For each solution, write a different equation with that solution.
1. C=6
2. C=0.1
Answers
The solution for each equation is 3C - 18 = 0 and 10C - 1 = 0
Given data ,
C = 6
Equation: 3C - 18 = 0
Explanation: If C = 6, we can substitute this value into an equation to create a new equation. Here, we multiply 3 by C and subtract 18 to get 0.
This equation indicates that if C is 6, then 3 times 6 minus 18 equals 0, resulting in a true statement.
C = 0.1
Equation: 10C - 1 = 0
Explanation: If C = 0.1, we can substitute this value into an equation to create a new equation. Here, we multiply 10 by C and subtract 1 to get 0.
This equation indicates that if C is 0.1, then 10 times 0.1 minus 1 equals 0, resulting in a true statement.
To learn more about equations click :
https://brainly.com/question/19297665
#SPJ1
Related Questions
Represent the following sentence as an algebraic expression, where "a number" is the letter x. \text{a number raised to the third power.} a number raised to the third power.
Answers
Answer: #x^3
Step-by-step explanation:
"A number " is represented by the letter xA number (x) raised (^) the third power will be,x^3
note: An algebraic expression doesn't have an equal sign (=)
Know more about algebraic expressions here:
https://brainly.com/question/6566332
https://brainly.com/question/12470265
Calculate the distance between the points =G−9, 6 and =Q−2, 1 in the coordinate plane.
Answers
The distance between the points G(-9, 6) and Q(-2, 1) in the coordinate plane is approximately 8.6.
To calculate the distance between two points in a coordinate plane, we can use the distance formula. The distance formula is derived from the Pythagorean theorem and can be stated as follows:
Distance = sqrt((x2 - x1)^2 + (y2 - y1)^2)
In this case, the given points are G(-9, 6) and Q(-2, 1).
Step 1: Identify the coordinates of the two points.
G has coordinates (-9, 6) and Q has coordinates (-2, 1).
Step 2: Substitute the coordinates into the distance formula.
Using the distance formula, we can plug in the values as follows:
Distance = sqrt((-2 - (-9))^2 + (1 - 6)^2)
Simplifying the formula:
Distance = sqrt((7)^2 + (-5)^2)
Distance = sqrt(49 + 25)
Distance = sqrt(74)
Step 3: Calculate the square root.
Taking the square root of 74, we get:
Distance ≈ 8.6
For more such questions on approximately
https://brainly.com/question/29985480
#SPJ8
Teresa finished her math test in 3/4 hour. Lamar finished his test in 2/3 hour.in how less time did Lamar finish his test compared to Teresa?
Answers
Answer:
5 minutes or 1/12 of an hour.
Step-by-step explanation:
3/4 of an hour is 45 minutes.
2/3 of an hour is 40 minutes.
45-40 = 5 minutes or 1/12 of an hour.
find a general solution to the given differential equation. z''+z'-9z=0
Answers
The general solution to the given differential equation is z(t) = C1*\(e^{(3t)}\) + C2*\(e^{(-3t)}\)
The given differential equation is a second-order linear homogeneous differential equation, which can be written as:
z'' + z' - 9z = 0
To find the general solution, we first need to solve the characteristic equation:
\(r^2\) + r - 9 = 0
By factoring or using the quadratic formula, we find the roots r1 and r2:
r1 = 3
r2 = -3
Since we have two distinct real roots, the general solution of the differential equation is:
z(t) = C1 * \(e^{(r1t)}\) + C2 * \(e^{(r2t)}\)
z(t) = C1 * \(e^{(3t)}\) + C2 * \(e^{(-3t)}\)
where C1 and C2 are arbitrary constants determined by initial conditions.
