On a Tuesday a friend says he will see you again in 45 days. On what day of the week will he see you? (using discrete mathematics)
Answers
Your friend will see you again on a Friday, 45 days from Tuesday.
To find out on which day of the week your friend will see you again in 45 days, starting on a Tuesday, you can use the concept of modular arithmetic in discrete mathematics. Discrete Mathematics deals with the study of Mathematical structures. It deals with objects that can have distinct separate values. It is also called Decision Mathematics or finite Mathematics. It is the study of mathematical structures that are fundamentally discrete in nature and it does not require the notion of continuity.Objects that are studied in discrete mathematics are largely countable sets such as formal languages, integers, finite graphs, and so on. Due to its application in Computer Science, it has become popular in recent decades. It is used in programming languages, software development, cryptography, algorithms etc. Discrete Mathematics covers some important concepts such as set theory, graph theory, logic, permutation and combination as well. In this article, let us discuss these important concepts in detail.Here's a explanation: Recognize that there are 7 days in a week, Divide 45 days by 7 days to find the remainder: 45 % 7 = 3, Starting on Tuesday (day 1), add the remainder (3) to determine the day of the week: 1 + 3 = 4, Count the days of the week using this value: Tuesday (1), Wednesday (2), Thursday (3), Friday (4).Learn More About Discrete Mathematic's: https://brainly.com/question/27793609
#SPJ11
Related Questions
Identify whether the following data set is unimodal, bimodal, multimodal, or has no mode. Assume the data set is a sample and find the modes, if any exist.28,30,23,41,24,35,41,30,35,33,31
Answers
1. Order the data:
\(23,24,28,30,30,31,33,35,35,41,41\)2. Identify the mode: the number in the data set that occurs most frequently.
For the given data set, the next are the modes:
30
35
41
The three modes have a frequency of 2.
Then, the given data set is polimodal and its modes are: 30, 35 and 41Find the surface area of a cylinder with a helght of 6 in and a base diameter of 8 in.
Use the value 3.14 for T, and do not do any rounding.
Be sure to include the correct unit.
6 in
.
in
in?
in?
8 in
Х
5
?

Answers
Answer:
we know surface area=pi*d*h=3.14*8*5=125.6sqm
Consider the simple linear regression model Yi = β0 + β1Xi + Ei
(a) What is the implication for the regression function if β1 = 0? How would the regression function plot on a graph?
(b) Under the assumption of β1 = 0, derive the least-squares estimate of β0?
Answers
The least-squares estimate of β0 under the assumption of β1 = 0 is given by the mean of the observed response variable Yi.
(a) If β1 = 0 in the simple linear regression model Yi = β0 + β1Xi + Ei, it implies that the coefficient β1, which represents the slope of the regression line, is zero. There is no linear relationship between the predictor variable Xi and the response variable Yi.
When β1 = 0, the regression function simplifies to Yi = β0 + Ei. The regression function becomes a horizontal line with a constant value β0. The value of Yi does not depend on the value of Xi since the slope is zero. The regression line becomes a flat line parallel to the x-axis, indicating that there is no relationship between the predictor variable Xi and the response variable Yi.
The regression function when β1 = 0 would result in a scatter plot of the data points and a horizontal line at the level β0, representing the predicted value for all values of Xi. The line would have a constant height (Y-value) equal to β0, indicating that the response variable does not change with changes in the predictor variable.
(b) Under the assumption of β1 = 0, the least-squares estimate of β0. In simple linear regression, the least-squares estimate of β0 can be obtained by minimizing the sum of squared residuals.
The sum of squared residuals (SSR) is given by:
SSR = Σ[ i=1 to n ] (Yi - Yi)²,
where Yi represents the observed response variable, Yi represents the predicted response variable based on the regression model, and n is the total number of data points.
When β1 = 0, the predicted response variable Yi simplifies to Yi = β0. Substituting this into the SSR equation:
SSR = Σ[ i=1 to n ] (Yi - β0)².
The least-squares estimate of β0 the SSR equation with respect to β0 and set it equal to zero to minimize the sum of squared residuals:
d/dβ0 (SSR) = -2Σ[ i=1 to n ] (Yi - β0) = 0.
Simplifying the equation:
Σ[ i=1 to n ] (Yi - β0) = 0.
