Snorkel's age 15 years ago was 22. How old is Snorkel today?
Answers
Related Questions
When the sample of participants is reflective of the characteristics of the population, it is said to be?
Answers
It is claimed that the sample of participants is generalizable since it reflects the characteristics of the population.
What is Generalizability? Simply said, generalizability is a measurement of the applicability of a study's findings to a larger population or set of circumstances. It is considered that a study has strong generalizability if its findings may be applied broadly to a wide range of individuals or circumstances. Researchers use generalizability in a scholarly setting. It can be characterized as the extrapolation of findings and recommendations from a study done on a sample population to the entire population.To learn more about generalizable, refer to:
https://brainly.com/question/28237221
#SPJ4
How do you do this. Please someone explain?

Answers
Answer: y = (1/2)x-2
This is the same as y = 0.5x-2
Slope = 1/2 = 0.5
Y intercept = -2
========================================================
Work Shown:
Compare the equation to y = mx+b to find that m = -2 is the slope.
Think of -2 as -2/1. Flip the fraction to get -1/2. Then flip to positive getting 1/2.
The original slope is -2. The perpendicular slope is 1/2 = 0.5
We'll use this perpendicular slope alone with (x,y) = (-4,-4) to get the following for b
y = mx+b
-4 = 0.5*(-4) + b ... plug in the m,x, and y values mentioned above
-4 = -2 + b
-4+2 = b ... adding 2 to both sides
-2 = b
b = -2
Since m = 0.5 and b = -2, we go from y = mx+b to y = 0.5x-2
This is the same as y = (1/2)x-2 since 1/2 = 0.5
Gio sells gelato and collected sales data for the past few days. gio wants to use the naive method to forecast. calculate the naive forecast for day 6. day 1 2 3 4 5 sales 90 97 92 95 93
Answers
The naive forecast for day 6 is 94.
What is a naive forecast?A method of estimation that uses the last period's actuals as the forecast for a current period without making any adjustments or attempting to identify the causes. It is solely used to compare forecasts using more advanced (better) approaches.The calculation of an angle histogram using the naive assumption that the accumulation of points corresponding to the directions of interest will produce peaks that may be seen.There are three fundamental categories: causal models, time series analysis and projection, and qualitative approaches.The main four quantitative budget forecasting techniques—straight line, moving average, simple linear regression, and multiple linear regression—are covered in this article despite the fact that there are many other regularly used quantitative budget forecasting tools.
The naive forecast for the nth period is calculated as follows.
Forecast period Yn=Yn−1
Period Sales Naive Forecasts
1 90 -
2 97 90
3 92 97
4 90 92
5 94 90
6 94
Hence, the naive forecast for day 6 is 94.
To learn more about the naive forecast, refer to:
https://brainly.com/question/14783345
#SPJ4
Factorise
x² - 9x + 20
Answers
Answer:
(x - 5)(x - 4)
Step-by-step explanation:
\( {x}^{2} - 9x + 20 \\ \\ = {x}^{2} - 5x - 4x + 20 \\ \\ = x(x - 5) - 4(x - 5) \\ \\ = (x - 5)(x - 4)\)
The model represents an equation. What value of x makes the equation true?
Please write an explanation on why. I don’t just want the answer I actually want to learn and understand it, thank you! :>

Answers
Answer:
A) 29/8
Step-by-step explanation:
On the left side of the equals sign, we have five x's and nine -1's.
On the right side of the equals sign, we have three -x's and twenty 1's.
Both sides are equal, so:
5(x) + 9(-1) = 3(-x) + 20(1)
5x − 9 = -3x + 20
Add 3x to both sides.
8x − 9 = 20
Add 9 to both sides.
