based on the given perimeter of the polygon and the length of each side; the length of the longest side of the polygon is 29 cm
Perimeter of a polygonPerimeter = 150 cmPerimeter of the polygon = x + (x + 6) + (x + 5) + (x + 1) + (x + 8) + (x + 4)
150 = x + x + 6 + x + 5 + x + 1 + x + 8 + x + 4
150 = 6x + 24
150 - 24 = 6x
126 = 6x
x = 126/6
x = 21
The longest side of the polygon is (x + 8)
= 21 + 8
= 29 cm
Learn more about perimeter:
https://brainly.com/question/24571594
#SPJ1
the mean number of pets owned by the population of students at a large high school is 3.2 pets per student with a standard deviation of 1.7 pets. a random sample of 16 students will be selected and the mean number of pets for the sample will be calculated.
Answers
5. Write two expressions for the area of the big rectangle.

Answers
Answer:
Two expressions for the area are;
i) x/3 + 2·y + 6
ii) (1/3) × (x + 6·y + 18)
Step-by-step explanation:
The given dimension of the rectangle are;
The height of the rectangle, h = 1/3
The width of the smallest rectangle, w₁ = x
The width of the med sized rectangle, w₂ = 6·y
The width the large rectangle, w₃ = 18
The area, 'A', of the entire rectangular figure, the big rectangle, can be expressed as follows;
A = A₁ + A₂ + A₃
Where;
A₁ = The area of the smallest rectangle
A₂ = The area of the mid sized rectangle
A₃ = The area of the large rectangle
∴ A = (1/3) × x + (1/3) × 6·y + (1/3) × 18 = x/3 + 2·y + 6
The area of the big rectangle. 'A', can also be found as follows;
A = (1/3) × (x + 6·y + 18)
Therefore, two expressions for the area of the big rectangle are;
x/3 + 2·y + 6 and (1/3) × (x + 6·y + 18).
Solve the equation C^2 =4
Answers
Answer:
2
Step-by-step explanation:
Hey there!
The equation is asking us, c x c = 4
What is c?
Well the only number that is equal to 4 when you square it is 2
Which of the following rational functions is graphed below?
what’s the answer??
Answers
By analyzing the graph's features, you can determine which rational function it represents.
A rational function is a fraction of two polynomial functions, where the denominator is not zero. Rational functions can have vertical asymptotes, where the denominator equals zero and the function is undefined.
They can also have horizontal asymptotes, where the degree of the numerator and denominator functions is equal and the coordinates of the leading term are the same. The graph of a rational function can also have slant asymptotes if the degree of the numerator is one greater than the degree of the denominator.
To determine which rational function is graphed, you need to compare the graph to the standard forms of rational functions. For example, the graph of a rational function y=1/x would have a vertical asymptote at x=0 and would approach the x-axis as it goes to positive and negative infinity. By analyzing the graph's features, you can determine which rational function it represents.
Learn more about coordinates brainly.com/question/16634867
#SPJ11
How do smartphone owners use their smartphones when shopping in a grocery store? A sample of 731 smartphone owners in the United States revealed that 358 use their smartphone to access digital coupons, 355 look up recipes, 234 read reviews of products and brands, and 154 locate in-store items.
a.) For each smartphone user grocery shopping online activity, construct a 95% confidence interval estimate of the population proportion.
b.) What conclusions can you reach concerning how smartphone owners use their smartphones when shopping in a grocery store?
Answers
Using the z-distribution, we have that:
a)
The 95% confidence interval estimate of the population proportion of customers who use their smartphone to access digital coupons is (0.4535, 0.5259).The 95% confidence interval estimate of the population proportion of customers who use their smartphone to access look-up recipes is (0.4494, 0.5218).The 95% confidence interval estimate of the population proportion of customers who use their smartphone to access read reviews is (0.2863, 0.3539).The 95% confidence interval estimate of the population proportion of customers who use their smartphone to access locate items is (0.1811, 0.2403).b) Around 50% of the customers use their cell phones to either access digital coupons or look up recipes, while less than 50% use them to read reviews or locate items.
What is a confidence interval of proportions?A confidence interval of proportions is given by:
\(\pi \pm z\sqrt{\frac{\pi(1-\pi)}{n}}\)
In which:
\(\pi\) is the sample proportion.z is the critical value.n is the sample size.95% confidence level, hence\(\alpha = 0.95\), z is the value of Z that has a p-value of \(\frac{1+0.95}{2} = 0.975\), so \(z = 1.96\).
