Problem 18 Last summer, Lisa and her family went on vacation. They drove from their home to Florida. They drove four days, about 540 miles each day. About how many miles did they drive altogether?
Answers
Answer:
2160
Step-by-step explanation:
Distance covered per day =540miles
Number of days travelled = 4 days
Therefore,the mil we s travelled altogether= 540×4= 2160
Related Questions
please help me very fast

Answers
Multiply 7 by 60 because each hour has 60 minutes.
From the chart we see 2 hours is 120 minutes so we can divide 120 by 2 to get 1 hour = 60
Answer:
multiply 7 by 60,because each hours has 60 munites
Hours minutes per hours. total minutes
(hrs*minutes per hour)
2. 60. 120
3 60. 180
4. 60. 240
7 60. 420
On a snow day, Moussa created two snowmen in his backyard. Snowman A was built to a height of 59 inches and Snowman B was built to a height of 39 inches. The next day, the temperature increased and both snowmen began to melt. At sunrise, Snowman A's height decrease by 9 inches per hour and Snowman B's height decreased by 4 inches per hour. Let � A represent the height of Snowman A � t hours after sunrise and let � B represent the height of Snowman B � t hours after sunrise. Write an equation for each situation, in terms of � , t, and determine the number of hours after sunrise when both snowmen have an equal height.
Answers
Answer:
Step-by-step explanation:
Both snowmen will have an equal height after 4 hours after sunrise.
To understand the reasoning behind the equations and solutions, we can break down the problem into several steps.
First, we are given the initial heights of Snowman A and Snowman B, 59 and 39 inches, respectively.
Next, we are told that the height of Snowman A decreases by 9 inches per hour and the height of Snowman B decreases by 4 inches per hour. This means that after t hours, the height of Snowman A will be 59 - 9t and the height of Snowman B will be 39 - 4t.
To find the number of hours after sunrise when both snowmen have an equal height, we need to set A = B and solve for t. This gives us the equation:
59 - 9t = 39 - 4t
Solving for t, we get:
20 = 5t
t = 4
To learn more about height follow the link:
https://brainly.com/question/29117133
#SPJ1
5/6 - 1/9 = ?/? - ?/? = ?/?
please help 20 points
i need to know what each ( ?/? ) is
Answers
5/6 - 1/9=?/? - ?/? = ?/? , value of each (?/?) is
5/6 -1/9 =15 /18 -2/18 =13 /18.
As given,
5/ 6 - 1/9 =?/? -?/? =?/?
Convert the given terms into like terms
Least common multiple of (6,9)=18
Value of each ( ?/?)
(5/6 ) × ( 3/3) -(1/9) × (2/2)
= 15 /18 - 2/18
= 13 /18
Therefore,5/6 - 1/9 = ?/? - ?/? = ?/? , value of each (?/?) is equal to
5/6 -1/9 = 15 /18 -2/18 = 13/18.
Learn more about value here
brainly.com/question/1578158
#SPJ4
Instructions: Find FS if BS=16.
