simplify the algebraic expression
3/4(4x-8y)
Answers
Answer:
3x-6y
Step-by-step explanation:
3/4(4x-8y)
3/4×(4x-8y)
3/4×4(x-2y)
3×1(x-2y)
3x-6y
Related Questions
A delicatessen is open 24 hours a day every day of the week. If, on the average, 20 orders are received by fax every two hours throughout the day, find the a. probability that a faxed order will arrive within the next 9 minutes b. probability that the time between two faxed orders will be between 3 and 6 minutes c. probability that 12 or more minutes will elapse between faxed orders
Answers
The answers are (a) 1.5 orders (b) 0.5 (c)-1
a. Probability that a faxed order will arrive within the next 9 minutes:
Since there are 24 hours in a day, and we receive an average of 20 orders every two hours, this means we receive an average of 10 orders per hour. We can assume that orders arrive uniformly throughout the hour. To find the probability that a faxed order will arrive within the next 9 minutes, we can convert the time to hours. 9 minutes is \(\frac{9}{60} = 0.15\) hours. The probability of an order arriving within the next 9 minutes is equal to the average rate of orders per hour multiplied by the time interval:
Probability = (10 orders/hour) * (0.15 hours) = 1.5 orders.
b. Probability that the time between two faxed orders will be between 3 and 6 minutes. Again, we need to convert the time interval to hours. 3 minutes is \(\frac{3}{60}=0.05\) hours, and 6 minutes is \(\frac{6}{60} = 0.1\).
The probability of the time between two orders being between 3 and 6 minutes can be calculated as the difference between the probabilities of an order arriving within the next 3 minutes and an order arriving within the next 6 minutes:
Probability = (10 orders/hour) (0.1 hours) - (10 orders/hour) (0.05 hours)
= 1 - 0.5
= 0.5.
c. Probability that 12 or more minutes will elapse between faxed orders:
Similar to the previous calculations, we convert the time to hours. 12 minutes is \(\frac{12}{60} = 0.2\) hours.
The probability that 12 or more minutes will elapse between faxed orders can be calculated as the probability of no orders arriving within the next 12 minutes:
Probability = 1 - (10 orders/hour) (0.2 hours)
= 1 - 2
= -1.
To know more about "Probability" refer here:
https://brainly.com/question/30034780#
#SPJ11
determine µx and σx \from the given parameters of the population and sample size.
µ = 84; σ = 18; n = 36
Answers
The mean (µx) and standard deviation (σx) of a sample can be determined using the given parameters of the population mean (µ), population standard deviation (σ), and sample size (n).
In this case, since we are given the population mean (µ = 84), the mean of the sample (µx) will be the same as the population mean.
µx = 84 (same as the population mean)
σx = 18 / √36 = 3 (the population standard deviation divided by the square root of the sample size)
To determine the standard deviation of the sample (σx), we divide the population standard deviation (σ = 18) by the square root of the sample size (n = 36). This is based on the principle that the standard deviation of the sample is expected to be smaller than the standard deviation of the population, and it decreases as the sample size increases.
Therefore, in this scenario, the mean of the sample (µx) is 84, and the standard deviation of the sample (σx) is 3. These values represent the central tendency and variability of the sample data.
Learn more about sample size here:
brainly.com/question/30100088
#SPJ11
10. If c and d are whole numbers and neither c nor d is 0, what must be true about c and d if the coefficients of c(2x + 3x + 1) ÷d are whole numbers?
Answers
The true statement about the c and d is that d is a factor or c
What is coefficient?A coefficient is a multiplicative factor in some term of a polynomial, a series, or an expression; it is usually a number, but may be any expression. When the coefficients are themselves variables, they may also be called parameters.
For example, in the expression 4x²+3x+1, the coefficient of x² is 4 and the coefficient of 3x is 3.
Since c and d are whole numbers and they are not zero. This means that c and d are factors .
for c(2x + 3x + 1) ÷d to have a coefficient that is a whole number, d must be a factor or divisor of c. for example
10x/2 =5x, the coefficient of x is a whole number because 2 is a factor of 10
learn more about coefficient from
https://brainly.com/question/1038771
#SPJ1
A builder is using the drawing below to build a house. If the owner decides to increase the living room dimensions by 20%, what is the new length and width of the living room floor?a. 14.4 feet x 9.6 feetb. 144 feet x 96 feetc. 13.2 feet x 8.2 feetd. 10 feet x 8 feet
Answers
Percentage increment means the part of original value is added to the value. The new length of the living room is 14.4 feet long and new width of the living room is 1.6 feet long. The option A is the correct option.