Also, a sample of 731, hence n = 731.
Item a:
358 use their smartphone to access digital coupons, hence:
\(\pi = \frac{358}{731} = 0.4897\)
The lower limit of this interval is:
\(\pi - z\sqrt{\frac{\pi(1-\pi)}{n}} = 0.4897 - 1.96\sqrt{\frac{0.4897(0.5103)}{731}} = 0.4535\)
The upper limit of this interval is:
\(\pi + z\sqrt{\frac{\pi(1-\pi)}{n}} = 0.4897 + 1.96\sqrt{\frac{0.4897(0.5103)}{731}} = 0.5259\)
The 95% confidence interval estimate of the population proportion of customers who use their smartphone to access digital coupons is (0.4535, 0.5259).
355 use their smartphone to access look up recipes, hence:
\(\pi = \frac{355}{731} = 0.4856\)
The lower limit of this interval is:
\(\pi - z\sqrt{\frac{\pi(1-\pi)}{n}} = 0.4856 - 1.96\sqrt{\frac{0.4856(0.5144)}{731}} = 0.4494\)
The upper limit of this interval is:
\(\pi + z\sqrt{\frac{\pi(1-\pi)}{n}} = 0.4856 + 1.96\sqrt{\frac{0.4856(0.5144)}{731}} = 0.5218\)
The 95% confidence interval estimate of the population proportion of customers who use their smartphone to access look-up recipes is (0.4494, 0.5218).
234 use their smartphone to access read reviews of products, hence:
\(\pi = \frac{234}{731} = 0.3201\)
The lower limit of this interval is:
\(\pi - z\sqrt{\frac{\pi(1-\pi)}{n}} = 0.3201 - 1.96\sqrt{\frac{0.3201(0.6799)}{731}} = 0.2863\)
The upper limit of this interval is:
\(\pi + z\sqrt{\frac{\pi(1-\pi)}{n}} = 0.3201 + 1.96\sqrt{\frac{0.3201(0.6799)}{731}} = 0.3539\)
The 95% confidence interval estimate of the population proportion of customers who use their smartphone to access read reviews is (0.2863, 0.3539).
154 use their smartphone to access locate items, hence:
\(\pi = \frac{154}{731} = 0.2107\)
The lower limit of this interval is:
\(\pi - z\sqrt{\frac{\pi(1-\pi)}{n}} = 0.2107 - 1.96\sqrt{\frac{0.2107(0.7893)}{731}} = 0.1811\)
The upper limit of this interval is:
\(\pi + z\sqrt{\frac{\pi(1-\pi)}{n}} = 0.2107 + 1.96\sqrt{\frac{0.2107(0.7893)}{731}} = 0.2403\)
The 95% confidence interval estimate of the population proportion of customers who use their smartphone to access locate items is (0.1811, 0.2403).
Item b:
Considering if 50% = 0.5 is or is not part of the confidence interval, we have that:
Around 50% of the customers use their cell phones to either access digital coupons or look up recipes, while less than 50% use them to read reviews or locate items.
More can be learned about the z-distribution at https://brainly.com/question/25890103
The number of students in chess club decreased from 49 to 18 what is the percentage decrease
Answers
Explanation: (49 - 18) ÷ 49, based on percentage decrease formula. Which would get you 0.632... and you can round that to 0.63 which would be 63% as a percentage.
(Hope this helps and please mark me as brainliest!)

Answer:
Roughly a 63.2653% decrease
Step-by-step explanation:
63.2653% of 49 is 30.999997
49-30.999997=18.000003
Write each fraction as a mixed number.
3 4/9
43/9
32/5
Answers
The value of the fractions in the mixed fraction form is 3(⁷/₉), 4(⁷/₉), and 6(²/₅) respectively.
What is a mixed fraction?A mixed fraction is a fraction that is created by fusing a fraction with a whole number. The fraction is defined as the division of the whole part into an equal number of parts.
The given fractions 34/9, 43/9, and 32/5 can be written in the form of the mixed fraction as below:-
To write the fractions in the form of the mixed fraction first divide the fraction by the complete number and put the remainder on the numerator.
