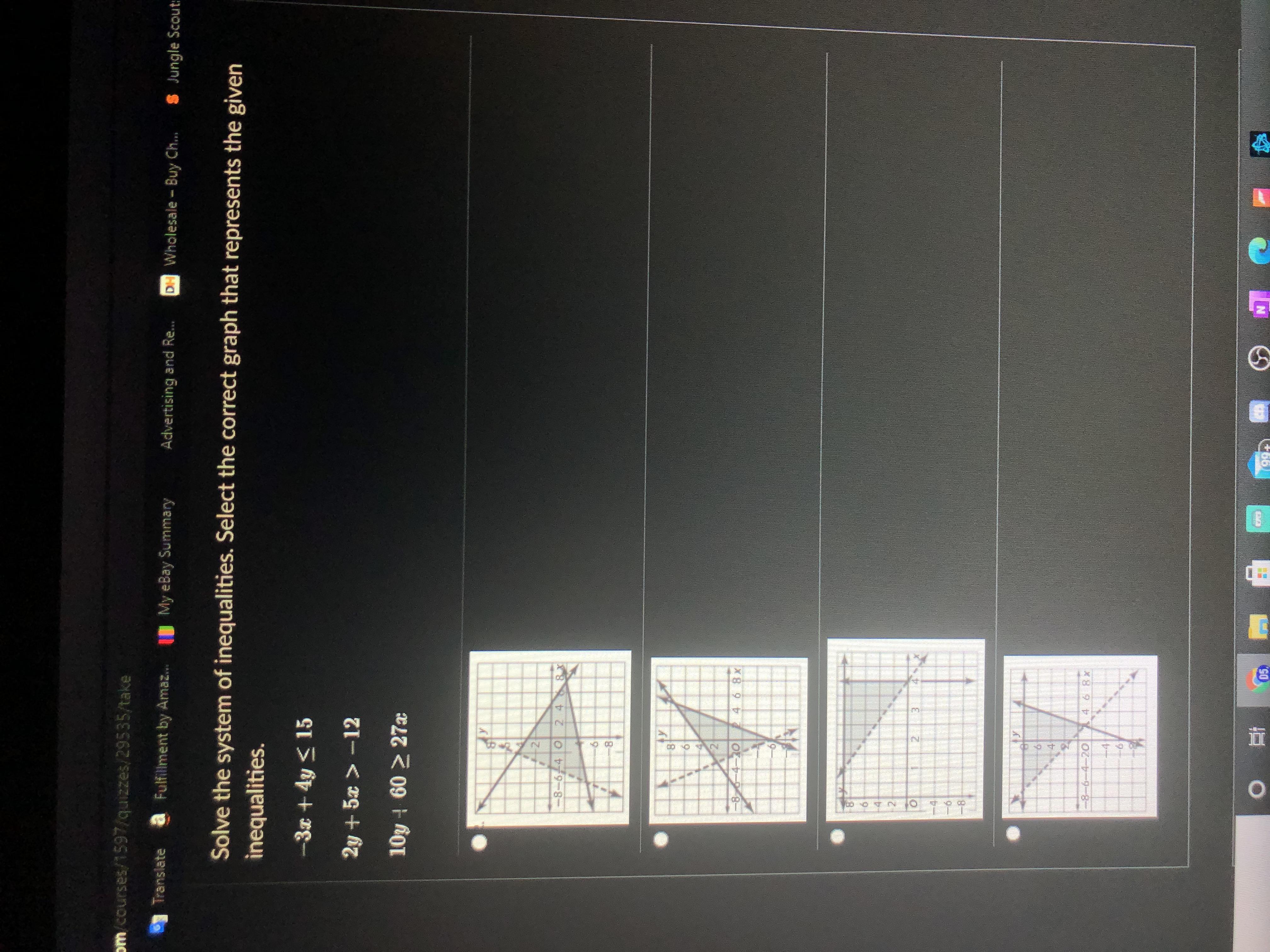
Answers
Answer:
B
Step-by-step explanation:
Matches all specified equations.