The length of the living room is 12 feet.
The width of the living room is 8 feet.
The owner increases the 20 percent of length and 20% width.
Suppose new length is feet long. As the owner increases the 20 percent of length. Thus the new length will be sum of original length and the 20 percent of it. Hence,
l=12+12/100*12
l=14.4
Thus the new length of the living room is 14.4 feet long.
Suppose new width is feet long. As the owner increases the 20 percent of width. Thus the new width will be sum of original width and the 20 percent of it. Hence,
w=8+20/100*8
w=9.6
the new width of the living room is 1.6 feet long.
Hence the new length of the living room is 14.4 feet long and new width of the living room is 1.6 feet long.
Learn more about the percentage here;https://brainly.com/question/24877689
#SPJ4

factor completely 81x^2-4
Answers
Answer:
(9x-2)(9x+2) is the correct answer

Consider the equivalence relation from exercise 11.3. Find [x^2+3x+1]; give this in description notations without any direct reference to R.
Answers
The equivalence class \([x^2 + 3x + 1]\) consists of all polynomials p(x).
How to find the equivalence class [x^2 + 3x + 1] using description notation without directly referencing R?To find the equivalence class \([x^2 + 3x + 1]\) using description notation without directly referencing R, we need to describe the set of all elements that are related to \(x^2 + 3x + 1\) under the given equivalence relation.
The equivalence relation from exercise 11.3 states that two polynomials are equivalent if their difference is divisible by x + 2.
Therefore, the equivalence class \([x^2 + 3x + 1]\)can be described as follows:
\([x^2 + 3x + 1] = {p(x) | p(x) - (x^2 + 3x + 1)\) is divisible by (x + 2)}
In other words, the equivalence class \([x^2 + 3x + 1]\) consists of all polynomials p(x) such that the difference between p(x) and \((x^2 + 3x + 1)\) is divisible by (x + 2).
Learn more about equivalence relation
brainly.com/question/30956755
#SPJ11
Make Sense and Persevere Gabriela is selling
friendship bracelets for a school fundraiser.
After the first day, she has 234 bracelets
left. After the second day, she has 222 left.
Assuming the sales pattern continues and
it is an arithmetic sequence, how many
bracelets will Gabriela have left to sell after
the fifth day?
Answers
Answer:
Given that 234 tickets remain after the first day, then a 1 = 234 a_1=234 a1=234. So, Grabriela will have 186 bracelets \text{\color{#c34632}{186 bracelets}} 186 bracelets left to sell after the fifth day.
Is a rational number always also an irrational number?
Answers
Answer:
No, irrational numbers are neverending, many rational numbers can be terminating decimals.
Work out the value of 5² - 19 x 24
Answers
Answer:
5² - 19 * 24
= 25 - 456
= -431
Answer:
-431
Step-by-step explanation:
25-19x24
25-456
-431
The ellipse with x-intercepts at (4, 0) and (-4, 0), y-intercepts at (0, 9) and (0, -9), and center at (0, 0).
Answers
The equation of an ellipse with x-intercepts at (4, 0) and (-4, 0), y-intercepts at (0, 9) and (0, -9), and center at (0, 0) is \($\frac{x^2}{16}+\frac{y^2}{81}=1$$\).
As per the given data the ellipse with x-intercepts at (4, 0) and (-4, 0), y-intercepts at (0, 9) and (0, -9), and center at (0, 0).
If the ellipse has its x-intercepts at points (4, 0) and (-4, 0) and y-intercepts at points (0, 9) and (0, -9), then it's symmetric across the y- axis and the x-axis.
The equation of an ellipse where the major axis 2a is greater than the minor 2b.
When 2b > 2a , then the equation becomes \($\frac{(y-h)^{2} }{b^{2} } + \frac{ (x-k)^{2} }{a^{2} } =1\)
Moreover h = 0 and k = 0 because the center is on the origin, so the equation becomes:
\($\frac{x^2}{a^2}+\frac{y^2}{b^2}=1\)
Moreover,
a = 4
b = 9
The equation of the such ellipse is
\($\frac{x^2}{a^2}+\frac{y^2}{b^2}=1\)
Hence, the equation of the ellipse is
\($\frac{x^2}{4^2}+\frac{y^2}{9^2}=1\)
\($\frac{x^2}{16}+\frac{y^2}{81}=1$$\)
Therefore the equation of an ellipse is \($\frac{x^2}{16}+\frac{y^2}{81}=1$$\).