34/9 = 3(⁷/₉)
43/9 = 4(⁷/₉)
32/5 = 6(²/₅)
Therefore, the value of the fractions in the mixed fraction form is 3(⁷/₉), 4(⁷/₉), and 6(²/₅) respectively.
To know more about a mixed fraction follow
https://brainly.com/question/1746829
#SPJ1
Apply the distributive property to create an equivalent expression. \dfrac12(10x + 20y +10z) = 2 1 (10x+20y+10z)=start fraction, 1, divided by, 2, end fraction, left parenthesis, 10, x, plus, 20, y, plus, 10, z, right parenthesis, equals
Answers
Answer:
The answer is "\(5x+10y+5z\)"
Step-by-step explanation:
Given value:
\(\to \frac{1}{2}(10x + 20y +10z)\)
Using the distributive property.
If there are three integers a,b and c then:
\(a \cdot(b+c) =a \cdot b + a \cdot c\)
\(\to \frac{1}{2}(10x) +\frac{1}{2}(20y+10z)\\\\\to (5x) +\frac{1}{2}(20y+10z)\)
Again apply the distributive property
\(\to (5x) +(10y+5z)\\\\\to (5x+10y+5z)\)
Or
\(\to \frac{1}{2}(10x + 20y +10z)\)
take common 2 from the equation:
\(\to \frac{1}{2}\times 2 (5x + 10y +5z)\\\\\to (5x + 10y +5z)\\\)
Answer:
5x+10y+5z
Step-by-step explanation:
Suppose that X is a Poisson random variable with mean λ. The parameter λ has an exponential distribution with mean 1.
Show that P(X= n) = (1/2)^n-1
Answers
To show that expression P(X=n) = \((1/2)^{(n-1)\), where X is a Poisson random variable with mean λ and λ has an exponential distribution with mean 1, we can use the following steps:
First, we need to find the probability density function of λ, denoted as f(λ), which is given as:
f(λ) = e^(-λ), λ > 0
Since λ has an exponential distribution with mean 1, we have:
λ = E[λ] = 1
Next, we need to find the probability mass function of X, denoted as P(X=n), which is given as:
P(X=n) = e^(-λ) * (λ^n / n!), n = 0, 1, 2, ...
Substituting λ = 1, we get:
\(P(X=n) = e^{(-1)} * (1^n / n!), n = 0, 1, 2, ...\)
Next, we can simplify the expression for P(X=n) by using the property of the exponential function, which is:
\(e^{(-1)\) = 1/e
Substituting this into the previous equation, we get:
P(X=n) = (1/e) * (\(1^n\) / n!), n = 0, 1, 2, ...
Next, we can simplify the expression for P(X=n) by using the property of the factorial function, which is:
n! = n * (n-1)!
Substituting this into the previous equation, we get:
P(X=n) = (1/e) * (1/1) * (1/2) * (1/3) * ... * (1/n), n = 0, 1, 2, ...
Finally, we can simplify the expression for P(X=n) by using the property of the geometric series, which is:
\(1/2 + 1/4 + 1/8 + ... + 1/2^{n-1} = (1/2)^{n-1\)
Substituting this into the previous equation, we get:
P(X=n) = (1/e) * \((1/2)^{n-1\), n = 0, 1, 2, ...
Therefore, we have shown that P(X=n) = \((1/2)^{(n-1)\), where X is a Poisson random variable with mean λ and λ has an exponential distribution with mean 1.
For more details regarding exponential distribution, visit:
https://brainly.com/question/22692312
#SPJ1
Find the equation of the plane passing P(1,2,1) and is orthogonal to the two planes: x-y-z-10 = 0, x-2y + z-2=0.
Answers
The equation of the plane passing P (1,2,1) and orthogonal to the two planes: x-y-z-10 = 0, x-2y + z-2=0 is -3x-2y-z+8=0.
Equation of plane passing through (x1,y1,z1) is given by
A(x-x1)+B(y-y1)+C(z-z1)=0
where, A, B, and C are direction ratios
In the question, it is given that the plane passes through (1,2,1)
So, the equation of the plane will be in the form,
A(x-1)+B(y-2)+C(z-1)=0
It is also given that the plane is perpendicular to give 2 planes.
So, their normal to the plane would be perpendicular to the normal of both planes.