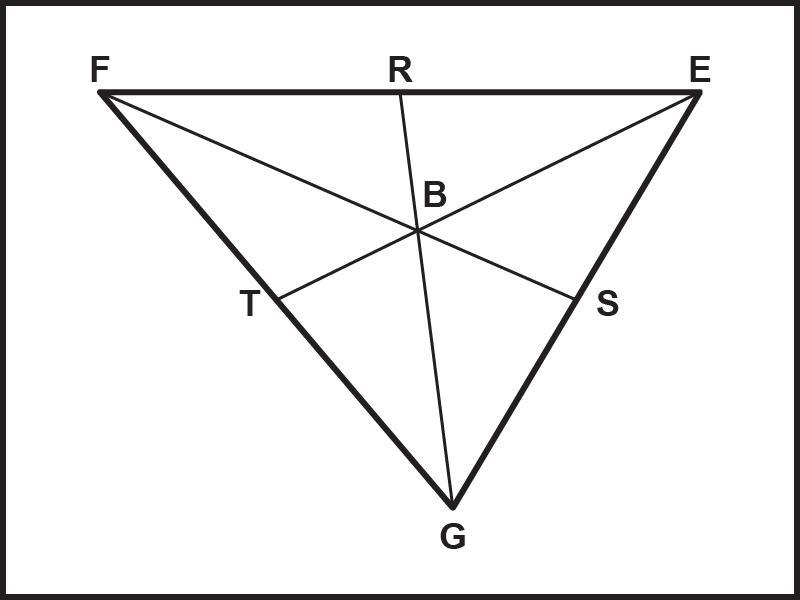
Answers
Answer:
48
Step-by-step explanation:
FB:BS=2:1
\(\frac{FB}{BS} =\frac{2}{1} \\add~1~to~both~sides\\\frac{FB}{BS} +1=\frac{2}{1} +1=3\\\frac{FB+BS}{BS} =3\\\frac{FS}{BS} =3\\FS=3 \times~BS\\FS=3 \times~16=48\)
Answer:
48
Step-by-step explanation:
After an alcoholic beverage is consumed, the concentration of alcohol in the bloodstream (blood alcohol concentration, or BAC) surges as the alcohol is absorbed, followed by a gradual decline as the alcohol is metabolized. The function C(t)=0.135 t e^{-2.802 t}C(t)=0.135te −2.802t models the average BAC, measured in g/dL, of a group of eight male subjects t hours after rapid consumption of 15 mL of ethanol (corresponding to one alcoholic drink) What is the maximum average BAC during the first 3 hours? When does it occur?
Answers
It gradually decreases as alcohol is metabolized. The function C(t)=0.135 t e^{-2.802 t}models the mean BAC measured in g/mL.
The maximum average BAC during 3 hours is 0.0001358 g/mL.
f(t) = α t e−βt --(1)
Let's rewrite this in a simple form:
f(t)= α eˡⁿ ᵗ e⁻βt = αe^(ln t −βt)
Since e^x is strictly increasing and it will be maximized exactly when its argument is maximized, so we can maximize instead:
g(t)=ln t −βt
differentiating with respect to t , and g'(t) = 0
g′(t)=1/t − β = 0
=> t =1/β
we have given a function
C(t)=0.135 t e⁻²·⁸⁰²ᵗ
if we compare it with (1) we get
β = 2.802, 0.135 = α
For it's maximized we need to check the second order condition, and that of g will differentiate again , g′′(t)= −1/t² < 0
We have to compute the derivative of C(t):
C′(t) = 0.135 t⋅(−2.802)e⁻²·⁸⁰²ᵗ + 1.35e⁻²·⁸⁰²ᵗ
For optimum at t₀ if C′(t₀)=0 and C′′(t₀)≠0. Here, we have
C′(t₀) = 0.135t₀⋅(−2.802)e⁻²·⁸⁰²ᵗ₀+ 0.135e⁻²·⁸⁰²ᵗ₀ =e⁻²·⁸⁰²ᵗ₀(−0.135* 2.802t₀+ 0.135)=0
It is clear that e⁻²·⁸⁰²ᵗ₀ not equal to zero for all t₀∈R, so that
=> −0.135* 2.802t₀+0.135=0
=> t₀ = 1/2.802 ≈0.36
let us consider t is in hours, so that it makes t₀ =0.36h≈21.41min. This is the only optimum and one should verify it is indeed a maximum, i.e. C′′(t₀)<0.
Now, easily compute the maximum average BAC, which is C(t₀)=C(0.36) = 0.135 (0.36)e⁻²·⁸⁰²⁽⁰·³⁶⁾
= 0.0486(0.3678) = 0.01787508
Hence, the maximum average BAC, is 0.017 g/dL.
Maximum average BAC during the first 3 hours,
t = 3 , C(t)=C(3) = 0.135 (3)e⁻²·⁸⁰²⁽³⁾ = 0.0001358 g/mL
To learn more about Exponential function, refer:
https://brainly.com/question/12626186
#SPJ4
Can anyone help me with this question?