For more questions on ellipse
https://brainly.com/question/14532476
#SPJ4
Find the equation of the ellipse with the following properties. The ellipse with x-intercepts at (4, 0) and (-4, 0), y-intercepts at (0, 9) and (0, -9), and center at (0, 0).
why do i like math .
Answers
Answer:
:)
Step-by-step explanation:
Mathematics is fun because there is less to read and understand the theory rather more to solve a problem and finding solution. Most of the people like mathematics because its tricky like magic trick and fun like playing your favorite sport or like playing a video game.
an unbiased coin is tossed four times. what is the probability that coin lands heads up at least once? (round your answer to three decimal places.)
Answers
The probability of getting at least one head is 15/16.
What is probability?
The ratio of positive outcomes to all possible outcomes of an event is known as the probability.
Formula for probability = favourable outcomes/ total outcomes
Main body:
if 4 coins are tossed , total no. of outcomes = 2⁴ = 16
In a toss there are 2 outcomes T or H
so, Probability of getting Head = 1/2
The probability of getting at least 1 head = 1- probability of getting no heads
⇒1 - Probability of getting tail in 4 tosses
⇒ 1 - (1/2)⁴
⇒ 1 - 1/16
⇒ 15/16
So the probability of getting at least one head is 15/16.
to learn more about probability click on the link below.
https://brainly.com/question/24756209
#SPJ4
The shape is composed of three squares and two semicircles. Select all the expressions that correctly calculate the perimeter of the shape.
Answers
The expression that correctly calculates the perimeter of the shape is given as follows:
P = 2(6s + πr).
In which:
s is the side length of the square.r is the radius of the semicircle.How to obtain the perimeter of the square?The perimeter of a square of side length s is given as follows:
P = 4s.
Hence, for three squares, the perimeter is given as follows:
P = 3 x 4s
P = 12s.
How to obtain the perimeter of a semi-circle?The perimeter, which is the circumference of a semicircle of radius r, is given by the equation presented as follows:
C = πr.
Hence the perimeter of two semicircles is given as follows:
C = 2πr.
How to obtain the perimeter of the shape?The perimeter of the entire shape is given by the sum of the perimeter of each shape, hence:
P = 12s + 2πr.
P = 2(6s + πr).
More can be learned about the perimeter of a shape at https://brainly.com/question/24571594
#SPJ1
Suppose that you are conducting a survey on how many pets each employee has in his or her household. The mean number of pets is 4 per household, and the standard deviation is 2. Rob only owns cats, and he has 10 of them. Which of the following statements is true? A. Rob's number of pets is 3 standard deviations to the left of the mean. B. Rob's number of pets is 3 standard deviations to the right of the mean. C. Rob's number of pets is 6 standard deviations to the left of the mean. D. Rob's number of pets is 6 standard deviations to the right of the mean.
Answers
Option B is correct, Rob's number of pets is 3 standard deviations to the right of the mean.
We need to calculate the number of standard deviations away from the mean Rob's number of pets is.
Given:
Mean (μ) = 4
Standard Deviation (σ) = 2
Number of pets owned by Rob = 10
To calculate the number of standard deviations (z-score) away from the mean, we use the formula:
z = (x - μ) / σ
where x is the value we want to measure.
For Rob's number of pets:
z = (10 - 4) / 2
z = 6 / 2
z = 3
Therefore, Rob's number of pets is 3 standard deviations to the right of the mean.
To learn more on Statistics click:
https://brainly.com/question/30218856
#SPJ4
I need help I don't understand at all.

Answers
1/4x - 2 = -6 + 5/12x
Step 1: Subtract 5/12x from both sides.
So now the problem is: -1/6x - 2 = -6
Step 2: Add 2 to both sides
So now the problem is -1/6x = -4
Step 3: Multiply -6 to both sides
Now you have x alone and 24
Answer: x = 24
please mark this answer as brainlist
(DESPERATE PLEASE HURRY)
question down below
please show the work

Answers
Answer:
-6=-10+x
x= -6+10
x= 4
x=
Step-by-step explanation:
-6 =-10+x
x =-6 + 10
x= 4
the study would use a . the study would use simple random sampling because it would be easy to randomly select of . b. the study would use a . the study would use cluster sampling because the of fall into naturally occurring subgroups. c. the study would use a . the study would use stratified sampling because it would be important to have members from each segment of the population. d. the study is a , because the population is for it to be practical to record all of the responses.
