help!
Question
A spinner is divided into 4 sections. The spinner is spun 100 times.
The probability distribution shows the results.
What is P(1≤x≤3)?
Enter your answer, as a decimal, in the box.

Answers
The probability of getting a number between 1 and 3 (inclusive) on the spinner is 0.90 or 90%.
What is probability distribution?An expression that expresses the likelihood of different outcomes in a random process is known as a probability distribution. To put it another way, it provides the probabilities connected to each potential outcome of a random variable.
A variable's value is determined by the results of a random process is known as a random variable. A random variable's values can be continuous, taking on any value falling within a predetermined range, or discrete, taking on only a limited or countably infinite set of possibilities.
For P(1≤x≤3), we need to sum the probabilities for x=1, x=2, and x=3:
P(1≤x≤3) = P(x=1) + P(x=2) + P(x=3)
= 0.33 + 0.15 + 0.42
= 0.90
Hence, the probability of getting a number between 1 and 3 (inclusive) on the spinner is 0.90 or 90%.
Learn more about probability distribution here:
https://brainly.com/question/14210034
#SPJ1
Related Questions
Find the measure of the angle indicated in bold.
14)
А) 120
C) 115°
B) 100P
D) 140°
Answers
Answer:
115 sirrrrr
Step-by-step explanation:
You have a dictionary of n-words, each with up to 10 characters, given two words s and t, you need to find a way to change the word s into the word t, while changing only one letter at a time such that every intermediate word belongs to D
For example, if we have D= ['hit', 'cog', 'hot', 'dot', 'dog', 'lot', 'log'], one way to change 'hit' to 'cog' is 'hit'→'hot' → dot → dog →'cog'
a. Model this as a graph problem, what would be the vertices and edges in the graph? How can the original problem of changing the words to the word t be stated in terms of this graph? [2M]
b. Show that this graph can be constructed in O(n²) time, and its size is up to O(n²).
Answers
The problem of changing the word s into the word t can be stated in terms of finding a path in this graph from vertex s to vertex t, where each intermediate vertex (word) in the path differs from the previous one by only one character and belongs to D.
a. To model this as a graph problem, we can treat each word in the dictionary D as a vertex in the graph. Then, we can create an edge between two vertices (words) if they differ by only one character. For example, there would be an edge between 'hit' and 'hot', as they differ by only one character ('i' and 'o'). The problem of changing the word s into the word t can be stated in terms of finding a path in this graph from vertex s to vertex t, where each intermediate vertex (word) in the path differs from the previous one by only one character and belongs to D.
b. To construct the graph, we can iterate through all pairs of words in D and check if they differ by only one character. This takes O(n²) time. Once we have identified the edges in the graph, the size of the graph is also up to O(n²), since there can be at most n vertices and n² edges (when every vertex is connected to every other vertex). Therefore, constructing the graph takes O(n²) time, and the size of the graph is up to O(n²).
To know more about the vertex of a graph visit:
https://brainly.com/question/12520974
#SPJ11
help me!
solve for y

Answers
Answer:
\sqrt{7}i or -\sqrt{7}i
Step-by-step explanation:
square root both sides of the equation
since you can't sqrt a negative number, you substitute sqrt of -1 to i
Which gets the answer.
Maggy needs to ship watches for her boss. Maggy has 50 watches and 6 boxes. Each box must contain an equal number of watches. How many watches does she have left over?
Answers
Eli’s class held a fund raising event last month. The class’s expenses were+5.75, +4.75, and +3.75. The amounts of money the class raised were+13.50, +24.70, +13.15, and +19.50.Can you use two different orders of computation?
Answers
The different orders of computation is +56.6
Based on the funding in Eli's class;
The class’s expenses were +5.75, +4.75, and +3.75
Total expenses = +5.75 +4.75 +3.75
Total expenses = +14.25
If the amounts of money the class raised were +13.50, +24.70, +13.15, and +19.50, the total raised is expressed as:
Total money raised = 13.50 +24.70 + 13.15 +19.50
Total money raised = +70.85
Difference in computations = +70.85 - 14.25
Difference in computations = +56.6
Hence the different orders of computation is +56.6
Learn more here: https://brainly.com/question/21002308
A baking class had 45 students on Monday and only 32 students on Tuesday. What was the change in percent? (Round to the nearest hundredths)
Answers
Answer:
28.89 percent
Step-by-step explanation:
45-32 is 13 and 13 is 28.89 percent of 45
Hope this helped!