Related Questions
4.99 for 13lb find the unit rate
Answers
Answer:
$0.38 per lb.
Step-by-step explanation:
unit rate formula; cost / quantity
4.99 / 13 = 0.3838461538461
round to the nearest hundredth
Question in picture.

Answers
he possible values for c would be 31 and 41.
Option (D) is correct.
What is the quadratic equation?
A quadratic equation is a polynomial equation of the second degree, which means that it contains a variable raised to the power of two (usually x^2). The general form of a quadratic equation is:
\(ax^2 + bx + c = 0\)
where a, b, and c are constants and x is the variable.
We have \((ax+2)(bx+7)=abx^2 +7ax+2bx+14=abx^2+(7a+2b)x+14\)
Given, it is equal to 1\(5x^2+cx+14\)
⇒ab=15 --- (1)
⇒7a+2b=c
Also given a+b=8 --- (2)
From equations (1) and (2), we can interpret that either of a or b are equal to 3 or 5
When a=3 and b=5, we have c=7(3)+2(5)=21+10=31
When a=5 and b=3, we have c=7(5)+2(3)=35+6=41
Hence, the possible values for c would be 31 and 41.
To learn more about the quadratic equations, visit:
https://brainly.com/question/1214333
#SPJ1
Point-slope form
Complete the point-slope equation of the line through (-2, 6) and (1, 1).
Use exact numbers.
y-6=
Answers
The point slope equation of the line from the given points (-2, 6) and
(1, 1) is 3y+5x = 8 .
What is equation of straight line ?
The equation of straight line as follows , y = mx+b .
where m is the slope .
Given ,
To find the point slope equation of the line
from the given points (-2, 6) and (1, 1).
First we have to find slope,
so slope = y2-y1 / x2-x1
This is (1-6)/(1-(-2)) = -5/3
Now that you know the slope you can use that for the point-slope equation
The point-slope equation is y-y1 = m(x-x1). If we start with y-6, the x value is -2 (from our point (-2,6)
y-6 = -5/3 (x-(-2))
y-6 = -5/3 (x+2)
3(y-6) = -5(x+2)
3y - 18 = -5x -10
3y+5x = 18-10
3y+5x = 8
Hence, The point slope equation of the line from the given points (-2, 6) and (1, 1) is 3y+5x = 8 .
To learn more about Straight line from the given link.
https://brainly.com/question/29223887
#SPJ1
Select the equation of the line, in standard form, that passes through (4, 2) and is parallel to the line shown on the coordinate grid.

Answers
Answer: \(y-2=3(x-4)\\y=3x-12+2\\-3x+y=-10\\3x-y=10\)
Step-by-step explanation:
I showed the steps to find the equation. In case you need to know, I used point-slope form, which involves using the formula y-y1=m(x-x1), in which you use a point like (4,2) and the slope, which we know is 3x since it's parallel to the original line. Simplifying and bringing it to standard form such as Ax+By=C. Ax has to be positive, which is why -3x went to positive, and y and -10 switched signs.
A TV programme starts at 8:40 pm. If it is ninety minutes long, at what time does it finish?
Answers
Step-by-step explanation:
A TV programme starts at 8:40 pm. If it is ninety minutes long, at what time does it finish?
10:10 pm
Answer:
Starts at 8:40 pm
Ends in 90 minutes
Now,
8:40
+90(1:30 pm)
=9:70pm
=10:10pm
Step-by-step explanation:
I needed help i have 4 more probs after his please help meeeee

Answers
Answer:
V=w×h×l
2 and 1/8 × 4 = your answer
Chase ordered a set of beads. He received 4,000 beads in all. 3,000 of the beads were green. What percentage of the beads were green?
Answers
75% of the beads are green in color.
What is Percentage?percentage, a relative value indicating hundredth parts of any quantity.