Answers
The study would use a simple random sampling because it would be easy to randomly select. The study would use cluster sampling because the of fall into naturally occurring subgroups. The study would use stratified sampling because it would be important to have members from each segment of the population.
The study is a sample survey, because the population is for it to be practical to record all of the responses.
a. The study would use a simple random sampling because it would be easy to randomly select members of the population. Simple random sampling is a type of probability sampling that is used when the population is homogenous and every member has an equal chance of being selected for the sample.
b. The study would use cluster sampling because the members of the population fall into naturally occurring subgroups. Cluster sampling is a type of probability sampling that is used when the population is heterogeneous and can be divided into naturally occurring subgroups.
c. The study would use stratified sampling because it would be important to have members from each segment of the population. Stratified sampling is a type of probability sampling that is used when the population is heterogeneous and can be divided into segments or strata based on certain characteristics.
d. The study is a sample survey, because the population is too large for it to be practical to record all of the responses. Sample survey is a type of survey that collects data from a sample of the population, rather than the entire population. This is often done when the population is too large or when it is not practical to survey the entire population.
To know more about sampling refer here:
https://brainly.com/question/30759604
#SPJ11
Determine whether each ordered pair is a solution of y = x+3. (2,5) (4,6) (5,8) (3,7)
Answers
Answer:
(2,5) and (5,8)
Step-by-step explanation:
you can just plug in the numbers to get your answer and if two numbers aren't the same then its not a solution
example: (2,5)
5 = 2 + 3
5 = 5
5 does equal 5 making it a solution because it makes sense right?
example: (4,6)
6 = 4 + 3
6 = 7
this isn't a solution because six doesn't equal 7
Answer:
[see below]
Step-by-step explanation:
\(y=x+3\)
(2,5):\(5=2+3\\\\\boxed{5=5}\)
The ordered pair is a solution.
(4,6):\(6=4+3\\\\\boxed{6\neq7}\)The ordered pair is not a solution.
(5,8):\(8=5+3\\\\\boxed{8=8}\)The ordered pair is a solution.
(3,7):\(7=3+3\\\\\boxed{7\neq 6}\)
The ordered pair is not a solution.
Hope this helps.
Consider the figure below. Angle b and angle f are corresponding angles.
Notice how angle b and angle f have distinct vertex points and lie on the same side of the transversal. However, angle f is in the interior region of lines l1 and l2, and angle b is in the exterior region of lines l1 and l2
Draw a box around another pair of corresponding angles in the figure and name them below.

Answers
Answer: Angles a and e
Step-by-step explanation:
Angle a and angle e are also corresponding angles! They both have distinct vertex points and lie on the same side of the transversal.
Enter a digit into the missing boxes

Answers
Answer:5
Step-by-step explanation:
because i said so
Answer:
4, 5, 4,
Step-by-step explanation:
Help with math please.I need proof of how you got the answer
Answers
The United States Postal Service (USPS) now offers a service that allows customers to ship packages at a flat rate based on box size (small, medium, large) rather than by weight. The USPS records the weight of all small packages shipped using this new service and finds a normally distributed variable with a mean of 6.9 pounds and a standard deviation of 10 ounces (.63 pounds).
Required:
What is the probability that a package shipped in a small size box will weigh more than 6 pounds?
Answers
The probability that a package shipped in a small size box will weigh more than 6 pounds is 0.9236, or 92.36%.
To find the probability that a package shipped in a small size box will weigh more than 6 pounds, we need to convert the weight of 6 pounds to the same unit as the mean and standard deviation given in the problem, which is pounds.
Since 1 pound is equal to 16 ounces, 6 pounds can be expressed as 6 * 16 = 96 ounces. Converting 96 ounces to pounds gives us 96 / 16 = 6 pounds.
Now that we have the weight in pounds, we can use the normal distribution to calculate the probability.
The mean weight of small packages is given as 6.9 pounds, and the standard deviation is 10 ounces, which is equivalent to 0.63 pounds. To find the probability that a package weighs more than 6 pounds, we need to calculate the area under the curve to the right of 6 pounds.