8x = 29
Divide both sides by 8.
x = 29/8
The cost of a pair of shoes increase by 20% to 420.1) What percentage of the old price is the new price?2) calculate the original price
Answers
new price is 120% of old price
old price is 420.1 • 5÷6
420.1 • 5 = 2100.5
2100.5 ÷ 6 = 350.083
original price was $350.08
Solve for x and y simultaneously
Pls help me

Answers
I don't think its possible to do this... you have to have 2 equations
In a bakery, the ratio of fruit scones to cheese scones is 3:4.
a) Given that there are 24 cheese scones, how many fruit scones are there?
b)
If 6 fruit scones were sold, what would be the new ratio of fruit scones to cheese scones?
Answers
Answer:
a) 18 and b)1:2
Step-by-step explanation:
for a i divided 24 by 4 (24:4) and got 6 the i multiplied 3 by 6 and got 18. also you could do a proportion and fruit scones would be x so you have to calculate x. if you don't know how to do proportions you can ask me i can explain.
for b since i got the count was 18:24. i took away those six from 18 and got with the ratio 12:24. i divided both sides by twelve and got 1:2
Answer:
a) 18 fruit scones
b) 6:8
Step-by-step explanation:
a) The ratio is 3:4 given that there 3 fruit scones to 4 cheese scones so if there are 24 cheese scones, 24/4=6, 3*6=18 so there 18 fruit scones.
b) The ratio is 3:4 given that there 3 fruit scones to 4 cheese scones so if there are 6 fruit scones, 6/3=2, 2*4=8 so there are 8 cheese scones. The new ratio would be 6:8
Help me please for 50 points
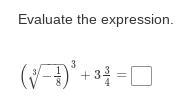
Answers
\(\left(\sqrt[3]{- \dfrac 18} \right)^3+3\dfrac3 4\\\\\\=\left[\left(-\dfrac 18 \right)^{\tfrac 13}\right]^3+ \dfrac{12+3}4\\\\\\=\left(-\dfrac 18 \right)^{\tfrac 33\right)+ \dfrac{15}4\\\\\\=\dfrac{15}{4}- \dfrac 18\\\\\\\\=\dfrac{30-1}{8}\\\\\\=\dfrac{29}8\\\\\\=3\dfrac 58 \\\\\\= 3.625\)
Answer:
29/8
Step-by-step explanation:
what percentage of persons who lose weight are able to maintain it for more than a year?
Answers
Answer: 20%
Step-by-step explanation:
reflections practice
Answers
Answer:
what question do you want to answer?
Step-by-step explanation:
?
You start at (6,7) and move 5 units to the right and 4 units up what point will u end on
Answers
Answer:
(11,11)
Step-by-step explanation:
Moving 5 units to the right means add 5 to x
Moving 4 units up means add 4 to y
(6+5, 7+4)
(11,11)
given two hexadecimal numbers find if they can be consecutive in gray code
Answers
To determine if two hexadecimal numbers can be consecutive in gray code, you need to convert them to binary and then compare their corresponding bits.
Gray code is a binary numeral system where two consecutive numbers differ by only one bit. Therefore, if two hexadecimal numbers can be consecutive in gray code, their binary representations must differ by only one bit as well. To convert a hexadecimal number to binary, simply convert each hexadecimal digit to its corresponding 4-bit binary representation. For example, the hexadecimal number 3A would be converted to 0011 1010 in binary.
Here is a step-by-step guide to determine if two hexadecimal numbers can be consecutive in gray code:
1. Convert the first hexadecimal number to binary. For example, if the first hexadecimal number is 3A, convert it to 0011 1010 in binary.
2. Convert the second hexadecimal number to binary using the same method as step 1.
3. Compare the corresponding bits of the two binary numbers. If there is only one bit that differs between the two binary numbers, then the original hexadecimal numbers can be consecutive in gray code.
4. If there is more than one bit that differs between the two binary numbers, then the original hexadecimal numbers cannot be consecutive in gray code.