Expanding the sum:
Σ[ i=1 to n ] Yi - nβ0 = 0.
Rearranging the equation:
Σ[ i=1 to n ] Yi = nβ0.
Finally, solving for β0:
β0 = (1/n) Σ[ i=1 to n ] Yi.
To know more about squares here
https://brainly.com/question/30556035
#SPJ4
at the forrester manufacturing company, one repair technician has been assigned the responsibility of maintaining four machines. for each machine, the probability distribution of the running time before a breakdown is exponential, with a mean of 8 hours. the repair time also has an exponential distribution, with a mean of 4 hours. (a) find the probability distribution of the number of machines not running, and the mean of this distribution. (b) what is the expected fraction of time that the repair technician will be busy?
Answers
(a) The probability distribution of the number of machines not running, and the mean of this distribution is 0.899.
(b)The expected fraction of time that the repair technician will be busy is 88.9% of the time.
(a) Let X be the number of machines not running. At that point, X can take on values 0, 1, 2, 3, or 4. We will discover the likelihood conveyance of X as takes after:
P(X = 0) = P(all machines are running) = \(e^(-84)^4\)/4! = 0.302
P(X = 1) = P(one machine isn't running) = (4)(\(e^(-84)^3\)/3!) = 0.393
P(X = 2) = P(two machines are not running) = (6)(\(e^(-84)^2\)/2!) = 0.236
P(X = 3) = P(three machines are not running) = (4)(\(e^(-84)^1\)/1!) = 0.067
P(X = 4) = P(all machines are not running) = \(e^(-8*4)^0\)/0! = 0.002
The cruel(mean) of this dispersion is E(X) = (0)(0.302) + (1)(0.393) + (2)(0.236) + (3)(0.067) + (4)(0.002) = 0.899.
(b) Let Y be the division of time that the repair specialist is active. At that point, Y can be communicated as
Y = T/(T + R),
where T is the full time that machines are not running
and R is the entire time that went through on repairs.
We know that
T has an Erlang dispersion with parameters
n = 4 and λ = 1/8 (since the running time of each machine has exponential dissemination with cruel 8 hours).
Subsequently, the anticipated esteem of T is E(T) = n/λ = 32 hours.
Additionally, R has an exponential dispersion with cruel 4 hours,
so E(R) = 4 hours. In this way, we have:
E(Y) = E(T/(T + R))
= E(T)/E(T + R)
= 32/(32 + 4)
= 0.889.
In this manner, ready to anticipate the repair professional to be active around 88.9% of the time.
To know more about probability refer to this :
https://brainly.com/question/24756209
#SPJ4
as a statistician, you conducted an experiment and obtained a t-test value for the two experimental groups. at a significance level of 5%, the corresponding statistical p-value of 0.067 would suggest that:
Answers
There is a 6.7 percent probability that you are making a mistake by failing to reject the null hypothesis. Hence, option C is the correct answer to this question.
The p-value is a measure of the evidence against a null hypothesis. A smaller p-value means that there is stronger evidence against the null hypothesis. A common threshold for rejecting the null hypothesis is a p-value of less than 0.05, which corresponds to a confidence level of 95%. In this case, the p-value of 0.067 is greater than 0.05, meaning that there is not enough evidence to reject the null hypothesis and conclude that there is a statistically significant difference between the two experimental groups. Therefore, there is a 6.7% probability that you are making a mistake by failing to reject the null hypothesis, which means that the two experimental groups may be statistically identical.
Read more about p-value:
brainly.com/question/13786078
#SPJ4
The complete question is -
As a statistician, you conducted an experiment and obtained a t-test value for the two experimental groups. At a confidence level of 5 percent, the corresponding statistical p-value of 0.067 would suggest that:
a. The inherent error of the experiment is calculated to be 6.7 percent.
b. There is probably a statistically significant difference between the two groups of interest.
c. There is a 6.7 percent probability that you are making a mistake by failing to reject the null hypothesis.
d. There is a 6.7 percent probability that you are making a mistake in accepting the experimental hypothesis.
e. The two experimental groups are statistically identical.
TIME LIMITED
Points L, M, and N are collinear. You are given LM = 18 and LN = 27. What is a possible value of MN?
Group of answer choices
6
9
7
8
Answers
The value of MN is 9. So, the second option is correct.