Answers
Answer:
the answer is number 2
Step-by-step explanation:
hope this helps u
When describing categorical data, you can use: counts and proportions measures of center, spread, and shape All of these statements are correct. box plot None of these statements are correct.
Answers
All of these statements are correct.
When describing categorical data, several methods can be used to provide meaningful insights and summarize the data.
Counts and proportions: Counting the number of observations in each category can provide information about the distribution and frequency of different categories. Proportions, also known as percentages, can be calculated by dividing the count in each category by the total count, allowing for a comparison of the relative frequencies of different categories.
Measures of center, spread, and shape: Although measures of center, spread, and shape are commonly associated with numerical data, they can also be used to describe certain aspects of categorical data. For example, the mode represents the most frequent category, which can be considered a measure of center. Measures of spread, such as the range or interquartile range, may not be applicable to categorical data. However, bar graphs and pie charts can visually depict the distribution and shape of categorical variables.
Box plots: Box plots are graphical representations primarily used for numerical data. They display the median, quartiles, and any potential outliers. While box plots are not commonly used for categorical data, they can be adapted by representing the frequency or proportion of categories instead of numerical values.
In summary, when describing categorical data, counts and proportions are commonly used to present the frequency and relative frequency of categories. Measures of center, such as the mode, can provide insights into the most frequent category. Measures of spread and shape may not be applicable, but graphical representations like bar graphs and pie charts can be used to visualize the distribution and shape of the categorical data. Box plots are not typically used for categorical data, as they are more suitable for numerical variables.
Learn more about numerical variables here:
brainly.com/question/30527805
#SPJ11
The function m is given in three equivalent forms. Which form most quickly reveals the vertex
Answers
Answer:
m (x) = -2(x-6)^2 +18
Step-by-step explanation:
Gail has $5,500 that she wants to put in a new savings account. She is considering two banks that are very similar. One difference she notices are the interest rates:
Neighborhood Bank - 1.2% interest, compounded annually
Beautiful Day Bank - 1.2% interest, compounded daily
Based on interest, which bank would you suggest Gail pick if she plans to have her money in the account for 15 years
Answers
The bank she would suggest is Neighborhood Bank - 1.2 % interest, compounded weekly.
How to find the compound interest?If n is the number of times the interested is compounded each year, and 'r' is the rate of compound interest annually, then the final amount after 't' years would be:
A = P \((1 + r/n)^{nt\)
Given:
Gail has $5,500 that she wants to put in a new savings account.
Neighborhood Bank - 1.2% interest, compounded weekly
Beautiful Day Bank - 1.2% interest, compounded daily
Thus, $5,500 x 1.2% = $66
$66 a day times 360 days = $23,760
and, $23,760 times 20 = $475, 200.
and, $257,400 times 20 = $9504000
Hence, The bank she would suggest Gail pick is Neighborhood Bank - 0.65% interest, compounded weekly.
Learn more about compound interest here:
brainly.com/question/1329401
#SPJ1
Four times a number decreased by 25
is the same as the opposite of the number. Find the number
Answers
Answer:
x = 5
Step-by-step explanation:
Translate the word problem into an equation and solve for x
4x - 25 = -x
Add 25 to both sides
4x = -x + 25
Add x to both sides
5x = 25
Divide both sides by 5
x = 5
What is the vertical distance between (2, 11/3)
and (2, - 4/3)?
Answers
The vertical distance between (2, 11/3) and (2, -4/3) is -5 units.
Define distance formulaThe distance formula is a mathematical equation used to find the distance between two points in a plane. It is derived from the Pythagorean theorem and is expressed as:
d = √((x₂- x₁)²+ (y₂ - y₁)²)
The distance formula can also be extended to three-dimensional space by adding an additional term to the equation.