To know more about hexadecimal numbers visit :-
https://brainly.com/question/13605427
#SPJ11
Helpppppppppp :) please y’all question 3 and 4

Answers
Answer:
3) = C (0.505)
4) = B (4.32 kilograms)
Step-by-step explanation:
0.505 is in-between 0.482 and 0.51
1.08 X 4 = 4.32
Answer:
3. C. 0.505 gram
4. B. 4.32 kilograms
Pls I need help !!!!!

Answers
Answer:
y=65 and x=25
Step-by-step explanation:
since 65 and x create a 90 degree angle, you subtract 90-65 to get the x (25.) and then since x and y ALSO make a 90 degree angle you subtract 90-25 to get y (65.)
Use the given acceleration function and initial conditions to find the velocity vector v(c), and position vector r(t). Then find the position at time it = 3 . a(c)=e2t−4kv(0)=2i+9i+k,r(0)=0 v(t)=
Answers
The position vector r(t) for the time t=3 is r(3) = (\(e^{\frac{6}{2}\))i + (12e³ - 4k)j.
The velocity vector v(t) can be found by taking the derivative of the acceleration vector a(t) with respect to time and by using the initial velocity vector v(0):
v(t) = d/dt(a(t)) = 2et + v(0)
= 2et + (2i + 9j + k)
= (2e²t + 2)i + (9e²t + 9)j + (4e²t + k)
The position vector r(t) can be found by integrating the acceleration vector a(t) with respect to time and by using the initial position vector r(0):
r(t) = ∫a(t)dt = e²t²/2 - 4kt + r(0)
= (e²t²/2)i + (4et - 4k)j + r(0)
= (e²t²/2)i + (4et - 4k)j
To find the position at time t=3, substitute t=3 into the equation for r(t):
r(3) = (\(e^{\frac{6}{2}\))i + (12e³ - 4k)j
Therefore, the position vector r(t) for the time t=3 is r(3) = (\(e^{\frac{6}{2}\))i + (12e³ - 4k)j.
Learn more about the position vector here:
https://brainly.com/question/31137212.
#SPJ4
"Your question is incomplete, probably the complete question/missing part is:"
Use the given acceleration function and initial conditions to find the velocity vector v(c), and position vector r(t). Then find the position at time it = 3.
a(c)=e²t-4k
v(0)=2i+9i+k, r(0)=0.
v(t)=
IS IT A FUNCTION? PLEASE HELP ILL HIVE BRAINLEST! SHOW WORK ‼️‼️
1) (-5,-3)(7,2)(3,8)(5,-3) (3,-8)
Answers
Answer:
No, this is not a function. If you place the points, it will not pass the vertical line test. And, in a function, each x-coordinate has to have one y-coordinate. In this problem, there are two x-coordinates of 3, and they both have a different y-coordinate.
Step-by-step explanation:
determine the solution of the differential equation (1) y′′(t) y(t) = g(t), y(0) = 1, y′(0) = 1, for t ≥0 with (2) g(t) = ( et sin(t), 0 ≤t < π 0, t ≥π]
Answers
The solution of the differential equation y′′(t) y(t) = g(t),
y(0) = 1, y′(0) = 1, for t ≥ 0 with
g(t) = (et sin(t), 0 ≤ t < π 0, t ≥ π] is:
y(t) = - t + \(c_4\) for 0 ≤ t < πy(t) = \(c_5\) for t ≥ π.
where \(c_4\) and \(c_5\) are constants of integration.
The solution of the differential equation
y′′(t) y(t) = g(t),
y(0) = 1,
y′(0) = 1, for t ≥ 0 with
g(t) = (et sin(t), 0 ≤ t < π 0, t ≥ π] is as follows:
The given differential equation is:
y′′(t) y(t) = g(t)
We can write this in the form of a second-order linear differential equation as,
y′′(t) = g(t)/y(t)
This is a separable differential equation, so we can write it as
y′dy/dt = g(t)/y(t)
Now, integrating both sides with respect to t, we get
ln|y| = ∫g(t)/y(t) dt + \(c_1\)
Where \(c_1\) is the constant of integration.