It is given that,
Points L, M, and N are collinear. LM = 18 and LN = 27.Explanation:
Points L, M, and N are collinear. It means, there three points lie on a straight line.
Using the segment addition property, we get
\(LM+MN=LN\)
\(18+MN=27\)
\(MN=27-18\)
\(MN=9\)
Thus, the second option is correct.
Learn more:
https://brainly.com/question/1593959

find the value of given expression
\( \sqrt{ \frac{1}{4} } \)
Answers
![find the value of given expression[tex] \sqrt{ \frac{1}{4} } [/tex]](https://i5t5.c14.e2-1.dev/h-images-qa/answers/attachments/dC0GkmQJBw6HlGrvaLWba5DbLho2DXS9.png)
Pls Help, I will give 5 star and thanks, Plus Brain to correct answer, Plus extra points if correct!!
The table shows the relationship between the participants walking and running for the week's cross-country practices.
Walk (laps) 3 B 15
Run (laps) 5 10 D
Total (laps) A C 40
At this rate, how many laps will the participants walk if the total distance is 32 miles? How many miles will they run?
They will walk 7 laps and run 17 laps for a total of 32 miles.
They will walk 12 laps and run 20 laps for a total of 32 miles.
They will walk 14 laps and run 18 laps for a total of 32 miles.
They will walk 10 laps and run 22 laps for a total of 32 miles.

Answers
Using proportional relationships, we can say that They will walk 12 laps and run 20 laps for a total of 32 miles.
What is the direct proportional relationship?In a direct proportional relationship, the output variable is found by the multiplication of the input variable and the constant of proportionality k, as follows:
y = kx.
Given that we know this, they walk 3/8 of the 8 miles that make up the complete distance. Run 5/8 of the route.
The following are the proportional relationships for the distances:
Walked = 3/8 x Total Distance.Ran = 5/8 x Total Distance.For a total distance of 32 miles, the distances walked and run are given:
Walked: 3/8 x 32 = 3 x 4 = 12 miles = 12 laps.Ran: 5/8 x 32 = 5 x 4 = 20 miles = 20 laps.therefore, They will walk 12 laps and run 20 laps for a total of 32 miles as per the proportional relation.
Learn more about proportional relationships here: brainly.com/question/10424180
#SPJ1
The cube is 6 inches whats the volume ?
Answers
Answer:
216 inches^3 is the volume.
Step-by-step explanation:
Given,
length = 6in.
volume =?
we know,
volume of cube = L^3
= (6in.)^3
= 216inches cube
X^2 - 16 (Factoring)
Answers
Answer:
(x - 4)(x + 4)
Step-by-step explanation:
x² - 16 ← is a difference of squares and factors in general as
a² - b² = (a - b)(a + b) , then
x² - 16
= x² - 4²
= (x - 4)(x + 4)
What does g equal?10g+8=8g
Answers
Answer:
-4
Step-by-step explanation:
Subtract 10g from both sides
8 = -2g
divide by negative 2
g = -4
Answer:
-4
Step-by-step explanation: Hope this helps you out!!
btw can i have brainliest?
8=−2/5c
Help me
I’m single ready to mingle
Answers
Answer:
-20
Step-by-step explanation:
First, you divide both sides by -2/5, which would get you c = 8 * -5/2 (Because when you divide, you multiply by the reciprocal). 8 * -5/2 is equal to -20. The answer is -20.
n2 + n = 56 solution
Answers
Answer:
n = -8, 7
Step-by-step explanation:
Your equation is:
\(\displaystyle{n^2+n=56}\)
Arrange the terms in the quadratic expression, ax² + bx + c:
\(\displaystyle{n^2+n-56=0}\)
Factor the expression, thus:
\(\displaystyle{\left(n+8\right)\left(n-7\right)=0}\)
This is because 8n-7n = n (middle term) and 8(-7) = -56 (last term). Then solve like a linear which results in:
\(\displaystyle{n=-8,7}\)
Hello!
\(\sf n^2 + n = 56\\\\n^2 + n - 56 = 0\\\\\\n = \dfrac{-b\±\sqrt{b^2-4ac} }{2a} \\\\\\n = \dfrac{-1\±\sqrt{1^2-4*1*(-56)} }{2*1}\\\\\\n = \dfrac{1\±15}{2} \\\\\\\boxed{\sf n = 7 ~or ~-8 }\)
PLEASE HELP ME ASAP?!?