So, the required normal is a cross-product of the normals of planes
x-y-z-10=0 and x-2y+z-2=0
i.e,
-3i-2j-k=0
so, the direction ratios,
A=-3, B=-2, C=-1
putting the direction ratios in the previous equation of the plane,
-3(x-1)-2(y-2)-1(z-1)=0
-3x+3-2y+4-z+1=0
-3x-2y-z+8=0
is the required equation of the plane
Learn more about the equation of the plane on
https://brainly.com/question/27190150?referrer=searchResults
#SPJ4
If the labor force of 165 million people is growing by 1.2 percent this year, how many new jobs have to be created each month to keep unemployment from increasing?
Answers
0.165 million jobs must be created monthly to keep unemployment from increasing.
What is the labor force?The combined employed and unemployed population makes up the labor force. The labor force as a percentage of the civilian noninstitutional population is the labor force participation rate.The number of employed persons plus the number of jobless people seeking work is known as the labor force. 1 The unemployed who are not looking for work are not included in the labor pool. For instance, stay-at-home mothers, retirees, and students are not employed.An economy's labor force is calculated as the sum of employed and jobless citizens. As a result, the labor force can be calculated using the formula: labor force = employed population + unemployed population.All employees are included in the labor force, including persons looking for work who are unemployed and the companies who pay their workers. A job seeker would not be regarded as an employee even if she were included in the labor force.How many new jobs have to be created each month to keep unemployment from increasing?
The population of the labor force = is 165 million
Percentage increase of labor force in a year = 1.2 % of 165 million
Percentage increase in the labor force in a month 1.2 %/12=0.1 %= of 155 million
Jobs required to be created each month = population increase each month
165 million *0.1/100=0.165 million
0.165 million jobs must be created monthly to keep unemployment from increasing.
To learn more about the labor force, refer to:
https://brainly.com/question/8340650
#SPJ4
A winter recreational rental company is fencing in a new storage area. They have two options. They can set it up at the back corner of the property and fence it in on four sides. Or, they can attach it to the back of their building and fence it in on three sides. The rental company has decided that the storage area needs to be 100 m2 if it is in the back corner or 98 m2 if it is attached to the back of the building. Determine the optimal design for each situation.
Answers
Answer:
Rectangular area attached to the back of the building
two sides of legth 7 m and one side of 14 m
Step-by-step explanation:
We need to compare quantity of fencing material to be used in both cases
1.Option
A = 100 m² dimensions of storage area "x" and "y"
x*y = 100 y = 100/x
The perimeter of the storage area is
p = 2*x + 2*y ⇒ p = 2*x + 2*100/x
p(x) = 2*x + 200/x
Taking drivatives on both sides of the equation
p´(x) = 2 - 200/x²
p´(x) = 0 ⇒ 2 - 200/x² = 0
2*x² - 200 = 0 x² = 100
x = 10 m
and y = 100/10
y = 10 m
Required fencing material in first option
2*10 + 2*10 = 40 m
2.-Option
Following the same procedure
A = 98 m² y = A/x y = 98/x
p = 2*x + y p(x) = 2*x + 98/x
p´(x) = 2 - 98/x² p ´(x) = 0
2 - 98/x² = 0
2*x² = 98 x² = 49
x = 7 m and y = 98/ 7 y = 14 m
Total quantity of fencing material
p = 2* 7 + 14 p = 28
Therefore option 2 is more convinient from economic point of view
Optimal design rectangular storage area with two sides of 7 m and one side of 14 m
Hey loves!!! Plz help if you have the time.<3

Answers
Answer:
The first and last answer.
Step-by-step explanation:
If you look closely at the triangles you can tell which ones are the same and which differ.
Hope this helps!! <3
f(x) = -x^2 + 4x + 10
Find f(-6)
PLEASE HELP ASAP.

Answers
F(x)=-36-24+10
F(-6)=-50
Each table in a library can seat up to 5 people. There are enough tables for 75 people. How many tables are there in the library?
Answers
Answer:
15 tables
Step-by-step explanation:
75/5 = 15
Answer:
There are 15 tables in the library.
Step-by-step explanation:
You know this because you know the library holds 75 people and you know how many people can sit at a table so to find the answer you divide 75 by 5 and you get 15. To check this you can multiply 15 by 5 and you will get 75.
Bell Work
You Do
Camspite A is 5 miles north and 2 miles east of a ranger station.
Campsite B is 8 miles north and 6 miles east of the ranger station.
How far is Campsite A from Campsite B?