The two points (2, 11/3) and (2, -4/3) have the same x-coordinate, which means they lie on a vertical line. To find the vertical distance between these two points, we simply subtract their y-coordinates:
Vertical distance = (y-coordinate of second point) - (y-coordinate of first point)
= (-4/3) - (11/3)
= -15/3
= -5
Therefore, the vertical distance between (2, 11/3) and (2, -4/3) is -5 units. Since this is a negative value, it means that the second point is located 5 units below the first point.
To know more about coordinate, visit:
https://brainly.com/question/16634867
#SPJ9
Sketch the region enclosed by the given curves. decide whether to integrate with respect to x or y. then find the region of the area. y=1/x, y=1/x^2, x=6
Answers
The integral for finding the area of the region is:
A = ∫[lower bound]^[upper bound] [rightmost bound] dy
A = ∫[1/6]^∞ [6] dy
To sketch the region enclosed by the curves and determine whether to integrate with respect to x or y, let's analyze the given equations:
y = 1/x
y = 1/x^2
x = 6
To begin, let's plot these curves on a coordinate plane:
First, we can observe that both equations involve hyperbolas. The equation y = 1/x represents a hyperbola that passes through the points (1,1), (2,0.5), (-1,-1), etc. The equation y = 1/x^2 represents a hyperbola that passes through the points (1,1), (2,0.25), (-1,1), etc.
Next, the equation x = 6 represents a vertical line passing through the point (6,0) on the x-axis.
Now, to determine the enclosed region, we need to find the limits of integration.
Since the curves intersect at certain points, we need to find these points of intersection. Equating the two equations for y and solving, we get:
1/x = 1/x^2
Multiplying both sides by x^2 yields:
x = 1
Hence, the curves intersect at x = 1.
Therefore, the region enclosed by the curves is bounded by the following:
The curve y = 1/x,
The curve y = 1/x^2,
The vertical line x = 6, and
The x-axis.
To determine whether to integrate with respect to x or y, we need to consider the orientation of the curves. In this case, the curves are defined in terms of y = f(x). Thus, it is more convenient to integrate with respect to y.
To find the area of the region, we need to set up the integral bounds. Since the region is bounded by the curves y = 1/x and y = 1/x^2, we need to find the limits of y.
The lower bound is determined by the curve y = 1/x^2, and the upper bound is determined by the curve y = 1/x. The vertical line x = 6 acts as the rightmost boundary.
Therefore, the integral for finding the area of the region is:
A = ∫[lower bound]^[upper bound] [rightmost bound] dy
A = ∫[1/6]^∞ [6] dy
Now, we can proceed with evaluating this integral to find the area of the enclosed region.
Learn more about area from
https://brainly.com/question/25292087
#SPJ11
if an equation defines a function over its implied domain, then the graph of the equation must pass the ____ ______ test
Answers
If an equation defines a function over its implied domain, then the graph of the equation must pass the vertical line test.
The vertical line test is a criterion used to determine if a graph represents a function. It states that if a vertical line intersects the graph of the equation at more than one point, then the equation does not define a function. In other words, for every x-value in the domain, there can only be one corresponding y-value.
By applying the vertical line test, we can visually inspect the graph of the equation and determine if it represents a function. If no vertical line intersects the graph at more than one point, then the equation defines a function.
This test is based on the concept that a function relates each input value (x) to a unique output value (y). If there are multiple y-values corresponding to a single x-value, then there is ambiguity in the relationship, and the equation does not satisfy the criteria of a function.
Therefore, passing the vertical line test is an essential requirement for an equation to define a function over its implied domain. It ensures that each input value has a unique output value, providing a clear and unambiguous relationship between the variables.
To learn more about vertical line test : brainly.com/question/29263148
#SPJ11
the makers of biodegradable straws have an automated machine that is set to fill each box with 100 straws. at various times in the packaging process, we select a random sample of 121 boxes to see whether or not the machine is filling the boxes with an average of 100 straws per box which of the following is a statement of the null hypothesis?
a. The machine fills the boxes with the proper amount of straws. The average is 100 straws. b. The machine is not filling the boxes with the proper amount of straws The average is not 100 straws. c. The machine is not putting enough straws in the boxes. The average is less than 100 straws.