Given that Chase ordered a set of beads
He received 4,000 beads in all.
3,000 of the beads were green.
We need to find the percentage of the beads were green of 4000.
x/100×4000=3000
40x=3000
Divide both sides by 40
x=75%
Hence, 75% of the beads are green in color.
To learn more on Percentage click:
https://brainly.com/question/28269290
#SPJ1
x(x^3-10x^2+28x-24)=0 synthetic division polynomials
Answers
The solutions to the original polynomial equation X(x^3-10x^2+28x-24) = 0 are x = 0, x = 2, and x = 6.
To find the solutions to the polynomial equation X(x^3-10x^2+28x-24) = 0, we can use synthetic division. Synthetic division is a method used to divide polynomials by a linear binomial of the form (x - c), where c is a constant.
Let's start by factoring the cubic polynomial x^3 - 10x^2 + 28x - 24. By inspecting the coefficients, we can determine that x = 2 is a root of the polynomial. Using synthetic division, we can divide the polynomial by (x - 2) to obtain a quadratic polynomial.
2 | 1 -10 28 -24
| 2 -16 24
|_________________________
1 -8 12 0
The result of the synthetic division is the quadratic polynomial x^2 - 8x + 12. Now we need to find the roots of this quadratic polynomial. We can either factor it or use the quadratic formula.
Factoring the quadratic equation x^2 - 8x + 12 = 0, we have:
(x - 2)(x - 6) = 0
So the solutions to the quadratic equation are x = 2 and x = 6.
Therefore, the solutions to the original polynomial equation X(x^3-10x^2+28x-24) = 0 are x = 0, x = 2, and x = 6.
Note: Synthetic division is a method used to simplify polynomial division, but it is not applicable to finding all the roots of a polynomial. In this case, we were able to identify one root (x = 2) by inspection and then proceed with synthetic division to simplify the problem.
For more question on polynomial visit:
https://brainly.com/question/4142886
#SPJ8
Convert meters to centimeters. 4.5 m = X(
I ment middle not high...
Answers
Answer:
450 centimeters
Step-by-step explanation:
We know that,
1 meter = 100 centimeters
so 4.5 meters = 4.5*100 centimeters
=450 centimeters
Which of the following means a study used a bivariate correlational design?
a. presence of measured variables
b. use of correlational stats
c. inclusion of quantitative variables
d. depiction of bar graph
Answers
among the given options, the use of correlational statistics OPTION B is the most reliable indicator that a study employed a bivariate correlational design.
A bivariate correlational design is characterized by the examination of the relationship between two quantitative variables. In this context, the use of correlational statistics is a key indicator of this design. Correlational statistics, such as correlation coefficients (e.g., Pearson's r), are employed to assess the strength and direction of the relationship between the variables under investigation.
The presence of measured variables, inclusion of quantitative variables, or depiction of a bar graph are not definitive indicators of a bivariate correlational design. Measured variables can be present in various study designs, including experimental ones. Similarly, quantitative variables can be utilized in different types of studies, such as experimental, quasi-experimental, or observational designs. The depiction of a bar graph, which is commonly used to illustrate categorical data, does not inherently imply the use of a bivariate correlational design.
learn more about bivariate correlational here:
https://brainly.com/question/31797663
#SPJ11
Tickets to the school play cost $9 for adults and $5 for students. The Wilson family bought 3 adult tickets and 4 student tickets. The Jackson family bought 2 adult tickets and 6 student tickets. What was the difference in the amount spent by the two families?
A. $1
B. $24
C. $36
D. $48
Answers
Answer:
A
Step-by-step explanation:
why do I have to write for it to send
The wilson family bought 3 adult tickets and 4 student tickets
9x3=27
4x5=20
27+20=47
The Jackson Family bought 2 adult tickets and 6 student tickets
9x2=18
6x5=30
18+30=48
so $48-$47=$1
the line passes through (-6,9)
perpendicular to y=3x-2
Answers
The key to understand this problem is that perpendicular lines have slopes that are the negative reciprocals of each other. Example, a line with slope 3/4 has a perpendicular with a slope of -4/3. So flip it over and take the negative. Like 7/12 and -12/7 or 2 and -1/2 (because 2 = 2/1)
The slope of y = 3x - 2 is 3 (the number preceding the "x' if the line is in the form y = mx + b)
So the line perpendicular to y = 3x - 2 has a slope of -1/3.