Know more about Differential equation here :
https://brainly.com/question/28099315
#SPJ11
6. The police department of a major city has found that the average height of
their 1,250 officers is 71 inches, with a standard deviation of 2.3 inches. Using
the normal curve table, answer the following:
a. How many officers are at least 75 inches tall?
b. How many officers are between 65 and 72 inches tall?
c. If an officer is at the 35th percentile in terms of height, how tall is she or he?
d. Assuming an equal amount of service, the top 10% of the police officers in
terms of height also make higher salaries than their less favored fellow of-
ficers. How tall does an officer have to be to get a better salary?
e. What is the probability of encountering an officer who is 66 inches tall or
less?
f. What heights are so deviant that their probability of occurrence is .05 or
less?
Answers
Answer:
c
Step-by-step explanation:
The graph of a function is a line that passes through the coordinates
(6,6) and (7.15) Which is the rate of change for the function?
Answers
Answer:
The rate of change of the function is 9
Step-by-step explanation:
Mathematically, the rate of change of the function refers to the slope of the line that passes through the given points
Thus, we use the slope equation as follows;
m = (y2-y1)/(x2-x1)
(x1,y1) = (6,6)
(x2,y2) = (7,15)
Substituting these values, we have
m = (15-6)/(7-6) = 9/1 = 9
Proof Prove that if S = {v1, v2, …, vn} is a basis for a vector space V and c is a nonzero scalar, then the set S1 = {cv1, cv2, …, cvn} is also a basis for V.
Answers
1. Linear independence:
Suppose we have a linear combination of elements in S1 equal to the zero vector:
a1(cv1) + a2(cv2) + ... + an(cvn) = 0
Since c is a nonzero scalar, we can factor it out:
c(a1v1 + a2v2 + ... + anvn) = 0
Since S is a basis for V, it is linearly independent, and this linear combination implies that a1 = a2 = ... = an = 0. Therefore, S1 is also linearly independent.
2. Spanning V:
Given any vector v in V, we know that v can be expressed as a linear combination of the vectors in S since S spans V:
v = b1v1 + b2v2 + ... + bnvn
Now, multiply both sides by the nonzero scalar c:
cv = (cb1)(cv1) + (cb2)(cv2) + ... + (cbn)(cvn)
This expression shows that cv can be formed as a linear combination of the vectors in S1. Since c is a nonzero scalar, every vector in V can be obtained by a linear combination of vectors in S1, so S1 spans V.
To prove that S1 = {cv1, cv2, …, cvn} is also a basis for V, we need to show that S1 is linearly independent and spans V.
First, we will show that S1 is linearly independent. Suppose there exist scalars a1, a2, …, an such that
a1(cv1) + a2(cv2) + … + an(cvn) = 0
Multiplying both sides by c, we get
(ca1)v1 + (ca2)v2 + … + (can)vn = 0
Since S is a basis for V, it is linearly independent. Therefore, the only solution to the above equation is a1 = a2 = … = an = 0. This implies that S1 is also linearly independent.
Next, we will show that S1 spans V. Let v be any vector in V. Since S is a basis for V, we can express v as a linear combination of its elements:
v = b1v1 + b2v2 + … + bnvn
Multiplying both sides by c, we get
cv = (cb1)cv1 + (cb2)cv2 + … + (cbn)cvn
This implies that S1 spans V.
Therefore, we have shown that S1 = {cv1, cv2, …, cvn} is a basis for V.
Learn more about Linearly Independent:
brainly.com/question/31233178
#SPJ11
A pizza lover wants to compare the average delivery times for four local pizza restaurants. Over the course of a few weeks, he orders a number of pizzas from each restaurant, and he records the time it takes for each pizza to be delivered.
a) When performing an ANOVA with this data, what is the alternative hypothesis?
- All of the restaurants have different mean delivery times
- At least two of the restaurants have different mean delivery times
- Two of the restaurants have different mean delivery times
- One of the restaurants has a different mean delivery time than the others
b) A partial ANOVA table for his data is shown below. What is the value of B?
Source DF SS MS F P-value
Treatment B 19.31 D F G
Error C 15.667 E
Total 18 34.977
What is the value of C in the ANOVA table?
d) What is the value of D in the ANOVA table? Give your answer to three decimal places.
e) What is the value of E in the ANOVA table? Give your answer to three decimal places.
f) What is the value of F in the ANOVA table? Give your answer to two decimal places.
g) What is the value of G in the ANOVA table? Give your answer to four decimal places.
h) Using a 0.1 level of significance, what should his conclusion be in this case?