Let's say we wanted to use the Beck Depression Inventory (BDI) to assess and diagnose depression. The BDI would be an example of:a. a variableb. a measurement instrumentc. datad. internal validity
Answers
The Beck Depression Inventory (BDI) would be an example of a measurement instrument.
A measurement instrument is a tool or technique used to measure or assess a particular variable or construct, in this case, depression. The BDI is a standardized self-report questionnaire that is widely used to assess the severity of depressive symptoms. It consists of 21 questions or items that ask the respondent to rate the intensity of their depressive symptoms on a 4-point scale. The total score on the BDI can be used to classify the severity of depression and guide treatment decisions.
In contrast, a variable is a characteristic or attribute that can take on different values or levels, such as age, gender, or income. Data refers to the collection of measurements or observations obtained from a particular study or investigation. Internal validity is a concept that refers to the extent to which a study is designed and conducted in a way that minimizes the potential for bias or confounding variables.
To know more about measurement instrument,
https://brainly.com/question/15998581
#SPJ11
Region of quipped random samples of 56 Mel and 56 female students from a large university with a small device that secretly record sound for a random 30 seconds during each 12.5 minute period over two days then they counted the number of words spoken by each subject during each recording. From this estimate how long many words per day each student speaks the female estimates had a mean of 16,177 words per day with a standard deviation of 7520 words per day. For the mail estimate the mean was 16,569 and Santa deviation was 9108 do these data provide convincing evidence at 0.05 significance level of a difference in the average number of words spoken in a day but all males and female student at this university
Answers
Based on the given data, there is not enough evidence to suggest a significant difference in the average number of words spoken per day between male and female students at this university at a significance level of 0.05.
How to calculate the valueThe critical value will be:
= ✓(55)(7520²) + (55)(9108²))/(56 + 56 - 2))
≈ 8285.89
t = (16177 - 16569) / (8285.89 * ✓(1/56 + 1/56))
≈ -0.4704
The critical value for a two-tailed test with α = 0.05 and df = 110 is approximately ±1.983.
Since the absolute value of the test statistic (0.4704) is less than the critical value (1.983), we fail to reject the null hypothesis.
Therefore, based on the given data, there is not enough evidence to suggest a significant difference in the average number of words spoken per day between male and female students at this university at a significance level of 0.05.
Learn more about hypothesis on
https://brainly.com/question/11555274
#SPJ1
. If Ya/n and Y2/n are the respective independent relative frequencies of success associated with the two binomial distributions b(n, P1) and b(n, P2), compute n such that the approximate probability that the random
interval (Y1/n - Y2/n) ‡ 0.05 covers pi - p2 is at least 0.80. HINT: Take p* = P° = 1/2 to provide an upper bound
for n.
Answers
we would need a sample size of at least 502 for the approximate probability of the random interval (Y1/n - Y2/n) ‡ 0.05 covering pi - p2 to be at least 0.80.
To compute n, we can use the formula:
n = ((zα/2)^2 * 2p*(1-p*)) / (ε^2)
Where zα/2 is the z-score associated with a confidence level of 1-α, p* is the probability of success for a binomial distribution, and ε is the margin of error.
Since we are given that the approximate probability of the random interval (Y1/n - Y2/n) ‡ 0.05 covering pi - p2 is at least 0.80, we can set α = 0.20 to find the corresponding z-score of 1.28.
Using p* = 1/2 as an upper bound for both P1 and P2, we can calculate the margin of error as:
ε = zα/2 * sqrt((p*(1-p*)) / n)
Plugging in the values, we get:
0.05 = 1.28 * sqrt((0.25) / n)
Solving for n, we get:
n = 501.76
Therefore, we would need a sample size of at least 502 for the approximate probability of the random interval (Y1/n - Y2/n) ‡ 0.05 covering pi - p2 to be at least 0.80.