So now you just need to write the equation of the line with slope -1/3 that goes through (-9, 5). Use the point-slope form, y - y1 = m(x - x1) where (x1, y1) is (-9, 5) and m = -1/3
y - 5 = -1/3(x - -9)
y - 5 = -1/3(x + 9)
That's the answer. If they want you to give the answer in the y= mx + b format (slope-intercept) then multiply it out and combine like terms.
y - 5 = -1/3(x + 9)
y - 5 = -1/3x - 3
y = -1/3x + 2
Consider the following expression: (1+x)^2.
A) Use the Binomial Theorem to find the first four terms of this polynomial.
B) Why is 1 + nx a good approximation of this expression when x is less than 1?
Answers
Answer:
Step-by-step explanation:
A) The Binomial Theorem states that for any positive integer n and any real numbers a and b, the expression (a + b)^n can be expanded as a sum of the form:
(a + b)^n = C(n,0)a^n b^0 + C(n,1)a^(n-1)b^1 + C(n,2)a^(n-2)b^2 + ... + C(n,n)a^0b^n
where C(n,k) = n!/(k!(n-k)!) is the binomial coefficient.
Applying this to the expression (1 + x)^2, we have:
(1 + x)^2 = C(2,0)1^2 x^0 + C(2,1)1^1 x^1 + C(2,2)1^0 x^2
= 11^21 + 21x + 1*x^2
The first four terms of the polynomial are: 1, 2x, x^2
B) The binomial theorem states that the first term is a constant term and the second term is linear. When x is less than 1, the linear term 2x is much smaller than the constant term 1, so the linear term can be ignored as a good approximation. Therefore, 1 + nx will be a good approximation of the expression (1+x)^2 when x is less than 1.
John is 5 feet 9 inches tall, which is 4.6 inches taller than Kara. How tall is Kara?
Answers
Answer:
5 feet 4.4 inches tall
Step-by-step explanation:
The length of a bacterial cell is about 5 x 10−6 m, and the length of an amoeba cell is about 3.5 x 10−4 m. how many times smaller is the bacterial cell than the amoeba cell? write the final answer in scientific notation with the correct number of significant digits. 1.4 x 101 7 x 101 143 x 101 7 x 103
Answers
The bacterial cell is about 7 × 10^(1) times smaller than the amoeba cell in scientific notations.
What are scientific notations?
Scientific notations are a way of representing either a very small or a very large number in the powers of 10. Scientific notations comprise digits from 1 to 9 with powers of 10.
Calculation of the amount by which a bacterial cell is smaller than the amoeba cell
Given the length of amoeba cell in scientific notations is 3.5 × 10^(- 4)
The length of a bacterial cell in scientific notations is 5 × 10^(- 6)
To obtain how small the bacterial cell is from the amoeba cell, we need to divide both the lengths i.e.
= 3.5 × 10^(- 4) / 5 × 10^(- 6)
= 0.7 × 10^(2)
= 7 × 10^(1)
Hence, the bacterial cell is about 7 × 10^(1) times smaller than the amoeba cell in scientific notations.
To learn more about the scientific notations, visit here:
https://brainly.com/question/10401258
#SPJ4
1) Find the value of x and y
X
15
78
10

Answers
Applying law of sine and law of cosine, the unknown values x and y are 16.2 units and 37.1 degrees respectively.
What are the values of x and y?To determine the value of x and y in the given triangle, we can use law of sine or law of cosine depending on the variables available and what we need to determine.