- He should conclude that at least two of the restaurants have different mean delivery times because the P-value is less than 0.1.
- He should fail to reject the claim that at all of the restaurants have the same mean delivery times because the P-value is greater than 0.1.
- He should conclude that at least two of the restaurants have different mean delivery times because the P-value is greater than 0.1.
- He should conclude that at all of the restaurants have the same mean delivery times because the P- value is less than 0.1.
Answers
(a) When performing an ANOVA with the data the alternative hypothesis is at least two of the restaurants have different mean delivery times.
(b)75.8
Analysis of variance. or ANOVA, is a statistical method that separate observed variance data into different components to use for additional tests. A one way ANOVA is used for three or more groups of data, to gain information about the relationship between the dependent and independent variables.
The ANOVA table shows how the sum of squares are distributed according to source of variation, and hence the mean sum of squares.
It is given that a pizza lover wants to compare the average delivery times.
Therefore the null hypothesis and alternate hypothesis implies that,
H₀ = all restaurants have equal mean delivery time
Hₐ = at least two restaurants have different two deliveries
Hence the alternate hypothesis for performing an ANOVA with the data is at least two of the restaurants have different mean delivery times.
The alternate hypothesis (Hₐ) defines that there is a statistically important relationship between two variables. Whereas null hypothesis states that is no statistical relationship between the two variables.
To know more about hypothesis here
https://brainly.com/question/14517618
#SPJ4
Please help!
Write the expression as a power of a:
(a^5)2
Answers
See attachment for math work and answer.

The price of a Rolex watch in 1964 was $500. today the price of a Rolex watch is $5,000. What can we determine from this? A. Rolex watches are more expensive than they were in 1964
B. there has been 1000% inflaiton C. Nothing we cannot compare two nominal variables D. Rolex watches must be nicer today than in 1964
Answers
From the given statement, "The price of a Rolex watch in 1964 was $500. Today the price of a Rolex watch is $5,000," we can determine that Rolex watches are more expensive than they were in 1964.
Therefore, the correct option is A. Rolex watches are more expensive than they were in 1964.What is inflation?Inflation refers to the rate at which prices for goods and services rise and, as a result, money loses value. The consumer price index (CPI), which measures the changes in the prices of a basket of goods and services used by households, is the most common measure of inflation.
What is nominal variable?A nominal variable is one in which the values are categories. Nominal variables are qualitative variables, which means they describe a characteristic or attribute of the subject. Examples include gender, race, nationality, and religion.
To know more about Rolex visit:
https://brainly.com/question/11168707
#SPJ11
What sample size is needed to obtain a 90 percent confidence interval for the mean protein content of meat if the estimate is to be within 2 pounds of the true mean value? Assume that the variance is 49 pounds.
Answers
Thus, we need a sample size of at least 22 to obtain a 90 percent confidence interval for the mean protein content of meat with an estimate within 2 pounds of the true mean value.
To obtain a 90 percent confidence interval for the mean protein content of meat with an estimate within 2 pounds of the true mean value, we need to calculate the required sample size. The formula for the required sample size is:
n = (Zα/2 * σ / E)^2
where n is the required sample size, Zα/2 is the z-score for the desired confidence level (in this case 90%), σ is the standard deviation of the population (in this case 7 pounds, the square root of the variance), and E is the margin of error (in this case 2 pounds).
Plugging in the values, we get:
n = (1.645 * 7 / 2)^2
n = 21.16
Therefore, we need a sample size of at least 22 to obtain a 90 percent confidence interval for the mean protein content of meat with an estimate within 2 pounds of the true mean value. It is important to note that this assumes that the sample is drawn randomly and is representative of the population.