To know more about probability visit:
https://brainly.com/question/30034780
#SPJ11
plss help me do this o-o

Answers
Answer:
\(x=\sqrt6\\y=\sqrt{12}\)
Step-by-step explanation:
We know that since angles in a triangle add up to 180º, the remaining angle must be 45º.
So the side with length \(x\) must be equal to the side with length \(\sqrt6\). That is:
\(x=\sqrt6\)
Now, by Pythagoras:
\(y=\sqrt{(\sqrt6)^2+(\sqrt6)^2}\\=\sqrt{6+6}\\=\sqrt{12}\)
Answer:
\(x=\sqrt{6}\)
\(y=2\sqrt{3}\)
Step-by-step explanation:
Sum of the interior angles of a triangle = 180°
So the missing angle = 180 - 45 - 90 = 45°
Therefore, as two of the interior angles are congruent (both 45°), this is an isosceles triangle. This means that the two shorter sides are equal,
so \(x=\sqrt{6}\)
Use Pythagoras' Theorem to calculate y:
\(y=\sqrt{(\sqrt{6})^2+(\sqrt{6})^2 } =\sqrt{12} =2\sqrt{3}\)
\(\frac{x}{2}+2+=-2\\\)
Answers
On average in 2009, the school
cafeteria served 515 students
per day. In 2016, the average
number of students served
per day had decreased to 403.
Determine the annual rate of
change.
Answers
Answer:
hello what is this all stuff you typed
Loren is making a holiday pack for her customers. She has 5 different designs and 6 different greeting texts. Each holiday pack includes 3 different designs and 2 different texts. How many unique packs can she create?
Answers
Answer: 1
Step-by-step explanation: only 1 because since each include only 3 diff designs, and she currently owns 5 diff designs, and you can exactly go any further, because 3 + 3 = 6, and its only 5. If it werent for the designs, then she could make 3 texts, because 2 x 3 = 6. Sorry if I got it wrong, I'm just confused on how this is explained.
150 unique packs can be created.
What is Combination?Combinations are mathematical operations that count the number of potential configurations for a set of elements when the order of the selection is irrelevant. You can choose the components of combos in any order. Permutations and combinations can be mixed up.
Given:
Loren has 5 different designs and 6 different greeting texts.
Each holiday pack includes 3 different designs and 2 different texts.
So, the unique ways to create
= \(^5C_3 . ^6C_2\)
= 5! / 3! 2! x 6! / 2! 4!
= 10 x 15
= 150
Hence, 150 unique packs can be created.
Learn more about Combination here:
https://brainly.com/question/28720645
#SPJ2
6+2 divided by 15 (76 x 100)= ??
Answers
Answer:
Step-by-step explanation:
We have to use PEMDAS
P is parentheses so we turn it to 6 + 2 divided by 15(7600)
E is for exponents but we don't have any
M is for multiplication and we have that so its 6 + 2 divided by 114000
D is for division so now its 6 + 1.754
A is for addition so 7.75400
Answer:
4,053.3 repeating
139 students choose to attend one of three after school activities: football, tennis or running.
There are 66 boys.
56 students choose football, of which 28 are girls.
54 students choose tennis.
18 girls choose running.
A student is selected at random.
What is the probability this student chose running?
Give your answer in its simplest form.
Answers
Explanation:
Total student: 139 (66 boys/73 girls)
Football: 56 student (28 boy/28 girl)
Tennis: 54 student (27 boy/ 27 girl)
Running: 29 student (18 girls/11 boys)
The probability that a student chose running is 29/139
Simplify: (x + 7)(x-4)
A. 2r +3
B. 12-28
C. x2-3x - 28
D. x2 + 3x - 28
Answers
Answer:
(x + 7)(x - 4) = x2 - 4x + 7x - 28 = x2 + 3x - 28
Name three points for each description. a) to the left of (17, 12) b) to the right of (17, 12) c) above (17, 12) d) below (17, 12)
Answers
What are the three types of derivatives?
Answers
Algebraic, exponential and trigonometric are three different types of derivatives.