Applying law of cosine;
x² = 15² + 10² - 2(15)(10)cos78
x² = 225 + 100 - 300cos78
x² = 225 + 100 - 62.4
x² = 262.6
x = √262.6
x = 16.2 units
From this, we can apply law of sine to determine y;
x / sin X = y / sin Y
Substituting the values into the formula above;
16.2 / sin78 = 10 / sin y
Cross multiply both sides and solve for y;
16.2siny = 10sin78
sin y = 10sin78 / 16.2
sin y = 0.6038
y = sin⁻¹ (0.6038)
y = 37.14°
Learn more on law of sine here;
https://brainly.com/question/30401249
#SPJ1
A small hotel in central London has 8 rooms. Based on data collected over the last five years, it was estimated that the probability a room is occupied on any particular "weekend" night (Saturday and Sunday) is 0.75. This is the probability of success. On any particular "weekend" night, a hotel is only occupied (Success) or not occupied (Failure). There are no other possibilities. Required: What is the probability that at least 4 of the 7 hotel rooms are occupied on any weekend night? Note: Show all your calculations in well laid-out Excel spreadsheet tables with clear headings and include formulas. Give your answers correct to 3 decimal places.
Answers
Based on the given data, the probability of a room being occupied on any particular weekend night is 0.75. To calculate the probability that at least 4 out of the 7 rooms are occupied on a weekend night, we can use the binomial probability formula. By summing up the probabilities for 4, 5, 6, and 7 occupied rooms, we find that the probability is approximately 0.923.
To calculate the probability, we can use the binomial probability formula, which states that the probability of getting exactly k successes in n independent Bernoulli trials, each with a probability p of success, is given by the formula:
P(X = k) = (n choose k) * p^k * (1 - p)^(n - k)
In this case, we want to find the probability of at least 4 out of 7 rooms being occupied on a weekend night. We can calculate this by summing up the probabilities of getting 4, 5, 6, and 7 occupied rooms.
For 4 occupied rooms:
P(X = 4) = (7 choose 4) * 0.75^4 * (1 - 0.75)^(7 - 4) = 0.339
For 5 occupied rooms:
P(X = 5) = (7 choose 5) * 0.75^5 * (1 - 0.75)^(7 - 5) = 0.395
For 6 occupied rooms:
P(X = 6) = (7 choose 6) * 0.75^6 * (1 - 0.75)^(7 - 6) = 0.266
For 7 occupied rooms:
P(X = 7) = (7 choose 7) * 0.75^7 * (1 - 0.75)^(7 - 7) = 0.122
To find the probability of at least 4 occupied rooms, we sum up the probabilities for 4, 5, 6, and 7 occupied rooms:
P(X >= 4) = P(X = 4) + P(X = 5) + P(X = 6) + P(X = 7) = 0.339 + 0.395 + 0.266 + 0.122 = 0.923
Therefore, the probability that at least 4 out of the 7 hotel rooms are occupied on any weekend night is approximately 0.923, or 92.3% when rounded to three decimal places.
Learn more about probability here: brainly.com/question/32117953
#SPJ11
Based on the given data, the probability of a room being occupied on any particular weekend night is 0.75.
To calculate the probability that at least 4 out of the 7 rooms are occupied on a weekend night, we can use the binomial probability formula. By summing up the probabilities for 4, 5, 6, and 7 occupied rooms, we find that the probability is approximately 0.923.