Answers
The correct answer is: a. The machine fills the boxes with the proper amount of straws. The average is 100 straws. In hypothesis testing, the null hypothesis typically represents a statement of no effect or no difference. In this case, it means that the machine is functioning properly and filling the boxes with the expected average of 100 straws per box.
The null hypothesis in this scenario is option a, which states that the machine fills the boxes with the proper amount of straws, and the average is 100 straws per box. This is because the null hypothesis assumes that there is no significant difference between the observed sample mean and the expected population mean of 100 straws per box. To reject this null hypothesis, we would need to find evidence that the machine is not filling the boxes with the proper amount of straws, which would require further investigation and analysis. In conclusion, the null hypothesis can be summarized in three paragraphs as follows: The null hypothesis for the makers of biodegradable straws is that the machine fills the boxes with the proper amount of straws, and the average is 100 straws per box.
This hypothesis assumes that there is no significant difference between the observed sample mean and the expected population mean. To test this hypothesis, a random sample of 121 boxes is selected to determine whether or not the machine is filling the boxes with an average of 100 straws per box. If the observed sample mean is not significantly different from the expected population mean, then the null hypothesis is accepted. However, if the observed sample mean is significantly different from the expected population mean, then the null hypothesis is rejected, and further investigation is required to determine the cause of the difference.
To know more about average visit :-
https://brainly.com/question/28873924
#SPJ11
Which function describes the table of values?

Answers
Answer:
the answer is c I THINK??
Step-by-step explanation:
i know
Geometric number between 7 and 28.
Answers
Answer: 16
Step-by-step explanation:
The geometric number between 7 and 28 is 16. Geometric numbers are the numbers you get by multiplying by a factor. If we multiply by 2 for this common geometric sequence, we get 16:
1 * 2 = 2, 2 * 2 = 4, 4 * 2 = 8, 8 * 2 = 16,16 * 2 = 32, etc.
7 < 16 < 28
Annie was given two pieces of information and must write the equation of a line. She knows the line crosses the y-axis at the point(0,6)and has a slope of7. What is the equation of the line?
A.y=7x+6
B.y=7x−6
C.y=6x+7
D.y=−6x+7
Answers
y - 6 = 7(x-0)
y - 6 = 7x
y = 7x +6
The answer is A
PLEASE HELP ME ITS URGENT MY GRADE NEEDS HELP! THIS IS MULTIPLE CHOICE QUESTION!
Which ordered pairs are solutions to the inequality 2x+3y≥−1?
Select each correct answer.
Responses
(0, −1)
begin ordered pair 5 comma negative 1 end ordered pair
(−2, 1)
begin ordered pair negative 2 comma 1 end ordered pair
(0, 1)
begin ordered pair 0 comma 1 end ordered pair
(−6, 0)
begin ordered pair negative 6 comma 0 end ordered pair
(2, −1)
Answers
Answer:
b, c, d, f
Step-by-step explanation:
Which ordered pairs are solutions to the inequality?
2x+3y≥−1?
a≥b means that A must be equal to or greater than B.
Let's do this the long, but easy way, by plugging it in!
(x,y)
a. (0,-1) -> -3≥-1 -> false
b. (5,-1)-> 7≥-1 -> true
c. (-2,1) -> -1≥-1 -> true
d. (0,1) -> 3≥-1 -> true
e. (-6,0) -> -12≥-1 - > false
f. (2,-1) -> 1≥-1 -> true
Let me know if it is incorrect!
- a friendly 8th grader :)
A chi-square test of independence is a one-tailed test. The reason is that Multiple Choice we are testing whether the frequencies exceed their expected values. we square the deviations, so the test statistic lies at or above zero. hypothesis tests are one-tailed tests when dealing with sample data. the chi-square distribution is positively skewed.