A 1 mi
B 5 mi
7 mi
25 mi
Answers
7 i do not feel like explaining tbh
please help!!!!!!!!!!!!!
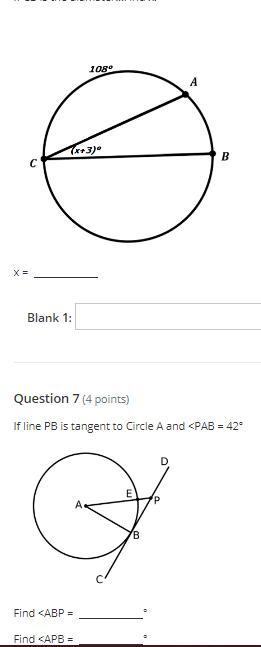
Answers
Answer:-3
Step-by-step explanation: -3 because when you do it I really don't know how to explain it srry
Colton's mini-van is depreciating at a rate of 5.5% per year. He paid $22,250 for it in 2019. How much will the car be worth in 2025 to nearest cent?
Answers
Answer:
$1584.2
Step-by-step explanation:
Given data
R= 5.5%
T= 2025-- 2019= 6years
P= $22,25
Let us apply Compound interest formula
A=P(1-r)^r ------------Note negative for depreciation
A= 2225(1-0.055)^6
A= 2225(0.945)^6
A= 2225*0.712
A=$1584.2
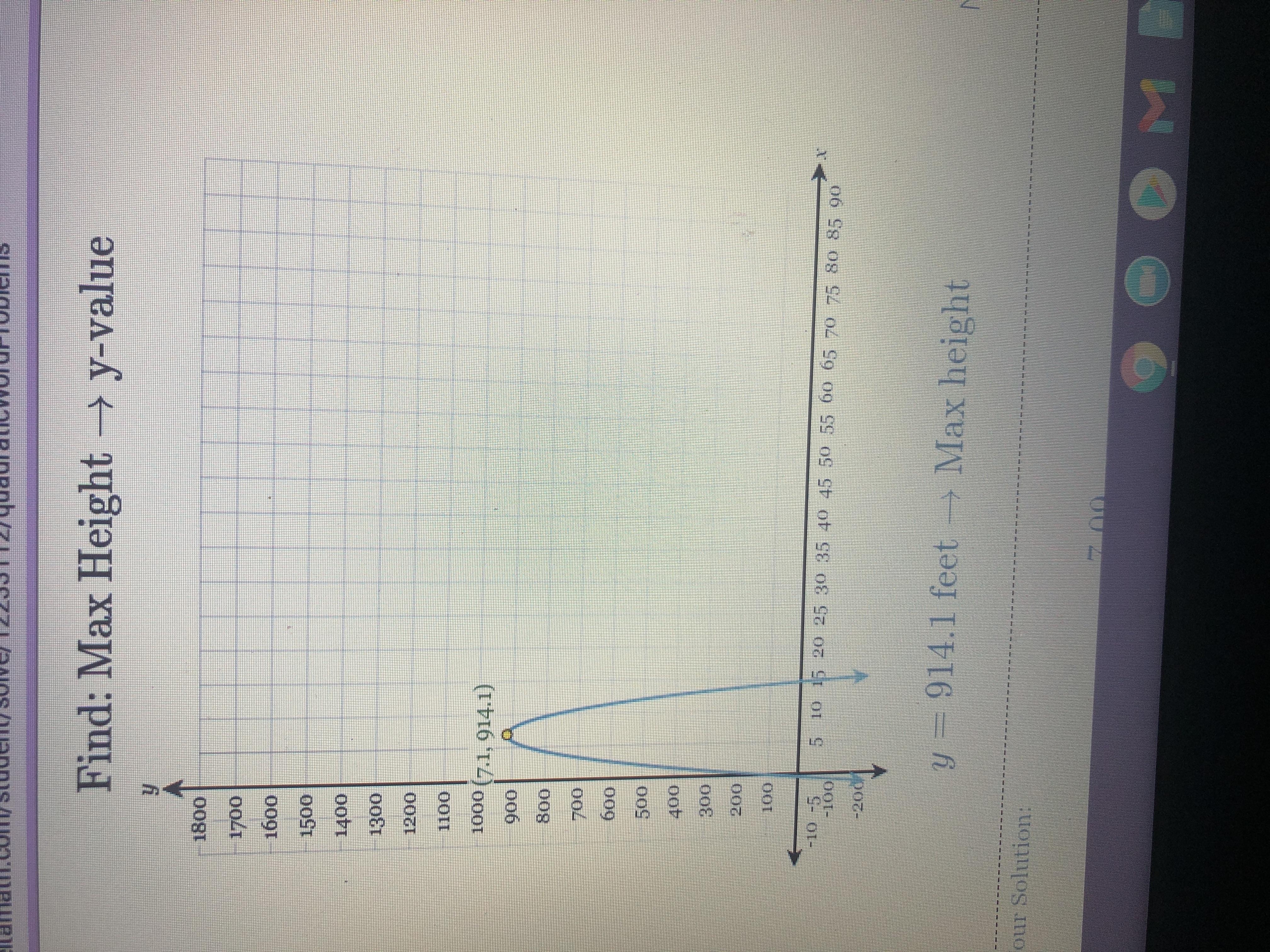
A rocket is launched from a tower. The height of the rocket, y in feet, is related to the time after launch, x in seconds, by the given equation. Using this equation, find the maximum height reached by the rocket, to the nearest tenth of a foot. y=-16x^2+227x+109
Answers
Answer: y=914.1 feet max height
Step-by-step explanation:
A candy dish is filled with a mix of yellow and pink jelly beans Brian and Ali take turns picking a jelly bean without looking are these 2 events dependent or independent
Answers
Given:
Brian and Ali take turns picking a jelly bean without looking
Required: Dependent or independent event
Explanation:
Brian picked a jelly bean first and after Ali picked second. The probability of Ali picking up depends on the jelly bean.
Hence the events are depndent.
Final Answer: Dependent events
Let A and B be arbitrary matrices for which the indicated product is defined. Determine whether the statement below is true or false. Justify the answer. (AB)^T = A^TB^T A. The statement is true. The transpose of the product of two matrices is the product of the transposes of the individual matrices in the same order, or (AB)^T = A^TB^T B. The statement is false. The transpose of the product of two matrices is the product of the transposes of the individual matrices in reverse order, or (AB)^T=B^TA^T
C. The statement is false. The transpose of the product of two matrices is the product of the transpose of the first matrix and the second matrix, or (AB)^T = A^TB. D. The statement is true. Matrix multiplication is not commutative so the products must remain in the same order.
Answers