Know more about the confidence interval
https://brainly.com/question/20309162
#SPJ11
What can you say about a sample mean or a sample proportion being about 2 ses away from the population mean or the true proportion? what can you not say?
Answers
When we have a normal model for the sampling distribution, we cannot say that a sample mean or sample proportion is approximately 2 standard errors (ses) away from the population mean or the true proportion.
Instead, we can say that 95% of the sample proportions fall within two standard errors of the population proportion. Similar to this, the percentage of sample proportions decreases as the standard error distance decreases and increases as the standard error distance increases.
Therefore, the standard error distance will be greater than 2 standard errors (ses) if 99% of the sample proportions are within a given standard error distance of the population proportion.
Find more on sample proportion at : brainly.com/question/24232216
#SPJ4
Given the horizontal lines are parallel, find the value of x and y in the pic below

Answers
Answer:
The answer is 15 and 10
Step-by-step explanation:
HELP PLZ!!!! I BEG YOU PLZ!!!!! HURRY!!! FACTS!!! I'll GIVE BRAINLYEST!!!! 10 POINTS!!!!
Which transformation were used to create triangle J'K'L?
(There is no picture that comes with it!!!)
A. dilation by a scale factor of 2 and a rotation of 90(degrees) clockwise about the origin.
B. dilation by a scale factor of 1/2 and a reflection across the x-axis
C. dilation by a scale factor of 2 and a rotation of 90(degrees) counter-clockwise about the origin
D. dilation by a scale factor of 1/2 and a reflection across the y-axis
Answers
Answer:
i believe it's a-dilation by a scale factor of 2 and a rotation of 90(degrees) clockwise about the origin.
Step-by-step explanation:
hope this helps u, sorry if it doesn't.
Answer:
probably dilation by a scale factor of 2 and a rotation
of 90° counter-clockwise about the origin
Step-by-step explanation:
Someone help me with this

Answers
answer:
choose A
choose B
Educational Technology Inc. sells software to provide guided homework problems for a statistics course. The company would like to know if students who use the software score better on exams. A sample of students who used the software had the following exam scores: 86, 78, 66, 83, 84, 81, 84, 109, 65, and 102. Students who did not use the software had the following exam scores: 91, 71, 75, 76, 87, 79, 73, 76, 79, 78, 87, 90, 76, and 72. Assume the population standard deviations are not the same. At the alpha = .10 significance level, can we conclude that there is a difference in the mean scores for the two groups of students
a. What are the three assumptions for CASE C?
b. State the null and alternative hypothesis for this problem.
c. State the level of significance for this problem.
d. Which distribution (normal or t) should be used in this problem? Explain why.
e. Create a decision rule for this problem. Include the critical value. (USE TEXTBOOK TABLE.) Make sure it agrees with the excel printout.
f. Calculate the test statistic. (BY HAND). Make sure it agrees with the excel printout.
g. What is your conclusion? EXPLAIN IN DETAIL.
h. Estimate the p-value for this problem. Restate the conclusion. What is the actual p-value from the excel printout?
Answers
The assumptions in each case of this statistics problem is given as follows:
Samples are independent and samples are simple random samplesDistribution is normal (t distribution)The independent variable measures on interval scale.What is the Decision?ts < tc Do not reject H0
What is the P value?P value > α Do not reject H0
There is insufficient data to determine that the mean scores of the two groups of pupils differ.
Learn more about statistics at;
https://brainly.com/question/15525560
#SPJ1


A research survey of 2,006 public and private school students in the United States (grades
10-12) between April 12 and June 12, 2016 asked students if they agreed with the Statement, "If I make a mistake, I try to figure out where I went wrong." The survey found that 86% students agreed with the statement. The margin of error for the survey is ‡3.7%. Determine the range of surveyed students that agreed with the statement.
Answers
Answer: the range of surveyed students that agreed with the statement is between 82.3% and 89.7%.
Step-by-step explanation: The present study's margin of error has been estimated as ±3.7%. This indicates that the reported proportion of 86% of students who concurred with the statement may exhibit a margin of error of ±3.7%, encompassing potential values lower or higher than the reported percentage figure.