Answers
A chi-square test of independence is indeed a one-tailed test. The reason for this is that we are testing whether the observed frequencies of two categorical variables are significantly different from the expected frequencies.
We square the deviations between the observed and expected frequencies, and since deviations can only be positive, the test statistic always lies at or above zero. Hypothesis tests are one-tailed when dealing with sample data because we have a specific direction for our research question. In the case of a chi-square test of independence, we are interested in whether one variable is dependent on the other variable, so we have a directional hypothesis. Furthermore, the chi-square distribution is positively skewed, meaning that the majority of the distribution is on the right-hand side. This is important to consider when interpreting the results of a chi-square test.
Know more about chi-square test here:
https://brainly.com/question/14082240
#SPJ11
|z-18|-15=-5 , what's the absolute value for Z?
Answers
Answer:
8
Step-by-step explanation:
absolute value of z-18 = z + 18
z + 18
-15
______
z + 3
z + 3 - 3 = -5 - 3
z = -8
|z| = |-8|
z = 8
hope this helped ^^
Find the area of a rectangle with a length of 3 and a width of 3x - 5y + 6
Answers
Answer:
3x−5y=6⇒y=35x−65 . If you have y=mx+c then intercept is c . So intercept is −65 .
the sum of two numbers is 18 their difference is 4
Answers
Answer:
7 and 11
Step-by-step explanation:
c) Given that L
1
={ab,bc,abc} and L
2
={b,bb,b}, find: i) L
1
L
2
ii) L
1
L
2
∗
iii) (L
1
∪L
2
)
+
[15 Marks - 5 marks cach] a) Let G
1
and G
2
be context-free grammars, generating the languages L(G
1
) and L(G
2
). respectively. Show that there is a context-free grammar generating each of the following sets. [ 9 Marks −3 marks each] i) L(G1) ∪L(G2) ii) L(G1)L(G2) iii) L(Gl)
∗
c) Let G be the grammar with V=(a,b,c,S},T=(a,b,c), starting symbol S, and productions S→abSS.S→bcS,S→bbS,S→a,S→cb. Construct a parse or derivation tree for each of the following: [ 8 Marks −2 marks each] i) bcbba ii) bbbebba iii) bcabbbbbcb iv) bbacbbba
Answers
To generate L(G1)*, we can modify the grammar G1 to include an extra production S → ε, where ε represents the empty string.
i) To find L1L2, we concatenate every string from L1 with every string from L2.
L1L2 = {ab + b, ab + bb, ab + b, bc + b, bc + bb, bc + b, abc + b, abc + bb, abc + b}
Therefore, L1L2 = {abb, abbb, abb, bcb, bcb, bcb, abcb, abcb, abcb}.
ii) To find L1L2∗, we concatenate every string from L1 with zero or more strings from L2.
L1L2∗ = {ab, abb, abb, b, bb, b, abcb, abbbb, abbb, bcb, b, bcb, abcb, abcb, abcb, ...}
Note: The ellipsis (...) represents the inclusion of more strings formed by concatenating L1 with different combinations of L2.
iii) To find (L1∪L2)+, we take the union of L1 and L2 and concatenate it one or more times.
(L1∪L2)+ = {ab, bc, abc, b}+ = {ab, bc, abc, b, ab, bc, abc, b, ab, bc, abc, b, ...}
Note: The ellipsis (...) represents the inclusion of more repetitions of the strings in L1∪L2.
a) i) To generate L(G1)∪L(G2), we can create a new grammar with the union of the productions from G1 and G2. Let's denote this new grammar as G3.
G3:
V = V1 ∪ V2 ∪ {S},
T = T1 ∪ T2,
P = P1 ∪ P2 ∪ {S → S1 | S2}
Here, V1, V2, T1, T2, P1, and P2 represent the variables, terminals, and productions of G1 and G2, respectively.
ii) To generate L(G1)L(G2), we can create a new grammar by combining the productions of G1 and G2.