B. The statement is false. The transpose of the product of two matrices is the product of the transposes of the individual matrices in reverse order, or (AB)^T=B^TA^T.
Justification:
1. Let A and B be arbitrary matrices for which the product AB is defined.
2. To find the transpose of the product (AB)^T, we need to first understand the properties of transposes.
3. According to the property of transposes, (AB)^T is equal to the product of the transposes of the individual matrices in reverse order.
4. So, (AB)^T = B^TA^T, which contradicts the statement (AB)^T = A^TB^T.
Hence, the correct answer is option B.
Learn more about Matrices here: brainly.com/question/11367104
#SPJ11
When conducting a test for the difference of means for two independent populations x1 and x2, what alternate hypothesis would indicate that the mean of the x2 population is smaller than that of the x1 population
Answers
The alternate hypothesis that indicates the mean of the x2 population is smaller than that of the x1 population is H1: μ2 < μ1, which can be tested using a two-sample t-test.
When conducting a test for the difference of means for two independent populations x1 and x2, the alternate hypothesis that would indicate that the mean of the x2 population is smaller than that of the x1 population is:
H1: μ2 < μ1
Where H1 represents the alternate hypothesis, μ1 represents the mean of population x1, and μ2 represents the mean of population x2. The symbol "<" indicates that the mean of population x2 is smaller than the mean of population x1.
In other words, this alternate hypothesis states that there is a significant difference between the means of the two populations, with the mean of population x2 being lower than the mean of population x1. This hypothesis can be tested using a two-sample t-test, where the null hypothesis assumes that there is no significant difference between the means of the two populations.
To know more about alternate hypothesis, refer to the link below:
https://brainly.com/question/30535681#
#SPJ11
Rolling a fair six-sided die is supposed to randomly generate the numbers 1 through 6. Explain what random means in this context.
Answers
Rolling a fair six-sided die is supposed to randomly generate the numbers 1 through 6, then the random in this context is option (D) That in the long run, a fair die will produce roughly equal amounts of the numbers 1 through 6 when rolled. But for each roll each value 1 through 6 is equally likely.