(look at the image)
What is the order, from widest to narrowest graph, of the
quadratic functions f(x) = -0.5x2, f(x) = 1/4x2, and f(x) = x2?

Answers
Answer:
f(x) = \(\frac{1}{4}x^{2}\) > f(x) = -0.5x² > f(x) = x²
Step-by-step explanation:
In a quadratic function leading coefficient decides the width of a graph.
In simpler words, leading coefficient decides the vertical stretch of the graph.
Higher the value of leading coefficient, higher the vertical stretch.
When a graph is vertically stretched it becomes narrower.
(Note: Minus sign of the coefficient decides the opening of the graph, upwards or downwards)
Therefore, f(x) = x² having coefficient = 1 is the narrowest and f(x) = \(\frac{1}{4}x^{2}\) will be the widest.
So the descending order will be,
f(x) = \(\frac{1}{4}x^{2}\) > f(x) = -0.5x² > f(x) = x²
What is the answer of Thomas made 8,700 mL8,700 mL8, comma, 700, start text, space, m, L, end text of tomato soup. He packed 1.6 L1.6 L1, point, 6, start text, space, L, and end text of the soup in his kids' lunches. He then froze half of the remaining soup.
How many milliliters of soup did Thomas freeze?..... ml
Answers
Thomas packed 1.6 L1.6 L1, point, 6, start text, space, L, and end text of the soup in his kids' lunches and had firmed 7100 ml of haze.
What's meant by equation?
A fine statement known as an equation is made up of two expressions joined together by the equal sign. A formula would be 3x- 5 = 16, for case. When this equation is answered, we discover that the value of the variable x is 7. The description of an equation in algebra is a fine statement that demonstrates the equivalency of two fine expressions. For case, the two equations 3x 5 and 14, which are separated by the' equal' sign, make up the equation 3x 5 = 14. An equation is a fine expression with two equal sides and an equal sign. 4 6 = 10 is an illustration of an equation.Given that;
He made 8700 ml haze and he packed1.6 liter haze.
1 liter = 1000 milliliters
liter = 1.6 × 1000
litre = 1600 ml
Chancing the firmed haze-
8700 ml- 1600 ml
7100 ml.
Hence
Frozen haze = 7100 milliliters.
To learn more about equation, refer to:
brainly.com/question/1859113
#SPJ1
discouraging consumers from purchasing products from an insurer is called
Answers
Discouraging consumers from purchasing products from an insurer is referred to as "consumer dissuasion." It involves implementing strategies or tactics to dissuade potential customers from choosing a particular insurance company or its products.
Consumer dissuasion is a practice employed by insurers to discourage consumers from selecting their products or services. This strategy is often used to manage risk by discouraging individuals or groups that insurers perceive as having a higher likelihood of filing claims or incurring higher costs. Insurers may employ various techniques to dissuade potential customers, such as setting higher premiums, imposing strict eligibility criteria, or offering limited coverage options. The purpose of consumer dissuasion is to selectively attract customers who are deemed less risky or more profitable for the insurer, thereby ensuring a healthier portfolio and reducing potential losses. By implementing strategies that discourage certain segments of the market, insurers can manage their risk exposure and maintain profitability. It is important to note that consumer dissuasion practices should adhere to applicable laws and regulations governing the insurance industry, including fair and transparent practices. Insurers are expected to provide clear and accurate information to consumers, enabling them to make informed decisions about insurance coverage and products.
Learn more about insurance company here:
https://brainly.com/question/32110345
#SPJ11
A store manager kept track of the number of newspapers sold each week over a seven-week period. The results are shown below. \( 87,87,215,154,288,235,231 \) Find the median number of newspapers sold.
Answers
The median number of newspapers sold over seven weeks is 223.
The median is the middle score for a data set arranged in order of magnitude. The median is less affected by outliers and skewed data.
The formula for the median is as follows:
Find the median number of newspapers sold. (87, 87, 215, 154, 288, 235, 231)
We'll first arrange the data in ascending order.87, 87, 154, 215, 231, 235, 288
The median is the middle term or the average of the middle two terms. The middle two terms are 215 and 231.