Integrating the right-hand side by parts,
let u = 1/y and dv = g(t) dt, then we get
ln|y| = - ∫(du/dt) ∫g(t)dt dt + \(c_1\)
= - ln|y| + ∫g(t)dt + \(c_1\)
⇒ 2 ln|y| = ∫g(t)dt + \(c_2\)
Where \(c_2\) is the constant of integration.
Taking exponentials on both sides,
we get |y|² = \(e^{\int g(t)}dt\ e^{c_2\)
So we can write the solution of the differential equation as
y(t) = ±\(e^{(\int g(t)dt)/ \sqrt(e^{c_2})\)
= ±\(e^{(\int g(t)}dt\)
where the constant of integration has been absorbed into the positive/negative sign depending on the boundary condition.
Using the initial conditions, we get
y(0) = 1
⇒ ±\(e^{\int g(t)}dt\) = 1y′(0) = 1
⇒ ±\(e^{\int g(t)}dt\) dy/dt + 1 = 0
The above two equations can be used to solve for the constant of integration \(c_2\).
Using the first equation, we get
±\(e^{\intg(t)\)dt = 1
⇒ ∫g(t)dt = 0,
since g(t) = 0 for t ≥ π.
So, the first equation gives us no information.
Using the second equation, we get
±\(e^{\intg(t)}dt\) dy/dt + 1 = 0
⇒ dy/dt = - 1/\(e^{\intg(t)dt\)
Now, integrating both sides with respect to t, we get
y = \(- \int1/e^{\intg(t)\)dt dt + c₃
Where c₃ is the constant of integration.
Using the second initial condition y′(0) = 1,
we get
1 = dy/dt = - 1/\(e^{\int g(t)}\)dt
⇒ \(e^{\int g(t)}\)dt = - 1
Now, substituting this value in the above equation, we get
y = - ∫1/(-1) dt + c₃
= t + c₃
To know more about differential equation, visit:
https://brainly.com/question/25731911
#SPJ11
4. amanda wants to save 5% of her income each month for retirement. if she makes $2300 per month as a dental
assistant, how much should save each month?
a. $11500
b. $460
c. $46
d. $115
Answers
Amanda should save $115 each month for retirement .Answer A is correct
To calculate how much Amanda should save each month, we need to determine 5% of her monthly income as a dental assistant.
A 5% savings rate means she needs to save 5% of her monthly income, which is $2300. To find this amount, we can multiply her income by 5%:
$2300 * 0.05 = $115
Therefore, Amanda should save $115 each month for retirement.
Option (d) $115 is the correct answer. The other options, (a) $11500, (b) $460, and (c) $46, are incorrect because they do not correspond to 5% of Amanda's monthly income.
By saving $115 each month, Amanda will accumulate savings for her retirement over time. It's important to note that retirement savings should be tailored to individual circumstances, goals, and any additional financial commitments or considerations. Amanda may want to consult with a financial advisor to discuss her specific retirement plans and determine the most suitable savings strategy for her long-term financial security. Answer A is correct
for more such questions on save visit
https://brainly.com/question/29292933
#SPJ8
The area of a rectangle 12x^2 + 32x square units. If the width can be represented by 3x + 8, write an expression to represent the length of the rectangle.
Answers
Answer:
Step-by-step explanation:
The area of a rectangle is length time width.
A=LW
In this case,
A=32x^2+12
W=4x
Solve for L
L=A/W
Substitute
L=(32x^2+12)/4x
L=(8x^2+3)/x
HELP MEEE PLZ :( Saeed sells beaded necklaces. Each large necklace sells for 6.50 $ and each small necklace sells for4.90$ . How much will he earn from selling7 large necklaces and 6 small necklaces?
Answers
45.50 + 29.40 = 74.90
He will earn $74.90
Answer:
74.9
Step-by-step explanation:
a six foot man standing 200 feet from a tower observes the angle of elevation to the top of the tower to be 67 degrees. how high is the tower?