G3:
V = V1 ∪ V2,
T = T1 ∪ T2,
P = P1 ∪ P2 ∪ {S → S1S2}
iii) To generate L(G1)*, we can modify the grammar G1 to include an extra production S → ε, where ε represents the empty string.
b) Parsing trees cannot be provided as the question does not specify the context-free grammar for G1 or G2. Without the grammar rules, it is not possible to construct the parse trees. Please provide the context-free grammar rules for G1 and G2 to generate the parse trees.
Learn more about grammar from below link
https://brainly.com/question/2353198
#SPJ11
Thank You In Advance ;))

Answers
Answer:
17,984,000
Step-by-step explanation:
because it is
Which statement accurately explains whether a reflection over the X-axis and a 180° rotation would map figure ACB onto itself?

Answers
Using transformation rules, it is found that the correct option is:
No, A'C'B' is located at A(-1,1), C'(-3,4) and B'(-5,1).
--------------------
The transformation rule for a reflection over the x-axis is \((x,y) \rightarrow (x,- y)\)The transformation rule for a rotation of 180º is \((x,y) \rightarrow (-x,-y)\)After the reflection over the x-axis: \((x,y) \rightarrow (x, -y)\)Taking the reflection, and rotating: \((x,-y) \rightarrow (-x, -(-y)) = (-x,y)\).Not the same rule, that is, \((x,y) \rightarrow (x,y)\), so it would not map figure onto itself.A(1,1) would be mapped to A(-1,1), for example, thus, the correct option is:No, A'C'B' is located at A(-1,1), C'(-3,4) and B'(-5,1).
A similar problem is given at https://brainly.com/question/10547006
Answer:
No, A'C'B' is located at A(-1,1), C'(-3,4) and B'(-5,1).
Step-by-step explanation:
Just took the test ::)
please help me aaaaaaaaaa

Answers
11023.113 pounds
Mass
5
tonne
11023.1
Pound
Formula
for an approximate result, multiply the mass value by 2205
Without using a calulator, find A and B, A^B - B^A = 1.
Answers
Answer:
A = 1
B = 0
Step-by-step explanation:
Two thousand two hundred frequent business travelers are asked which midwestern city they prefer: Indianapolis, Saint Louis, Chicago, or Milwaukee. 124 liked Indianapolis best, 416 liked Saint Louis, 1225 liked Chicago, and the remainder preferred Milwaukee. Develop a frequency table and a relative frequency table to summarize this information. (Round relative frequency to 3 decimal places.) City Frequency Relative Frequency Indianapolis St. Louis Chicago Milwaukee
Answers
The frequency table will list the number of travelers who liked each city. In this case, 124 travelers liked Indianapolis best, 416 liked St. Louis, 1225 liked Chicago, and the remaining number preferred Milwaukee.
The frequency table will present the preferences of the frequent business travelers while the relative frequency table will express these frequencies as a proportion of the total number of travelers. It will list the four cities (Indianapolis, St. Louis, Chicago, and Milwaukee) and their corresponding frequencies, which represent the number of travelers who preferred each city. According to information provided, 124 travelers liked Indianapolis, 416 liked St. Louis, 1225 liked Chicago, and the remaining number preferred Milwaukee.
The relative frequency table will express the frequencies as proportions relative to the total number of travelers. To calculate the relative frequency, the frequency of each city will be divided by the total number of travelers, which is 2200 in this case.
The resulting proportions will be rounded to three decimal places. The relative frequencies will indicate the proportion of travelers who preferred each city relative to the total number of respondents.
To learn more about frequency table click here : brainly.com/question/29084532
#SPJ11
there are three coins in a box. one is a two-headed coin, another is a fair coin, and the third is a biased coin that comes up heads 80% of the time. (a) when one of these coins were selected at random and flipped, what is the probability that it shows heads? (1 po
Answers
The probability of the selected coin showing heads is 0.77, or 77%.
Probability is the measure of the likelihood of an event occurring. In this scenario, we have three coins in a box, each with different properties.