Median = (215 + 231)/2
= 446/2
= 223
In statistics, the median measures the central tendency of a set of data. The median of a set of data is the middle score of that set. The value separates the upper 50% from the lower 50%.
Hence, the median number of newspapers sold over seven weeks is 223.
To know more about the median, visit:
brainly.com/question/300591
#SPJ11
6. which of the fundamental questions of risk management (consider all twelve) would benefit from using pairwise ranking? why?
Answers
The fundamental questions of risk management that would benefit from using pairwise ranking are those related to prioritizing risks and deciding which risks to address first.
Pairwise ranking is a technique used to compare and prioritize items by comparing them in pairs and determining which one is more important or has a higher priority. This technique can be used to prioritize risks based on their likelihood and impact.
The risk management that would benefit from using pairwise ranking include:
- Which risks should be addressed first?
- Which risks have the highest likelihood of occurring?
- Which risks have the highest impact on the project or organization?
- Which risks should be given the most attention and resources?
By using pairwise ranking, risk managers can prioritize risks and make more informed decisions about which risks to address first and which risks to allocate the most resources to. This can help ensure that the most important risks are addressed first and that resources are used effectively to manage risks.
Learn more about fundamental questions of risk management about here:https://brainly.com/question/13760012
#SPJ11
3(x-3) = 20 what is x
Answers
Answer:
x ≈ 9.7
how mny decimal places do u need?
Step-by-step explanation:
3( x-3 )= 20
>3x - 9 = 20
>3x = 29
> x= 9.66666667
3/4 + 3/4 in simplset form
Answers
Answer:
6/4 or 3/2
Step-by-step explanation:
Answer:
The answer should be 3/2
2 chairs every 10 minutes
Answers
For 5 chairs, the machine needs 25 minutes.
What does word 'proportion' means?A percentage in mathematics is an equation that connects two or more ratios and declares that they are equal. Two values are compared in a ratio, which is frequently stated as a fraction or the division of two integers. A percentage, which usually takes the form: expresses the equivalence of two or more ratios.
a/b = c/d
Given:
Rate of production = 2 chairs every 10 minutes
Time taken to make 5 chairs
2 chairs / 10 minutes = 5 chairs / x minutes
Cross-multiplying,
2 * x = 10 * 5
2x = 50
Dividing both sides by 2:
x = 50 / 2
x = 25
Learn more about proportions here:
https://brainly.com/question/30657439
#SPJ1
Complete Question: a machine factory makes chairs at a rate 2 chair every 10 minutes how much time does machine take to make five chairs?
Solve the following radical equations.
∛x-1=√x-1
Answers
The solution of the radical equation of x is 1.
A linear equation in one variable is an equation which can be represented in the form of ax+b where x is the variable and 'a' is the coefficient and 'b' is the two constants.
A radical equation is defined as an equation where the variable is under a radical or root.
We know that n-th root of a variable x can be written as x to the power of (1/n). Mathematically : \(\sqrt[n]{x} =x^{\frac{1}{n} }\)
In the given equation:
∛x-1=√x-1
adding 1 to both sides we get:
or, ∛x=√x
Cross multiplying we get:
or, ∛x/√x =1
We know that (aˣ/aⁿ)=a⁽ˣ⁻ⁿ⁾
therefore :
or, \(x^{\frac{1}{3}-\frac{1}{2} }=1\)
or, \(x^{-\frac{1}{6} }=1\)
or, x=1
Hence the value of x in the radical equation is 1
To learn more about radical equations visit:
https://brainly.com/question/11631690
#SPJ4
solve for u 2(4u-9)=14
plzzzz
will give brailiest
Answers
u=4
EXPLANATION:
distribute the 2 and simplify.