Answers
So, the height of the tower is approximately 363.6 feet.
You can use trigonometry to solve this problem.
If we call the height of the tower "h" and the distance between the man and the base of the tower "d", then the angle of elevation is defined as the angle between the line of sight from the observer to the top of the tower and the horizontal line.
We can use the tangent function to relate the angle of elevation to the height and distance.
tan(67) = h/d
We know that the distance between the man and the tower is 200 feet. We can use this information to find the height of the tower.
h = d * tan(67)
h = 200 * tan(67)
The height of the tower is approximately 363.6 feet.
Please note that due to the approximation of the trigonometric functions, the answer may not be exactly as calculated.
To learn more about angle of elevation
Visit; brainly.com/question/16716174
#SPJ4
Which rule below represents a transformation that does NOT preserve the length of the sides of the quadrilateral?

Answers
What is the volume of the square-based pyramid?
a: 36in^3
b: 96in^3
c: 144in^3
d: 288in^3

Answers
Answer:
Volume of square-based pyramid = 96 in³
Step-by-step explanation:
Given:
Base side of square = 6 inch
Height of pyramid = 8 inch
Find:
Volume of square-based pyramid
Computation:
Area of square base = Side x Side
Area of square base = 6 x 6
Area of square base = 36 in²
Volume of square-based pyramid = (1/3)(A)(h)
Volume of square-based pyramid = (1/3)(36)(8)
Volume of square-based pyramid = (1/3)(36)(8)
Volume of square-based pyramid = (12)(8)
Volume of square-based pyramid = 96 in³
10. Prove that if f is uniformly continuous on I CR then f is continuous on I. Is the converse always true?
Answers
F is continuous at every point x₀ ∈ I. Thus, f is continuous on an interval I.
Regarding the converse, the statement "if f is continuous on an interval I, then it is uniformly continuous on I" is not always true. There exist functions that are continuous on a closed interval but not uniformly continuous on that interval. A classic example is the function f(x) = x² on the interval [0, ∞). This function is continuous on the interval but not uniformly continuous.
To prove that if a function f is uniformly continuous on interval I, then it is continuous on I, we need to show that for any ε > 0, there exists a δ > 0 such that for any x, y ∈ I, if |x - y| < δ, then |f(x) - f(y)| < ε.
Since f is uniformly continuous on I, for the given ε, there exists a δ > 0 such that for any x, y ∈ I, if |x - y| < δ, then |f(x) - f(y)| < ε.
Now, let's consider an arbitrary point x₀ ∈ I and let ε > 0 be given. Since f is uniformly continuous, there exists a δ > 0 such that for any x, y ∈ I, if |x - y| < δ, then |f(x) - f(y)| < ε.
Now, choose δ' = δ/2. For any y ∈ I such that |x₀ - y| < δ', we have |f(x₀) - f(y)| < ε.
Therefore, for any x₀ ∈ I and ε > 0, we can find a δ' > 0 such that for any y ∈ I, if |x₀ - y| < δ', then |f(x₀) - f(y)| < ε.
This shows that f is continuous at every point x₀ ∈ I. Thus, f is continuous on interval I.
Learn more about arbitrary point:
https://brainly.com/question/19195471
#SPJ11
A + B + C = 180º for C
Answers
Answer: It is 60 degrees.
Answer:
\(C=60\)
Step-by-step explanation:
3 letters add up to 180 so 180 divided by 3 would equal 60 degrees:)
Hope this helps and pls do mark me brainliest if you can:)
4. Factor Completely *
(1 Point)
5x3 + 40x2 - 2x - 16
Answers
Answer:
(x+8)(5x2−2)
Step-by-step explanation:
Hope this helps have a nice day :)
Assuming that n,n2, find the sample sizes needed to estimate (P1-P2) for each of the following situations a.A margin of error equal to 0.11 with 99% confidence. Assume that p1 ~ 0.6 and p2 ~ 0.4. b.A 90% confidence interval of width 0.88. Assume that there is no prior information available to obtain approximate values of pl and p2 c.A margin of error equal to 0.08 with 90% confidence. Assume that p1 0.19 and p2 0.3. P2- a. What is the sample size needed under these conditions? (Round up to the nearest integer.)