To ascertain the range of students surveyed who assented to the given statement, it is essential to ascertain the uppermost and lowermost attainable percentages that the factual percentage could reveal.
The maximum attainable percentage is equivalent to the sum of 86% and 3.7%, which yields a total of 89.7%.
The minimum percentage attainable has been calculated to be 82.3% by subtracting 3.7% from the initial value of 86%. Such a formulation adheres to the precision and technical accuracy expected in academic writing.
10. Evaluate (14-2)÷3(2-3) - 2²Mark only one oval.A. OB. 2C. 20D. 22

Answers
Order of the operations: parentheses, exponentials, division and multiplication, addition and subtraction.
1. Solve operations in parentheses:
\(=12\div3\cdot6-2^2\)2. Solve exponentials:
\(=12\div3\cdot6-4\)3. Solve division:
\(=4\cdot6-4\)4. Solve multiplication:
\(=24-4\)5. Solve subtraction:
\(=20\)Then, the solution for the given expression is 20Answer: Answer is 20( please make me brainliest i just did this all in my head)
Step-by-step explanation: soo (14-2) =12 12divided by 3=4 so (2*3)= 6 so 4x6=24 24-2*2 =20 (2*2)=4 so 24-4=20 well this is confusing but i tried my best so hope my answer wasn't toooo confusing lol :)
Suppose a research repot has estmated the demand for a frm's prodact as in O
X
d
=7−15 in P
X
+2 in Py=05 in M+ in A where:
P
X
=$15
P
y
=$6
M−$40000, and
A=$350
a Determine the ownt price elasticity of demand, and state whether demard is elassc, inelastic, ar untary elartic: Own price elasticty Demand is b. Determine Bre cross-pice elasticfy of demand between good X and goed Y, and state whetfer these two goods are sibstitutes or campleinents. Cross gnice efasticfly These two goods are: C. Determine the income elasticity of demand, and state whesher good X1 s a normal or inferior good. lncome elassicity? Good X is: 4. Determine the own advertising elasticity of demand.
Answers
a. Own Price Elasticity of Demand = (-30) / (0) = undefined. Since the own price elasticity of demand is undefined, we cannot determine if the demand is elastic, inelastic, or unitary elastic based on this information.
b. Cross-Price Elasticity of Demand = (12/7) / 0 = undefined. Since the cross-price elasticity of demand is undefined, we cannot determine if goods X and Y are substitutes or complements based on this information.
c. Income Elasticity of Demand = (-2860.71) / (0) = undefined. Since the income elasticity of demand is undefined, we cannot determine if good X is a normal or inferior good based on this information.
d. We cannot calculate the own advertising elasticity of demand with the provided data.
a. To determine the own price elasticity of demand, we need to use the formula:
Own Price Elasticity of Demand = (% Change in Quantity Demanded) / (% Change in Price)
Given the demand equation OXd = 7−15PX+2Py+0.5M+A, we can calculate the derivative of demand with respect to price:
d(OXd) / d(PX) = -15
Now, let's plug in the values:
% Change in Quantity Demanded = (d(OXd) / d(PX)) * (PX / OXd) = (-15) * (15 / 7) = -30
% Change in Price = (ΔPX / PX) = (15 - 15) / 15 = 0
b. To determine the cross-price elasticity of demand between goods X and Y, we use the formula:
Cross-Price Elasticity of Demand = (% Change in Quantity Demanded of Good X) / (% Change in Price of Good Y)
Using the same demand equation, we calculate the derivative of demand with respect to the price of good Y:
d(OXd) / d(Py) = 2
Now, let's plug in the values:
% Change in Quantity Demanded of Good X = (d(OXd) / d(Py)) * (Py / OXd) = (2) * (6 / 7) = 12/7
% Change in Price of Good Y = (ΔPy / Py) = (6 - 6) / 6 = 0
c. To determine the income elasticity of demand, we use the formula:
Income Elasticity of Demand = (% Change in Quantity Demanded) / (% Change in Income)
Using the same demand equation, we calculate the derivative of demand with respect to income:
d(OXd) / d(M) = 0.5
Now, let's plug in the values:
% Change in Quantity Demanded = (d(OXd) / d(M)) * (M / OXd) = (0.5) * (-40000 / 7) = -2860.71
% Change in Income = (ΔM / M) = (-40000 - (-40000)) / (-40000) = 0
d. The own advertising elasticity of demand measures the responsiveness of quantity demanded to changes in advertising expenditure. Unfortunately, the given demand equation does not provide any information about advertising expenditure or its impact on quantity demanded.