Define differentiation.A technique for determining a function's derivative is differentiation. Mathematicians use a procedure called differentiation to determine a function's instantaneous rate of change based on one of its variables. The most typical illustration is velocity, which is the rate at which a distance changes in relation to time.
Name derivative rule.Power rule, product, quotient, chain, are the rules for derivatives.
Algebraic, exponential and trigonometric are three different types of derivatives.
To learn more about differentiation visit the link:
https://brainly.com/question/954654
#SPJ4
sup yall
solve 4p-7r=pq+16 for p
Answers
Answer:
p = (7r+16) / (4-q)
Step-by-step explanation:
4p - 7r = pq + 16
Add 7r to both sides.
4p = pq + 16 + 7r
Subtract pq from both sides.
4p - pq = 7r + 16
Factor out p from the left side.
p(4 - q) = 7r + 16
Divide both sides by (4 - q).
p = (7r + 16)/(4 - q)
The 7r and the 16 could be in either order, like 7r+16 or 16+7r. You could show that the answer is a fraction with 7r+16 on top and 4-q on the bottom. If you are writing or on the computer selecting a fraction that is stacked you don't need need the parenthesis.
An inspector inspects large truckloads of potatoes to determine the proportion p in the shipment with major defects, prior to using the potatoes to make potato chips. Unless there is clear evidence that this proportion, p, is less than 0. 1, he will reject the shipment. He selects an SRS of 200 potatoes from the more than 5000 potatoes on the truck. Twelve of the potatoes sampled are found to have major defects. Using the plus four method, a 95% confidence interval for the true proportion of potatoes in the truck that have major defects is:
A. 0. 027 to 0. 93.
B. 0. 009 to 0. 111
C. 0. 034 to 0. 103.
D. 0. 051 to 0. 103
Answers
From the given information, option c. is the answer. A 95% confidence interval for the true proportion of potatoes in the truck that have major defects is 0.034 to 0.103.
The plus four method is a method for constructing confidence intervals for proportions, which adds two successes and two failures to the sample before calculating the confidence interval. In this case, we have a sample size of n = 200 and 12 successes (potatoes with major defects) in the sample.
To use the plus four method, we first calculate the adjusted number of successes and failures as follows:
Adjusted number of successes = number of successes + 2
Adjusted number of failures = number of failures + 2
In this case, the adjusted number of successes is 12+2=14, and the adjusted number of failures is 186+2=188.
Next, we calculate the sample proportion:
p = 14/200 = 0.07
Then we add 2 successes and 2 failures to the sample to get a new sample size of n' = 204, with 16 successes and 190 failures. We can use the standard formula for a confidence interval for a proportion with a large sample size:
p ± z × √(p(1-p)/n')
where z is the critical value for the desired level of confidence, and we use p=0.07 as our estimate of the true proportion. For a 95% confidence interval, z=1.96.
Plugging in the values, we get:
\(0.07 ± 1.96√(0.07(1-0.07)/204)\)
Simplifying, we get:
0.07 ± 0.037
So the 95% confidence interval for the true proportion of potatoes in the truck that have major defects is:
0.033 to 0.107
Learn more about proportion here: brainly.com/question/19994681
#SPJ4
Find the measure of the missing angle.
53°

Answers
The measure of the missing angle in the given figure is 37 degrees.
What is right angle?
A right angle is one that measures exactly 90 degrees (or /2) in length. In everyday life, the right angles are constantly shown. For instance, the corners of books or the cardboard's edges. Every square or rectangular shape will have corners that are 90 degrees or at right angles. A right angle is one that is 90 degrees or less.
Two rays that share a vertex and are referred to as the angle's sides in geometry combine to form an angle. The plane where the rays are placed is where two rays' angles are formed. When two planes intersect, angles can also be produced.
From the given figure we see that the measure of the angle formed by the two segments is 90 degrees.
When a segments cuts the angle one angle is 53, the other angle is thus:
90 - 53 = 37
Hence, the measure of the missing angle in the given figure is 37 degrees.