Here a six sided die is rolling fairly
The sample space = { 1,2,3,4,5,6}
Sample space of the experiment is the all the possible outcomes of the experiment.
Here 1, 2, 3, 4, 5 and 6 are the random outcomes of the experiment
Hence, rolling a fair six-sided die is supposed to randomly generate the numbers 1 through 6, then the random in this context is option (D) That in the long run, a fair die will produce roughly equal amounts of the numbers 1 through 6 when rolled. But for each roll each value 1 through 6 is equally likely.
The complete question is:
Rolling a fair six-sided die is supposed to randomly generate the numbers 1 through 6. Explain what random means in this context? Choose the correct answer below.
a. That if a 1 is rolled it that means that each other number was not rolled.
b. That the only possible outcomes are 1, 2, 3, 4, 5, and 6.
c. That each result will not be influenced by the previous result of the die roll.
d. That in the long run, a fair die will produce roughly equal amounts of the numbers 1 through 6 when rolled. But for each roll each value 1 through 6 is equally likely.
Learn more about sample space here
brainly.com/question/14641917
#SPJ4
The line produced by the equation Y=4X−5 crosses the vertical axis at Y=5 .a. True.b. False.
Answers
false. The vertical axis is the y-axis, which is where x=0. In this equation, when x=0, we have: y=4(0)-5
y=-5
Therefore, the line produced by the equation Y=4X−5 crosses the vertical axis at y=-5, not y=5.
To further understand this concept, we can visualize the equation on a graph. When we plot the points (0,-5) and (1,-1) (which is found by substituting x=1 into the equation), we can draw a line that passes through both points. This line is the graph of the equation Y=4X−5. We can see that the line crosses the vertical axis (y-axis) at y=-5, which confirms that the answer is false.
In summary, the equation Y=4X−5 crosses the vertical axis (y-axis) at y=-5, not y=5.
Learn more about vertical axis here:
https://brainly.com/question/29670302
#SPJ11
some researchers claim that there is not much difference between qualitative and quantitative data. please select the best answer from the choices pro
Answers
The claim that there is not much difference between qualitative and quantitative data is incorrect.
Qualitative and quantitative data are two distinct types of data that serve different purposes and have different characteristics.
Qualitative data refers to non-numerical information that is typically obtained through observations, interviews, or surveys. It provides insights into opinions, attitudes, behaviors, and subjective experiences. Qualitative data is often descriptive in nature, expressed in words, narratives, or themes. It allows researchers to explore complex phenomena, understand contextual factors, and capture the richness of human experiences. Examples of qualitative data include interview transcripts, field notes, and open-ended survey responses.
On the other hand, quantitative data is numerical in nature and involves the collection and analysis of measurable variables. It focuses on quantities, statistical analysis, and mathematical modeling. Quantitative data allows researchers to quantify relationships, make predictions, and conduct statistical tests. It is often collected through surveys, experiments, or structured observations. Examples of quantitative data include numerical measurements, survey responses on a Likert scale, and statistical values such as means and standard deviations.
In conclusion, qualitative and quantitative data are distinct in their characteristics, purpose, and analytical approaches. The claim that there is not much difference between them is incorrect.
Learn more about qualitative and quantitative data
brainly.com/question/17313620
#SPJ11
What is the value of f -1 (12)

Answers
-1 us a answer for your questions or support
Cost price = $780. Selling price = $707.85. Find the loss as a percentage of the cost price.
Answers
Answer:
loss % = 9.25%
Step-by-step explanation:
loss % = 100 × loss / cost price
loss % = 100 × ($780 - $707.85) / $780
loss % = 100 × $72.15 / $780
loss % = 9.25%
plz follow me
..What is the sum.. please help me and dont guess on this is important (will give braniliest) Please help ;((.

Answers
Answer:
-2 3 / 7 is the answer to this question
I WILL GIVE YOU THE BRAINIEST!!!
In a company, 60% of the workers are Men. If 2,320 people work for the company who aren't men, how many workers are there in all?
If Right.
Answers
Answer: 1392 people who work for the company are men.
I did this by multiplying 2320 by 0.6, which got me my answer.
Have a great day!
Stay safe and healthy!
Happy holiday seasons!
May I please have brainliest?