For more such questions on Elasticity of Demand
https://brainly.com/question/14274996
#SPJ8
An operating characteristic curve is based on a(n) ________ probability distribution. a. uniform b. normal c. exponential d. binomial
Answers
An operating characteristic curve is based on a(n) binomial distribution probability.
According to the statement
we have given that the an operating characteristic curve and we have to tell the name of the probability based on the this curve is called.
So, For this purpose, we know that the
The binomial distribution is a probability distribution that summarizes the likelihood that a value will take one of two independent values under a given set of parameters or assumptions.
And in this type of probability, it is given by a characteristics curve and The binomial distribution model allows us to compute the probability of observing a specified number of "successes" when the process is repeated
So, this is called the binomial distribution probability.
So, An operating characteristic curve is based on a(n) binomial distribution probability.
Learn more about binomial distribution probability here
https://brainly.com/question/9325204
#SPJ4
The number of CDs per hour that Snappy Hardware can manufacture at its plant is given by P=064 where x is the number of workers at the plant and y is the monthly budget in dollars. Assuming that P is constant.compute dy/d when w100 and y 120,000, Coninuing with the previous problem,give an interpretation in 3 parts of the value you computed in terms of CDs produced by Snoppy Hardware.
Answers
The value of dy/d in this case represents the rate of change in the monthly budget required to maintain a constant production level of CDs.
When w100 and y 120,000, dy/d can be computed by taking the partial derivative of the given equation with respect to y: dy/d = -0.64/x. Plugging in the given values, we get dy/d = -0.0064.
1. If the monthly budget is increased by $1, Snappy Hardware can manufacture 0.0064 fewer CDs per hour while maintaining the same number of workers.
2. If the number of workers is increased by 1, Snappy Hardware can manufacture an additional 0.0064 CDs per hour while maintaining the same monthly budget.
3. If Snappy Hardware wants to maintain a constant production level of CDs, they need to decrease their monthly budget by $156,250 for every 10,000 CDs they want to produce per hour.
To know more about partial derivative click on below link:
https://brainly.com/question/31397807#
#SPJ11
in one town, 35% of all voters are democrats. if two voters are randomly selected for a survey, find the probability that they are both democrats. round to the nearest thousandth if necessary.
Answers
The probability that both randomly selected voters are Democrats is approximately 0.123.
To find the probability that both randomly selected voters are Democrats, we can use the concept of independent events.
Given that 35% of all voters in the town are Democrats, the probability of selecting a Democrat for the first voter is 0.35. Since the events are independent, the probability of selecting another Democrat for the second voter is also 0.35.
To calculate the probability that both events occur, we multiply the probabilities together:
Probability of both voters being Democrats = 0.35 * 0.35 = 0.1225
Rounding to the nearest thousandth, the probability that both randomly selected voters are Democrats is approximately 0.123.
Therefore, the probability that both voters selected for the survey are Democrats is approximately 0.123 or 12.3% (rounded to the nearest thousandth).
To know more about probability, refer here:
https://brainly.com/question/29740654
#SPJ4
another advantage of using anova is that it ________ so the significant differences can be located and interpreted easily.
Answers
Another advantage of using Anova is that it arranges the means so the significant differences can be located and interpreted easily.
The ANOVA test is a type of statistical test used to determine whether there is a statistically significant difference between two or more categorical groups by testing mean differences using variance.