Learn more about right angle here:
brainly.com/question/3770177
#SPJ1
the volume of a cube whose edge is 6cm long is
Answers
Answer:
216 cm^3
Step-by-step explanation:
Volume of a cube=s^3
6 cm^3=216 cm^3
Find the average value of f over the given rectangle.
f(x,y)=2e^y √e^y + x, R [0,4]x[0,1]
fave=
Answers
The average value of the function f(x,y) = 2e^y √(e^y + x) over the rectangle R = [0,4]x[0,1] is approximately 9.936.
This means that if we were to graph the function f(x,y) over the rectangle R and find the height of the "average" point, it would be approximately 9.936.
To find the average value of f(x,y) over R, we need to evaluate the double integral of f(x,y) over R and divide it by the area of R. We can use the formula:
fave = (1/A) ∬R f(x,y) dA
where A is the area of R.
To evaluate the double integral, we first integrate f(x,y) with respect to y, then with respect to x. This yields:
fave = (1/4) [2/3 ((2/5)(e + 4)^(5/2) - (2/5)e^(5/2) - (2/3)(4)^(3/2))]
Simplifying this expression gives us the approximate value of 9.936. This means that the "average" value of the function f(x,y) over the rectangle R is 9.936.
Learn more about average here: brainly.com/question/32204043
#SPJ11
PLEASEEE HELP!!!!!!!!
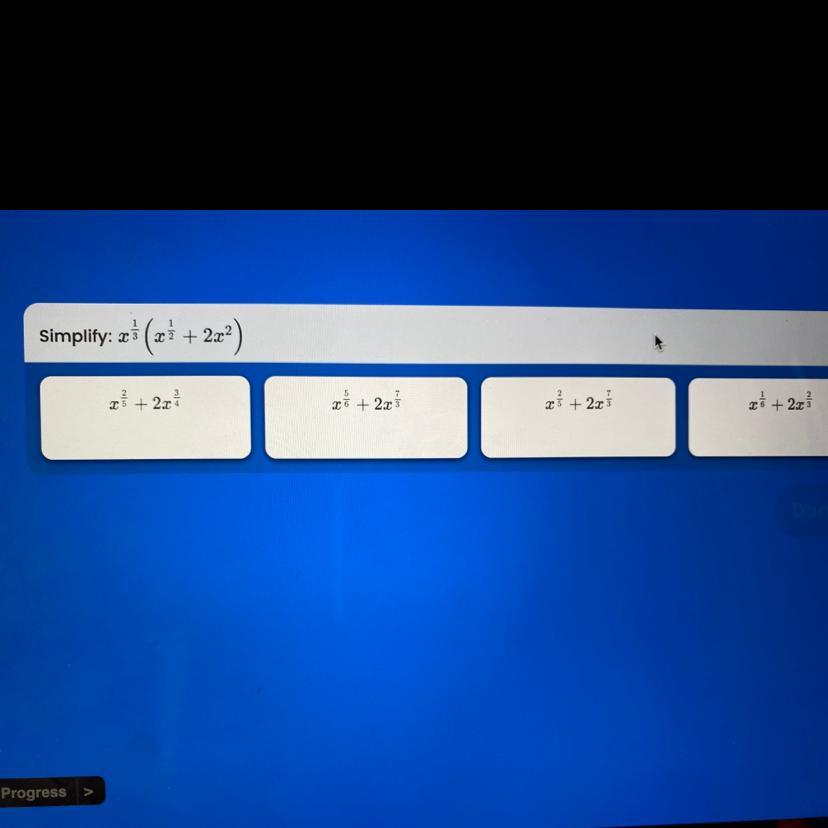
Answers
Answer:
Number 2
Step-by-step explanation:
So you first gotta open the parentheses: When you multiply them you add the exponents
You get x^5/6 + 2x^7/3
Answer:
#2
Step-by-step explanation:
So you first gotta open the parentheses: When you multiply them you add the exponents
You get x^5/6 + 2x^7/3
After that incident, the Civil defense team decided to buy new trucks with ladders higher than 100 feet. They found 2 different trucks with same height of ladders. The first truck costs $145,000 and will cost $0.31 per mile traveled based on the current gas prices. The second truck will cost $160,000 but gets better gas mileage, costing $0.27 per mile. They need to decide which truck is the best deal.