To calculate the probability, we can use the binomial probability formula, which states that the probability of getting exactly k successes in n independent Bernoulli trials, each with a probability p of success, is given by the formula:
P(X = k) = (n choose k) * p^k * (1 - p)^(n - k)
In this case, we want to find the probability of at least 4 out of 7 rooms being occupied on a weekend night. We can calculate this by summing up the probabilities of getting 4, 5, 6, and 7 occupied rooms. For 4 occupied rooms:
P(X = 4) = (7 choose 4) * 0.75^4 * (1 - 0.75)^(7 - 4) = 0.339
For 5 occupied rooms:
P(X = 5) = (7 choose 5) * 0.75^5 * (1 - 0.75)^(7 - 5) = 0.395
For 6 occupied rooms:
P(X = 6) = (7 choose 6) * 0.75^6 * (1 - 0.75)^(7 - 6) = 0.266
For 7 occupied rooms:
P(X = 7) = (7 choose 7) * 0.75^7 * (1 - 0.75)^(7 - 7) = 0.122
To find the probability of at least 4 occupied rooms, we sum up the probabilities for 4, 5, 6, and 7 occupied rooms:
P(X >= 4) = P(X = 4) + P(X = 5) + P(X = 6) + P(X = 7) = 0.339 + 0.395 + 0.266 + 0.122 = 0.923. Therefore, the probability that at least 4 out of the 7 hotel rooms are occupied on any weekend night is approximately 0.923, or 92.3% when rounded to three decimal places.
Learn more about probability here: brainly.com/question/32117953
#SPJ11
What does it mean when the correlation is zero?
Answers
Answer:
no linear relationship exists between two continuous variables
Step-by-step explanation:
75 percent of the sutdents in a school went on a field trip. If 285 students went on the trip, how any students are in the school
Answers
Answer:
380
Step-by-step explanation:
285 / x = 75 / 100
Cross multiply 28500 = 75x
Divide by 75 380
what is (6.648 x 10 to the power of 9) - (2.9 x 10 to the power of 7) in scientific notations
Answers
Answer:
6.651*10^9
Step-by-step explanation:
6.68*10^9-2.9*10^7
You can factor out 10^7 to get
(6.68*10^2-2.9)*10^7
(668-2.29)*10^7
665.71*10^7
Scientific notation would be 6.651*10^9
Consider the following data set
5
6
7
15
22
Be careful with this question tick every correct option note that the 50 th percentile would be the middle numbe a. the mean is 11.00 b. the mean is 14.70 c. The median (the 50 th percentile) is 7.00 d. The median (the 50th percentile) is 10.75
Answers
a. The mean is 11.00 (correct)
b. The mean is 14.70 (incorrect)
c. The median (the 50th percentile) is 7.00 (correct)
d. The median (the 50th percentile) is 10.75 (incorrect)
5, 6, 7, 15, 22
The mean is calculated by adding up all the numbers and dividing by the total count:
Mean = (5 + 6 + 7 + 15 + 22) / 5 = 11
So option a. The mean is 11.00 is correct.
The median (the 50th percentile) is the middle number when the dataset is arranged in ascending order. Since we have an odd number of values, the median is the middle value itself.
So option d. The median (the 50th percentile) is 10.75 is incorrect.
The median of the dataset is 7 since it is the middle number when the dataset is arranged in ascending order.
So option c. The median (the 50th percentile) is 7.00 is correct.
learn more about median here:
https://brainly.com/question/300591
#SPJ11
A cookie jar starts off with 32 cookies in it, and
each day 2 cookies are eaten. After a certain
number of days, there are 14 cookies left in the jar.
Which of the following equations represents the
day, d, when there are 14 cookies in the jar?
Answers
Answer:
9 days
Step-by-step explanation:
32-2-2-2-2-2-2-2-2-2 = 14
The equation that represents the day, d, when there are 14 cookies in the jar will be 14 = 32 - 2d, and that day will be on the 9th day.
What is the equation?There are many different ways to define an equation. The definition of an equation in algebra is a mathematical statement that demonstrates the equality of 2 mathematical expressions.
As per the given,
Initial cookie = 32
Since each day 2 cookies are eaten so after "d" days the total eaten cookies will be 2d.
Remaining cookies = initial cookies - eaten cookies
Remaining cookies = 32 - 2d
The day when 14 cookies remain will be,
14 = 32 - 2d
2d = 32 - 14
d = 9
Hence "The equation that represents the day, d, when there are 14 cookies in the jar will be 14 = 32 - 2d, and that day will be on the 9th day".