Answers
The following parts can be answered by the concept from Standard deviation.
a. We need a sample size of at least 121 for each group.
b. We need a sample size of at least 78 for each group.
c. We need a sample size of at least 97.48 for each group.
To find the sample size needed to estimate (P1-P2) for each of the given situations, we can use the following formula:
n = (Zα/2)² × (p1 × q1 + p2 × q2) / (P1 - P2)²
where:
- Zα/2 is the critical value of the standard normal distribution at the desired confidence level
- p1 and p2 are the estimated proportions in the two populations
- q1 and q2 are the complements of p1 and p2, respectively (i.e., q1 = 1 - p1 and q2 = 1 - p2)
- (P1 - P2) is the desired margin of error
a. For a margin of error equal to 0.11 with 99% confidence, assuming p1 ~ 0.6 and p2 ~ 0.4, we have:
Zα/2 = 2.576 (from standard normal distribution table)
p1 = 0.6, q1 = 0.4
p2 = 0.4, q2 = 0.6
(P1 - P2) = 0.11
Plugging in the values, we get:
n = (2.576)² × (0.6 × 0.4 + 0.4 × 0.6) / (0.11)²
n ≈ 120.34
Therefore, we need a sample size of at least 121 for each group.
b. For a 90% confidence interval of width 0.88, assuming no prior information is available to obtain approximate values of p1 and p2, we have:
Zα/2 = 1.645 (from standard normal distribution table)
(P1 - P2) = 0.88
Since we have no information about p1 and p2, we can assume them to be 0.5 each (which maximizes the sample size and ensures a conservative estimate).
Plugging in the values, we get:
n = (1.645)² × (0.5 × 0.5 + 0.5 × 0.5) / (0.88)²
n ≈ 77.58
Therefore, we need a sample size of at least 78 for each group.
c. For a margin of error equal to 0.08 with 90% confidence, assuming p1 = 0.19 and p2 = 0.3, we have:
Zα/2 = 1.645 (from standard normal distribution table)
q1 = 0.81
q2 = 0.7
(P1 - P2) = 0.08
Plugging in the values, we get:
n = (1.645)² × (0.19 × 0.81 + 0.3 × 0.7) / (0.08)²
n ≈ 97.48
Therefore, we need a sample size of at least 98 for group 1. For group 2, we can use the same sample size as group 1, or we can adjust it based on the expected difference between p1 and p2 (which is not given in this case).
To learn more about Standard deviation here:
brainly.com/question/12402189#
#SPJ11
The following parts can be answered by the concept from Standard deviation.
a. We need a sample size of at least 121 for each group.
b. We need a sample size of at least 78 for each group.
c. We need a sample size of at least 97.48 for each group.
To find the sample size needed to estimate (P1-P2) for each of the given situations, we can use the following formula:
n = (Zα/2)² × (p1 × q1 + p2 × q2) / (P1 - P2)²
where:
- Zα/2 is the critical value of the standard normal distribution at the desired confidence level
- p1 and p2 are the estimated proportions in the two populations
- q1 and q2 are the complements of p1 and p2, respectively (i.e., q1 = 1 - p1 and q2 = 1 - p2)
- (P1 - P2) is the desired margin of error
a. For a margin of error equal to 0.11 with 99% confidence, assuming p1 ~ 0.6 and p2 ~ 0.4, we have:
Zα/2 = 2.576 (from standard normal distribution table)
p1 = 0.6, q1 = 0.4
p2 = 0.4, q2 = 0.6
(P1 - P2) = 0.11
Plugging in the values, we get:
n = (2.576)² × (0.6 × 0.4 + 0.4 × 0.6) / (0.11)²
n ≈ 120.34
Therefore, we need a sample size of at least 121 for each group.
b. For a 90% confidence interval of width 0.88, assuming no prior information is available to obtain approximate values of p1 and p2, we have:
Zα/2 = 1.645 (from standard normal distribution table)
(P1 - P2) = 0.88
Since we have no information about p1 and p2, we can assume them to be 0.5 each (which maximizes the sample size and ensures a conservative estimate).