To do this, we can use a standard normal distribution table or a statistical calculator. Using the standard normal distribution table, we can find the corresponding z-score for 6 pounds by subtracting the mean from 6 pounds and dividing by the standard deviation:
z = (6 - 6.9) / 0.63 = -1.429
Looking up the z-score of -1.429 in the standard normal distribution table, we find that the corresponding area to the right of -1.429 is 0.9236.
Therefore, the probability that a package shipped in a small size box will weigh more than 6 pounds is 0.9236, or 92.36%.
For more question on probability visit:
https://brainly.com/question/25839839
#SPJ8
What type of lines intersect and are coplanar? select all that apply. A. Parallel b. Perpendicular c. Segments d. Transversal.
Answers
The correct option are; b. Perpendicular and d. Transversal; are the lines that intersects and are coplaner lines.
Define the term coplaner lines?If two or so more points are on the same line, they are considered to be collinear in geometry. As a result, the set of points all lie on an one straight line are the collinear points.Perpendicular lines:
A pair of non-vertical lines in almost the same plane are shown to be perpendicular if they cross at a right angle. The axes of such coordinate plane are horizontal and vertical lines, which are perpendicular to one another.Transversal:
A line which crosses 2 or more lines is referred to as a transversal. A street crossing train tracks would be a practical illustration of a transversal line.To know more about the coplaner lines, here
https://brainly.com/question/3417564
#SPJ4
Mike compared the y-intercept of the graph of the function
f(x) = 5x + 12 to the y-intercept of the graph of the ilnear function that
includes the points from the table below. What is the difference when the y-
intercept of f (x) is subtracted from the y-intercept of g (x)?
Х
1 3 5 6
g(x) 10 14 18 20
Answers
Answer:
-4Step-by-step explanation:
Given function
f(x) = 5x + 12From the table we get the function g(x), use pairs (1, 10) and (3, 14)
The slope:
m = (14 - 10)/(3 - 1) = 4/2 = 2The y-intercept:
10 = 2(1) + bb = 10 - 2b = 8The function g(x) is found as:
g(x) = 2x + 8The y- intercept of f (x) is subtracted from the y-intercept of g (x):
8 - 12 = -4Answer:
(the answer is • -4)
...
The shape of the distribution of sample means tends to be normal if: a. The population from which the samples are obtained are normal b. The sample size is n-30 or more
c. Both A&B d. None of the above
Answers
The central limit theorem (CLT) states that as sample size increases, "The correct answer is C - both A and B". The shape of the distribution of sample means tends to be normal if the population from which the samples are obtained is normal and the sample size is n-30 or more.
the distribution of sample means will approach a normal distribution regardless of the shape of the population distribution, provided that the sample size is large enough. Therefore, the answer to this question involves both the conditions of the CLT and the nature of the population distribution.
Condition A states that the population from which the samples are obtained must be normal. This means that the population distribution is symmetrical and bell-shaped, with most of the observations clustered around the mean, and the tails of the distribution taper off towards plus and minus infinity. If the population is not normal, then the sample mean distribution may not be normal, regardless of sample size.
Condition B states that the sample size should be n-30 or more. The rule of thumb is that if the sample size is greater than or equal to 30, the distribution of sample means will be approximately normal, regardless of the population distribution. This is because as sample size increases, the sample means will tend to cluster around the population mean, and the standard error of the mean will decrease. This, in turn, will result in a narrower and more symmetrical distribution of sample means.
Therefore, both conditions A and B must be satisfied for the distribution of sample means to be normal. If either of these conditions is not met, the distribution of sample means may not be normal.
To learn more about sample size here:
brainly.com/question/25894237#
#SPJ11
worth 10 ponts plus making brainliest!!!

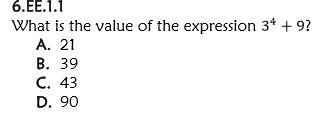
Answers
Answer:
1. 11
2. D: 90
Step-by-step explanation:
Hope I helped and can I have brainliest please? :)
Steps:
1. if you put this in a calculator this is how you would get the answer:
(2*3)^(2) -5^(2) and you get 11.
2. same with this one: 3^(4)+9
so 3x3x3x3+9=90
Answer:
1. 7
2.A
Step-by-step explanation:
What are 3 ways to solve inequalities?