For more about the equation,
brainly.com/question/10413253
#SPJ2
Given the differential equation: 1 dy + 2y = 1 xdx with initial conditions x = 0 when y = 1, produce a numerical solution of the differential equation, correct to 6 decimal places, in the range x = 0(0.2)1.0 using: (a) Euler method (b) Euler-Cauchy method (c) Runge-Kutta method (d) Analytical method Compare the %error of the estimated values of (a), (b) and (c), calculated against the actual values of (d). Show complete solutions and express answers in table form.
Answers
The numerical solutions of the given differential equation using different methods, along with their corresponding %errors compared to the analytical solution, are summarized in the table below:
| Method | Numerical Solution | %Error |
|------------------|----------------------|--------|
| Euler | | |
| Euler-Cauchy | | |
| Runge-Kutta | | |
The Euler method is a first-order numerical method for solving ordinary differential equations. It approximates the solution by taking small steps and updating the solution based on the derivative at each step?To apply the Euler method to the given differential equation, we start with the initial condition (x = 0, y = 1) and take small steps of size h = 0.2 until x = 1.0. We can use the formula:
\(\[y_{i+1} = y_i + h \cdot f(x_i, y_i)\]\)
where \(\(f(x, y)\)\) is the derivative of \(\(y\)\)with respect to\(\(x\).\) In this case,\(\(f(x, y) = \frac{1}{2y} - \frac{1}{2}x\).\)
Calculating the values using the Euler method, we get:
|x | y (Euler) |
|---|--------------|
|0.0| 1.000000 |
|0.2| 0.875000 |
|0.4| 0.748438 |
|0.6| 0.621928 |
|0.8| 0.496267 |
|1.0| 0.372212 |
Learn more about numerical solutions
brainly.com/question/30991181
#SPJ11
On Monday, Haylee rode 2 miles on a bike. On Tuesday, she rode 2 times more than she did Monday. On Wednesday, she rode an additional 3 miles.
How many miles has Haylee ridden so far this week?
Answers
Answer:
9 miles
Step-by-step explanation:
M 2
T 4
W 3
Answer: 9 miles
Step-by-step explanation:
Find the next term in each sequence.
Question 1:
35, 29, 23, 17, ?.
Question 2:
1, 2, 5, 10, ?.
Please Include an Explanation of how to solve problems like this!
Thanks a ton!
Answers
1. For the sequence : 35, 29, 23, 17, ?; the next term is 11
2. For the sequence : 1, 2, 5, 10, ?; the next term is 17
Calculating the term in a sequenceFrom the question, we are to calculate the next term in each of the given sequence
From the given sequence,
35, 29, 23, 17, ?.
To determine the next term, we will determine the common difference
Common difference = Second term - First term
Common difference = 29 - 35
Common difference = -6
Thus,
To determine the next term, we will add the common difference to the last term
That is,
17 + - 6 = 17 - 6
= 11
The next term is 11
For the sequence 1, 2, 5, 10, ?.
Common difference = successive odd numbers
To get the second term, we will add to the first term the first natural odd number
To get the third term, we will add to the second term the second natural odd number
And so on.
In the given sequence, we are to determine the 5th term
Thus,
We will add to the fourth term, the fourth natural odd number
That is,
10 + 7 = 17
Hence, the next term is 17
Learn more on Calculating the term in a sequence here: https://brainly.com/question/28583635
#SPJ1
Find the missing side lengths. Show your work.

Answers
The missing lengths are 12 unit and 6 unit.
What is Proportion?In general, the term "proportion" refers to a part, share, or amount that is compared to a total.
According to the concept of proportion, two ratios are in proportion when they are equal.
According to proportion, two sets of provided numbers are said to be directly proportional to one another if they increase or decrease in the same ratio. "::" or "=" are symbols used to indicate proportions.