Plugging in the values, we get:
n = (1.645)² × (0.5 × 0.5 + 0.5 × 0.5) / (0.88)²
n ≈ 77.58
Therefore, we need a sample size of at least 78 for each group.
c. For a margin of error equal to 0.08 with 90% confidence, assuming p1 = 0.19 and p2 = 0.3, we have:
Zα/2 = 1.645 (from standard normal distribution table)
q1 = 0.81
q2 = 0.7
(P1 - P2) = 0.08
Plugging in the values, we get:
n = (1.645)² × (0.19 × 0.81 + 0.3 × 0.7) / (0.08)²
n ≈ 97.48
Therefore, we need a sample size of at least 98 for group 1. For group 2, we can use the same sample size as group 1, or we can adjust it based on the expected difference between p1 and p2 (which is not given in this case).
To learn more about Standard deviation here:
brainly.com/question/12402189#
#SPJ11
I need help on this question I don’t get it?

Answers
Step-by-step explanation:
the key is to understand that
12 in = 1 ft
1 ft³ (= a cube of 1 ft × 1ft × 1ft or 12in × 12 in × 12 in = 1728 in³) weighs 40 lbs.
her truck can only carry 1,700 lbs without breaking down.
but it would have space for 66×60×24 = 95040 in³ =
95040/1728 = 55 ft³ of soil, which would weigh
55 × 40 = 2200 lbs (too much for the truck).
the same ratio as for the weight her truck can carry applies for the filled volume of the truck bed with that weight :
1700/2200 = 17/22
so, she can only fill 17/22 of her truck bed volume with soil.
i)
percents are calculated by multiplying the ratio by 100 :
17/22 × 100 = 77.27272727... % ≈ 77%
she can fill about 77% of her truck bed with soil without going over the weight limit.
ii)
since she can transport only 1700 lbs in one trip, and 1 ft³ of soil weighs 40 lbs, she can transport
1700/40 = 42.5 ft³ of soil per trip.
she would then earn
42.5 × 1.5 = $63.75 per trip.
researchers investigated whether there is a difference between two headache medications, r and s. researchers measured the mean times required to obtain relief from a headache for patients taking one of the medications. from a random sample of 75 people with chronic headaches, 38 were randomly assigned to medication r and the remaining 37 were assigned to medication s. the time, in minutes, until each person experienced relief from a headache was recorded. the sample mean times were calculated for each medication. have the conditions been met for inference with a confidence interval for the difference in population means?
Answers
Here need to perform an F-test to check for equal variances before we can determine if the conditions have been met for inference with a confidence interval for the difference in population means.
To determine if the conditions have been met for inference with a confidence interval for the difference in population means, we need to check the following:
Independence: The samples are independent of each other. Since the patients were randomly assigned to one of the two medications, we can assume that the independence condition is met.
Normality: The sample sizes are large enough for us to assume that the distribution of the sample means is approximately normal by the Central Limit Theorem. A general rule of thumb is that the sample sizes should be greater than or equal to 30. In this case, we have a sample size of 38 for medication r and 37 for medication s, so the normality condition is met.
Equal variances: We need to check if the variances of the two populations are equal. We can perform a hypothesis test for equal variances to determine this. A common test for equal variances is the F-test
Therefore, we need to perform an F-test to check for equal variances. If the variances are equal, we can use a pooled t-test for the difference in population means
Learn more about F-test here
brainly.com/question/29999859
#SPJ4