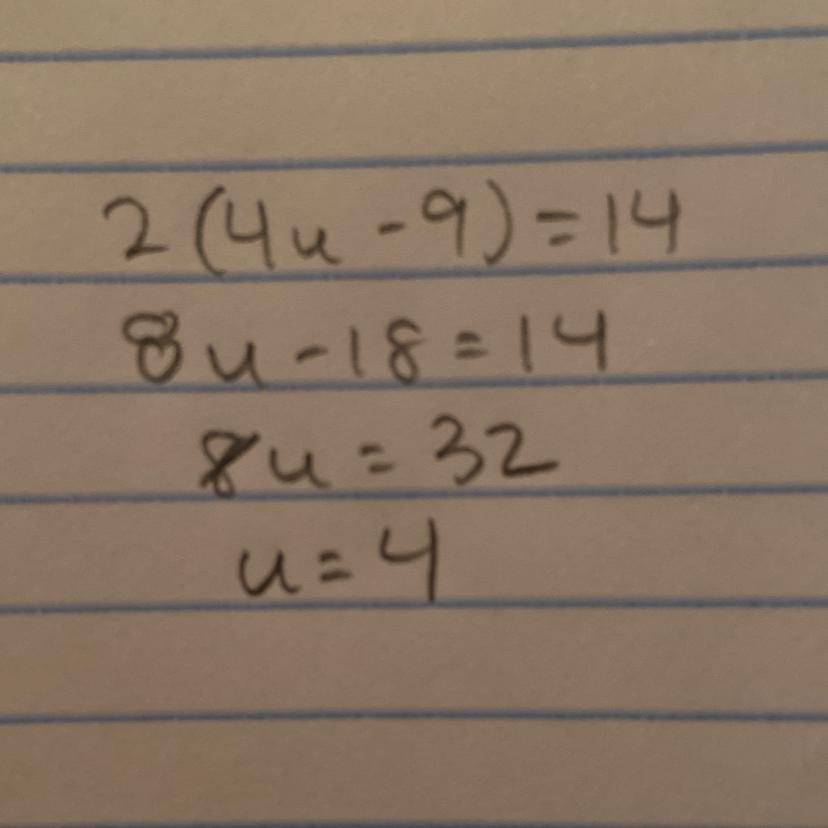
Answer:
4 is the answer
Step-by-step explanation:
2 (4u-9)=14
8u-18=14
8u=14+18
8u =32
divide by 8
u=4 answer
A rectangular prism has a volume of 240 cubic feet. If the length is 4 feet and the width is 4 feet, what is the height of
the prism?
Answers
Answer:
Let's use the formula for the volume of a rectangular prism;
V = l · w · h
Where 'l' represents the length, 'w' stands for the width, and 'h' displays as the height. (V evidently stands for the volume)
What we know:
Volume = 240 ftLength = 4 ftWidth = 4 ftWhat we need to find out:
HeightLet's plug in what we know into the formula:
V = l · w · h
240 = 4 · 4 · h
Now let's solve for h:-
240 = 16 · h
240 = 16h
Get rid of h's co-efficient by dividing 16 from both sides because the inverse operation of multiplication(since 16 is being multiplied by h) is division.
÷16 ÷16
Finally, you would end up with a result of:
15 = h
Hence, the height of this prism is 15 feet.
If m AB = 50° and mCD = 24°, what is the value of x? The figure is not drawn to scale.
x=26°
x= 62°
x=37°
x=74°

Answers
The measure of x is 37 degree.
We have the measure of two arc as
m AB = 50 and m CD- 24.
Now, the measure of the inner angle is the semi-sum of the arcs comprising it and its opposite.
So, x= (m AB + m CD) / 2
x= (50 + 24)/2
x = 74 / 2
x= 37 degree
Thus, the measure of x is 37 degree.
Learn more about Arc here:
https://brainly.com/question/12621139
#SPJ1
In a recent election, 63% of all registered voters participated in voting. In a survey of 275 retired voters, 162 participated in voting. Which is higher, the population proportion who participated or the sample proportion from this survey?
Answers
The population proportion who participated in voting (63%) is higher than the sample proportion from this survey (58.91%).
To determine whether the population proportion who participated in voting or the sample proportion from the survey is higher, we need to compare the percentages.
The population proportion who participated in voting is given as 63% of all registered voters.
This means that out of every 100 registered voters, 63 participated in voting.
In the survey of retired voters, 162 out of 275 participants voted. To calculate the sample proportion, we divide the number of retired voters who participated (162) by the total number of retired voters in the sample (275) and multiply by 100 to get a percentage.
Sample proportion = (162 / 275) \(\times\) 100 ≈ 58.91%, .
Comparing the population proportion (63%) with the sample proportion (58.91%), we can see that the population proportion who participated in voting (63%) is higher than the sample proportion from this survey (58.91%).
Therefore, based on the given data, the population proportion who participated in voting is higher than the sample proportion from this survey.