Answers
Answer:
the first truck
Step-by-step explanation:
the cost difference between the first truck and the second truck = $160,000-$145,000 = $15,000
the difference of gas cost between the first truck and the second truck = $0.31 - $0.26= $0.05 per mile.
so,
I think, this is a very significant number of truck cost compared with gas cost
for the best deal, the first truck is the best choice.
Pls give simple working out

Answers
Answer:
x = 33
Step-by-step explanation:
∡ CBE = ∡DBA = 57°
The sum of the interior angles of a triangle results 180°
∡BDA = it´s a right angle = 90°
Then:
57° + 90° + x = 180°
147° + x = 180°
x = 180° - 147°
x = 33°
Two angles are vertical if one is 5x - 15 and the second angle is 3x + 1, what is the value of x
What is the measure of each angle
Answers
Answer:
Step-by-step explanation:
If they are vertical angles, they are opposite to each other where two lines intersect. Vertical angles are equal to each other so
5x-15=3x+1
2x-15=1
2x=16
x=8 degrees.
The angles are
a=5x-15, and x=8 so
a=5(8)-15
a=40-15
a=25 degrees.
1. uniform ml estimation. let x ⇠unif [a, 1] with unknown a. to estimate a, we use a training set {xi}ni=1 generated i.i.d. unif [a, 1]. let ˆxn = min {x1, x 2, æææ, x n}. find the ml estimator of a.
Answers
The maximum likelihood estimator of a is the minimum of the n observations {xi}
The data is generated i.i.d. from a uniform distribution [a, 1], the probability density function (pdf) of each observation is given by:
f(x; a) = 1/(1-a), for a ≤ x ≤ 1
= 0, otherwise
The likelihood function for n observations {xi}ni=1 is the product of their individual pdfs:
L(a; x1, x2, ..., xn) = ∏(1/(1-a)) = (1/(1-a))ⁿ, for a ≤ xi ≤ 1 for all i
The maximum likelihood estimate of a, we need to find the value of a that maximizes the likelihood function.
We can do this by finding the derivative of the log-likelihood function and setting it to zero:
ln L(a; x1, x2, ..., xn) = n ln(1/(1-a))
d/d(a) ln L(a; x1, x2, ..., xn) = -n/(1-a)
Setting the derivative to zero, we get:
n/(a-1) = 0
The derivative is negative for a < 1 and positive for a > 1, the maximum likelihood estimate of a is the smallest observation in the sample:
\(\^a = \^xn\)
= min {x1, x2, ..., xn}
For similar questions on maximum likelihood
https://brainly.com/question/31961355
#SPJ11
The maximum likelihood (ML) estimator of parameter a in the uniform distribution is ˆa = ˆxn.
In this scenario, we have a random variable x that follows a uniform distribution on the interval [a, 1]. The goal is to estimate the unknown parameter a using a training set {xi}ni=1, where each xi is independently and identically distributed (i.i.d.) from the uniform distribution on the same interval [a, 1].
The ML estimator seeks to find the parameter value that maximizes the likelihood function, which measures the probability of obtaining the observed data. In this case, the likelihood function is based on the order statistics of the training set.
The order statistic ˆxn represents the minimum value among the observations in the training set. Since the minimum value occurs when x is closest to the lower bound a, it is reasonable to use ˆxn as the ML estimator for a.
Therefore, the ML estimator of parameter a is ˆa = ˆxn, which corresponds to the minimum value observed in the training set.
To learn more about random variable click here
brainly.com/question/29077286
#SPJ11
(6,7) with a slope of -9 in standard form
Answers
Generally the equation of a line is in the form y=mx+c where m is the slope and c is the y-intercept. We know the slope is -9; so we have
y= -9x+c
Now substitute (6,7) in the equation to find c.
7=-9(6)+c
7=-54+c
c=7+54
c= 61
So equation of line is y = -9x+61
write an explicit formula for an, the nth term of the sequence 5, -20, 80, ...
Answers
Answer:36
Step-by-step explanation:
because