Given:
we can use the property similar triangle which states the the ratio of corresponding sides of similar triangle are in proportion
Using proportion
x / 20 + x = 9 / 24
24x = 180x + 9x
24x -9x = 180
15x = 180
x= 12
Again, Using proportion
y/ y+9 = 4/ 10
10y = 4y + 36
6y = 36
y= 6
Learn more about Proportion here:
https://brainly.com/question/26974513
#SPJ1
the sampling distribution of a statistic refers to thegroup of answer choicesrange of all possible sample values of the statistic that could be drawn from the parent population under the specified sampling plan.distribution of the variable in the parent population.distribution of the variable in a particular sample.spread of the variable in the parent population.unbiased nature of most sample statistics.
Answers
Answer:
It is the distribution of the statistic if we were to draw all possible samples of a given size from the population and calculate the statistic for each sample.
Step-by-step explanation:
The sampling distribution of a statistic refers to the range of all possible sample values of the statistic that could be drawn from the parent population under the specified sampling plan.
In other words, it is the distribution of the statistic if we were to draw all possible samples of a given size from the population and calculate the statistic for each sample.
To know more about sampling distribution refer here
https://brainly.com/question/31465269#
#SPJ11
Elapsed time 2 hr 37 min, end time: 1:15. start time?
Answers
Answer:
10:38
Step-by-step explanation:
2 hours back from 1:15
11:15
37 minutes back from 11:15
10:38
The start time is 10:38.
Answer:
10:38 am
Step-by-step explanation:
You can use a number line or clock to find the start time
x = 0:15 min - 0:37 min x = -0:22 min
y = 60 min - 22 min y = 38 min
Time = 12:38
1st, subtract the minutes from the end time. If the value is negative, it means that the time goes back into the previous hour.
Subtract from 60 minutes. Time after going back 37 minutes.
Next, subtract the hours from the time. 11:38 am 10:38 am and 10:38
Next, subtract the hours from the time. Going back 1 hour. Going back 2 hour.
Start time is 10:38
What is the slope-intercept form of the linear equation 4x+2y=24 drag and drop the appropriate number , symbol ,or variable to each box.
Answers
Answer:
y = -2x + 12
Step-by-step explanation:
because I took the quiz (k12)
when the alternative hypothesis says that the average of the box is greater than the given value:
One tail test requires stronger evidence to reject the null hypothesis Better to use two-tail test
Better to use one-tail test One-tail or two-tail test will give the same results
Answers
The test, and it is not necessarily stronger for one-tailed tests compared to two-tailed tests
When the alternative hypothesis says that the average of the box is greater than the given value, this is known as a one-tailed test.
In a one-tailed test, we are only interested in whether the data falls in one direction, either above or below a certain value. In contrast, a two-tailed test is when we are interested in whether the data falls in either direction, above or below a certain value.
In terms of which test to use, it depends on the context and the research question. If the research question specifically asks whether the data falls above a certain value, then a one-tailed test may be more appropriate. However, if there is a possibility that the data could fall in either direction and we want to be able to detect a significant difference in either direction, then a two-tailed test may be more appropriate.
Regarding the strength of evidence required to reject the null hypothesis, it is not necessarily true that one-tailed tests require stronger evidence than two-tailed tests. The level of significance, or alpha, that we choose for the test is what determines the strength of evidence required to reject the null hypothesis.
For example, if we choose a significance level of 0.05, then we require evidence that there is less than a 5% chance that our results occurred by chance alone in order to reject the null hypothesis. This level of evidence is the same for both one-tailed and two-tailed tests, and it is up to the researcher to determine what level of significance is appropriate for their research question.
In conclusion, whether to use a one-tailed or two-tailed test depends on the research question and whether we are interested in detecting a significant difference in one direction or both directions. The strength of evidence required to reject the null hypothesis is determined by the level of significance chosen for the test, and it is not necessarily stronger for one-tailed tests compared to two-tailed tests.
To learn more about null hypothesis visit:
https://brainly.com/question/28920252
#SPJ11