It's important to note that the sample proportion is an estimate based on the surveyed retired voters and may not perfectly represent the entire population of registered voters.
For similar question on population proportion.
https://brainly.com/question/29516589
#SPJ8
Geographic data are often classified for mapping, name
and explain the 5 factors that influence classification decisions.
(10 marks)
Answers
The five factors influencing classification decisions for geographic data mapping are scale, purpose, data availability, technology, and stakeholder input.
Here are five key factors:
1. Scale: The scale at which the map will be produced plays a crucial role in classification decisions. Different features and attributes may be emphasized or generalized based on the map's scale.
2. Purpose: The intended purpose of the map, such as navigation, land use planning, or environmental analysis, affects classification decisions. Each purpose may require different levels of detail and categorization.
3. Data Availability: The availability and quality of data influence classification decisions. Depending on the data sources and their accuracy, certain features may be classified differently or excluded altogether.
4. Technology: The tools and technology used for classification, such as remote sensing or GIS software, impact the decision-making process. Different algorithms and methods can lead to variations in classification outcomes.
5. Stakeholder Input: Stakeholder requirements and preferences can influence classification decisions. Input from users, experts, and decision-makers helps ensure that the map meets their specific needs and expectations.
Therefore, The five factors influencing classification decisions for geographic data mapping are scale, purpose, data availability, technology, and stakeholder input.
To learn more about Data Availability click here brainly.com/question/30271914
#SPJ11
solve the equation of 5/2x=25/4
Answers
ANSWER
x = 2/5
EXPLANATION
We want to solve the equation below:
\(\frac{5}{2x}\text{ = }\frac{25}{4}\)To do this, we cross multiply:
2x * 25 = 5 * 4
50x = 20
\(\begin{gathered} \Rightarrow\text{ x = }\frac{20}{50} \\ x\text{ = }\frac{2}{5} \end{gathered}\)That is the solution.
4. Linear Dependence in a Square Matrix Learning Objective: This is an opportunity to practice applying proof techniques. This question is specifi- cally focused on linear dependence of rows and columns in a square matrix. Let A be a square n x n matrix, (i.e. both the columns and rows are vectors in R"). Suppose we are told that the columns of A are linearly dependent. Prove, then, that the rows of A must also be linearly dependent. You can use the following conclusion in your proof: If Gaussian elimination is applied to a matrix A, and the resulting matrix (in reduced row echelon form) has at least one row of all zeros, this means that the rows of A are linearly dependent. (Hint: Can you use the linear dependence of the columns to say something about the number of solutions to Ai=? How does the number of solutions relate to the result of Gaussian elimination?).
Answers
The key approach is to analyze the relationship between the number of solutions to the equation Ax = 0 and the result of Gaussian elimination.
Since the columns of A are linearly dependent, there exist scalars c1, c2, ..., cn (not all zero) such that c1a1 + c2a2 + ... + cnan = 0, where ai represents the columns of A. We can rewrite this equation as a system of linear equations: Ax = 0, where x = [c1, c2, ..., cn]T is a column vector.
The linear dependence of the columns implies that the system Ax = 0 has infinitely many solutions, as we can always find non-trivial combinations of the columns that yield the zero vector.
Now, let's consider applying Gaussian elimination to matrix A. Gaussian elimination transforms the matrix into reduced row echelon form. If the resulting matrix has at least one row of all zeros, it means that there is at least one free variable in the system Ax = 0. This indicates that the system has infinitely many solutions.
Since the system Ax = 0 has infinitely many solutions, and the result of Gaussian elimination with a row of all zeros indicates linear dependence, it follows that the rows of A must also be linearly dependent. Therefore, the linear dependence of the columns implies the linear dependence of the rows.
Learn more about matrix here : brainly.com/question/29132693
#SPJ11
Apples cost $1.99 per pound. How much do 314 pounds of apples cost? $ How much do x pounds of apples cost? $ Clare spent $5.17 on apples. How many pounds of apples did Clare buy? pounds
Answers
Answer:
1. $624.86
2. 1.99x
3. 2.6 pounds
Step-by-step explanation:
1. Multiply 1.99 by 314 to get 624.86
2. With the equation 1.99x, you can substitute any variable into it and it will hold true.
3. Divide 5.17 by 1.99, the price, and you get 2.597 pounds, which rounds to 2.6