Another important part of the ANOVA is the splitting of the independent variables into two or more groups.
The assumptions for the ANOVA test are the same as those for general parametric tests.
ANOVA can only be performed if there is no relationship between subjects in each sample. Sample size for different groups/levels must be the same.ANOVA can only be performed if the dependent variable is normally distributed.the population variances of must be equal (that is, homoscedasticity). Homogeneity of variance means that the variability of results is similar across populations.Advantages of ANOVA:
The z-test can only be used to compare two population means, whereas the ANOVA test can be used to compare three or more population means.When there are two different treatments/factors affecting the dependent variable, the Two Way ANOVA test can be used to analyze the effect of each treatment.To learn more about ANOVA test , refer:
https://brainly.com/question/15084465
#SPJ4
Which choice is the correct graph of |xl>10
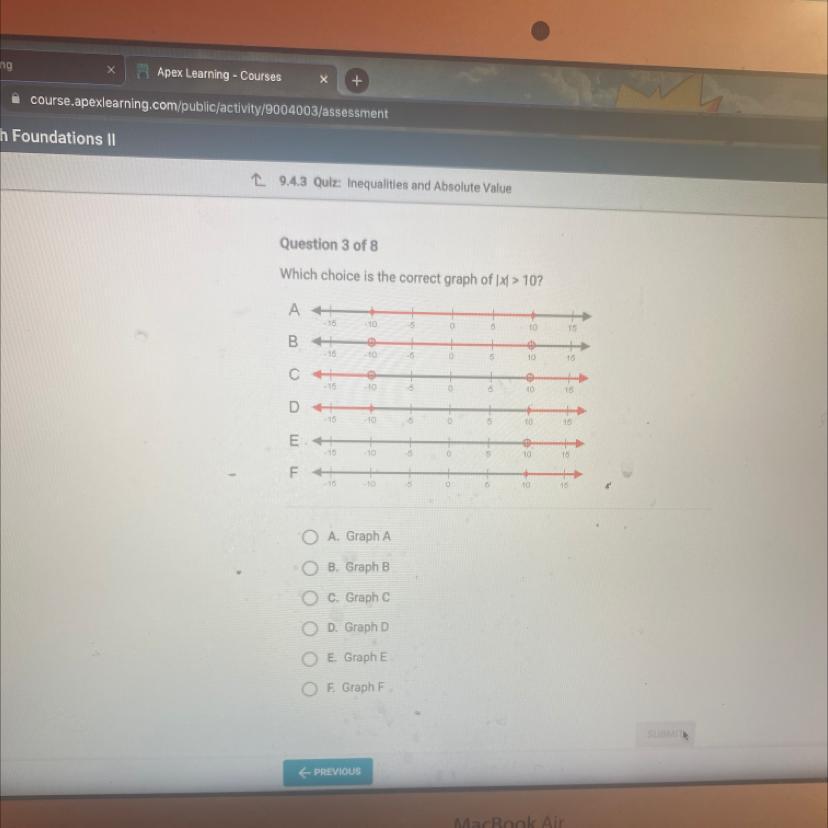
Answers
Answer:
Graph F
Step-by-step explanation:
The image is quite blurry.
But since in the equation there is no equal to \(\leq\) symbol and the absolute value of x is greater than ten, Graph F seems to be the best option.
Answer:
graph f
Step-by-step explanation:
Gaston is buying frult at a local grocery store. This table shows the cost per pound of each type of fruit. Match each
quantity of fruit with its total cost. Drag the items on the left to the correct location on the right.