To calculate the probability of an event occurring, we need to divide the number of favorable outcomes by the total number of possible outcomes. In this case, there are three possible coins we could select, each with a different probability of showing heads.
Now, we need to determine the total number of possible outcomes, which is simply the number of coins we have, which is three.
Next, we need to determine the number of favorable outcomes. For Coin 1, the probability of showing heads is 1 (since it has two heads). For Coin 2, the probability of showing heads is 0.5 (since it is a fair coin with equal probability of heads and tails). For Coin 3, the probability of showing heads is 0.8.
To calculate the probability of showing heads when we randomly select one of these coins, we need to weigh the probabilities of each coin being selected with their corresponding probabilities of showing heads.
Let's say that the probability of selecting each coin is equal (since we have no information to suggest otherwise). Then, the probability of selecting Coin 1 is 1/3, the probability of selecting Coin 2 is 1/3, and the probability of selecting Coin 3 is 1/3.
To calculate the overall probability of showing heads, we can use the following formula:
P(heads) = (P(Coin 1) * P(heads on Coin 1)) + (P(Coin 2) * P(heads on Coin 2)) + (P(Coin 3) * P(heads on Coin 3))
= (1/3 * 1) + (1/3 * 0.5) + (1/3 * 0.8)
= 0.77
To know more about probability here.
https://brainly.com/question/11234923
#SPJ4
Use the extended Euclidean algorithm to express
gcd(144, 89) as a linear combination of 144 and 89
Answers
The greatest common divisor (gcd) of 144 and 89 can be expressed as a linear combination of 144 and 89 as follows: gcd(144, 89) = 1 = (-21) * 144 + 34 * 89.
To express the gcd (144, 89) as a linear combination of 144 and 89, we can use the extended Euclidean algorithm. This algorithm finds the gcd of two numbers and also provides coefficients that represent the linear combination.
We start with the given numbers: a = 144 and b = 89.
Apply the Euclidean algorithm to find the gcd:
Divide 144 by 89: 144 = 1 * 89 + 55
Divide 89 by 55: 89 = 1 * 55 + 34
Divide 55 by 34: 55 = 1 * 34 + 21
Divide 34 by 21: 34 = 1 * 21 + 13
Divide 21 by 13: 21 = 1 * 13 + 8
Divide 13 by 8: 13 = 1 * 8 + 5
Divide 8 by 5: 8 = 1 * 5 + 3
Divide 5 by 3: 5 = 1 * 3 + 2
Divide 3 by 2: 3 = 1 * 2 + 1
Divide 2 by 1: 2 = 2 * 1 + 0
The last non-zero remainder obtained is 1, which means the gcd is 1.
Now, we work backwards through the algorithm to find the coefficients:
From 3 = 1 * 2 + 1, we can express 1 as a linear combination of 2 and 3: 1 = 3 - 1 * 2
Substitute 2 = 5 - 1 * 3 from the previous step: 1 = 3 - 1 * (5 - 1 * 3) = 2 * 3 - 1 * 5
Continue substituting until we reach the original numbers:
1 = 2 * 3 - 1 * 5 = 2 * (5 - 1 * 3) - 1 * 5 = 2 * 5 - 3 * 5 = 2 * 5 - 3 * (8 - 1 * 5)
Repeat until we get the desired linear combination:
1 = 2 * 5 - 3 * (8 - 1 * 5) = 2 * 5 - 3 * 8 + 3 * 5 = (-3) * 8 + 5 * 5 - 3 * 8 = 5 * 5 - 6 * 8
Substitute 8 = 13 - 1 * 5: 1 = 5 * 5 - 6 * (13 - 1 * 5) = 11 * 5 - 6 * 13
Repeat the process until we reach the original numbers:
1 = 11 * 5 - 6 * 13 = 11 * (13 - 1 * 8) - 6 * 13 = 11 * 13 - 11 * 8 - 6 * 13 = (-17) * 8 + 11 * 13
Substitute 13 = 21
Learn more about linear here: brainly.com/question/31510530
#SPJ11