Answers
We can solve the Inequalities by Isolating the variables that are present in the given Inequality.
What are Inequalities:In mathematics, an inequality is a connection between two values or mathematical equations that results in an unequal comparison.
The signs that we use in Inequalities are less than( < ), less than or equal to ( ≤ ), greater than ( > ), greater than or equal to ( ≥ ), and not equal to (≠) sign.
Solving Inequalities:Lets us consider we have inequality 3x + 2 + x ≥ 10
We can solve the above inequality as given below
Here we will solve the inequality by Isolating the variable
Step - 1
Add x term and constant terms
=> 4x + 2 ≥ 10 [ here 3x + x = 4x ]
Step - 2
Bring out x terms at one side, and constant terms at another side by doing required operations like adding
=> 4x + 2 ≥ 10 [ here we will subtract 2 from both sides ]
=> 4x + 2 - 2 ≥ 10 - 2
=> 4x ≥ 8
Step - 3
Now isolate the variable to get the solution
=> 4x/4 ≥ 8/4 [ here divided by 4 ]
=> x ≥ 2
Therefore, the required solution is x ≥ 2
Therefore,
We can solve the Inequalities by Isolating the variables that are present in the given Inequality.
Learn more about Inequalities at
https://brainly.com/question/28823603
#SPJ4
Solve?? Wat is it plss?

Answers
-6,604
———-
1,927
For a fraction to a be Rational Number it has to be made up of _____?1. Integers2. Rational numbers3. Letters4. Irrational numbers
Answers
The definition of a rational number is: A rational number is a number that is of the form p/q where p and q are integers and q is not equal to 0.
Examples of rational numbers are:
\(\frac{1}{2},\frac{2}{3},\frac{7}{8},\text{ etc}\)From the above definition
For a fraction to a be Rational Number it has to be made up of integers
The answer is option 1
2. What is the average salary offered to a Stony Brook college graduate? To study this question you and a friend interview N students that graduated last year, and ask them what they earn. Student i's response was recorded as Yi. You are interested in the average, My. You assumed that the sample of Y's is iid. First you calculate the following estimate of uy: W1 N 1 N i=1 ΣΥ. . You and your friend each collected half the data. Thus you collected Y1, ..., YN/2 and your friend collected Yn/2+1, ... , Yn. Unfortunately, it turns out that your friend collected the data at a wild alumnae party, and you suspect that these data may not be as precise as your data. So whereas the variance of your data is, var(Y;) = 0%, i = 1, ...,N/2. then your friends data have the variance, var(Y) = oʻ(1 + 3c), i=N/2+1, ...,N, for some constant c> 0. (d) Your friend is sorry that half the data are not as precise as they could have been, and suggest that you discard the noise data, and simply use hr Na Ex? Y; as your estimator for my. Which estimator is most efficient (has the smallest variance) în or îz? Does your answer depend on c? = N.Σ. (Υ – μ.) - = (e) Suppose now that c = 0 such that var(Y;) = o2 for i = 1, ...,N. You have N = 300 observation and calculate s2 = 20,000,000 and î1 = $48,000. Before collecting the data, your friend argues mean salary, my, is s $50,000, using a 1% significance level. Write down the confidence interval at 1% significance level and decide whether you will accept your friend's
Answers
The more precise estimator ẏ₁ is the most efficient in estimating the average salary. With given values, the confidence interval is calculated to determine whether to accept the claim of a $50,000 mean salary.
In this scenario, we have two estimators for the average salary: ẏ₁, which uses precise data, and ẏ₂, which includes less precise data. The efficiency of the estimators depends on the variance of the data. If we compare the variances, Var(ẏ₁) = 0% and Var(ẏ₂) = o²(1 + 3c). Since Var(ẏ₁) is zero, it implies that ẏ₁ is the most efficient estimator. The answer does not depend on the value of c.
In the second part, with c = 0, we have Var(Y) = o². Given N = 300, s² = 20,000,000, and ẏ₁ = $48,000, we can use these values to construct a confidence interval. Using a 1% significance level, the critical value is 2.57 (from the standard normal distribution). The confidence interval is given by ẏ₁ ± 2.57 * sqrt(s²/N), which results in $48,000 ± 2.57 * sqrt(20,000,000/300). If this interval contains $50,000, we would accept your friend's claim; otherwise, we would reject it.
To learn more about average click here
brainly.com/question/29550341
#SPJ11