3 pounds of bananas
4.24
4 pounds of grapes
2.37
3 pounds of oranges
1.95
2 pounds of apples
2.68
Answers
Answer:
bananas=$12.72
grapes=$9.48
oranges=$5.85
apples=$5.36
Step-by-step explanation:
To find the total cost for each fruit you would multiply the number of fruit by the cost.
bananas=3*4.24=$12.72
grapes=4*2.37=$9.48
oranges=3*1.95=$5.85
apples=2*2.68=$5.36
what is the mean of 4,6,7,7,11,12,15,18,20
Answers
Answer:
11.1111111111 or 1.1 <-(rounded)Step-by-step explanation:
4+6+7+7+11+12+15+18+20= 100
divide by the number of values we have. we have 9 values
100/9=11.1111111111
I hope this helped
at first add all the number and divide it by how many numbers are there
4+6+7+7+11+12+15+18+20
= 100
now
divide
100÷ 9
11.1
use the given graph of f(x) = x to find a number δ such that if |x − 4| < δ then x − 2 < 0.4.
Answers
Using the given graph of f(x) = x to find a number δ such that if |x − 4| < δ then x − 2 < 0.4, we can say that if |x - 4| < δ, where δ = 0.4, then x - 2 < 0.4.
Let's define the function f(x) = x and use the given graph of the function to find the value of δ, such that if |x - 4| < δ then x - 2 < 0.4. Let's take a look at the graph given below: Now, let's take the two points on the graph such that the vertical distance between the points is 0.4.The points are (4, 4) and (4.4, 4.4).
From the graph, we can see that if x < 4.4, then the function f(x) will have a value less than 4.4, which means that x - 2 will be less than 0.4.Therefore, we can say that if |x - 4| < δ, where δ = 0.4, then x - 2 < 0.4.
More on functions: https://brainly.com/question/28149000
#SPJ11
larry wants new carpeting for rectangular living room. Her living room is 18 feet by 12 feet. How much carpeting does she need?
Answers
\(\text{To get the total surface area, all we have to do is multiply } 18 \text{ by } 12, \text{which gets us}\)\($18\cdot12 = \boxed{216\text{ ft}^2}\).
\(\text{So, our answer is } \boxed{216\text{ ft}^2}.\)
Larry needs 216 square feet of carpeting for her rectangular living room.
To find the amount of carpeting Larry needs, we need to calculate the area of her rectangular living room. The area of a rectangle can be found by multiplying its length by its width. In this case, the length of the living room is 18 feet and the width is 12 feet.
So, the area of the living room is:
Area = Length * Width
Area = 18 feet * 12 feet
Area = 216 square feet
Therefore, Larry needs 216 square feet of carpeting for her living room.
Learn more:About carpeting here:
https://brainly.com/question/18297841
#SPJ11
The volume of the right prism is 252 ft3. What is the surface area of the prism, in square feet?
Answers
Answer:
a) 252 square feet
Surface area of triangular prism = 252 square feet
Step-by-step explanation:
Explanation:-
Given diagram Base = 3 feet
Height of the triangular = 4 feet
The slant height of triangular prism 'l' =20 feet
The hypotenuse of the triangle 'c' = 5 feet
prism base area 'p' = h+b+c = = 4 +3+5 =12
Surface area of triangular prism
=
= b h + p l
= 3 ×4 + 12×20
= 252 square feet
Final answer:-
Surface area of triangular prism = 252 square feet
Step-by-step explanation:
Answer:
a) 252 square feet
Surface area of triangular prism = 252 square feet
Step-by-step explanation:
Explanation:-
Given diagram Base = 3 feet
Height of the triangular = 4 feet
The slant height of triangular prism 'l' =20 feet
The hypotenuse of the triangle 'c' = 5 feet
prism base area 'p' = h+b+c = = 4 +3+5 =12
Surface area of triangular prism
=
= b h + p l
= 3 ×4 + 12×20
= 252 square feet
Final answer:-
Surface area of triangular prism = 252 square feet
Step-by-step explanation:
What is the most compact mathematical representation of a function? A) Equation B) Domain C) Graph D) Data table
Answers
Answer:
A) Equation
Step-by-step explanation:
Compared to an equation (ex. \(y=mx+b\)) and the domain (ex. ℝ) of a function, a large graph or data table with multiple rows cannot be considered compact, so eliminate C) and D). Although the domain may seem more compact than an equation, it does not completely represent a function like an equation, so eliminate B). The answer is A) Equation.