the makers of biodegradable straws have an automated machine that is set to fill each box with 100 straws. at various times in the packaging process, we select a random sample of 121 boxes to see whether or not the machine is filling the boxes with an average of 100 straws per box which of the following is a statement of the null hypothesis?
a. The machine fills the boxes with the proper amount of straws. The average is 100 straws. b. The machine is not filling the boxes with the proper amount of straws The average is not 100 straws. c. The machine is not putting enough straws in the boxes. The average is less than 100 straws.
Answers
The correct answer is: a. The machine fills the boxes with the proper amount of straws. The average is 100 straws. In hypothesis testing, the null hypothesis typically represents a statement of no effect or no difference. In this case, it means that the machine is functioning properly and filling the boxes with the expected average of 100 straws per box.
The null hypothesis in this scenario is option a, which states that the machine fills the boxes with the proper amount of straws, and the average is 100 straws per box. This is because the null hypothesis assumes that there is no significant difference between the observed sample mean and the expected population mean of 100 straws per box. To reject this null hypothesis, we would need to find evidence that the machine is not filling the boxes with the proper amount of straws, which would require further investigation and analysis. In conclusion, the null hypothesis can be summarized in three paragraphs as follows: The null hypothesis for the makers of biodegradable straws is that the machine fills the boxes with the proper amount of straws, and the average is 100 straws per box.
This hypothesis assumes that there is no significant difference between the observed sample mean and the expected population mean. To test this hypothesis, a random sample of 121 boxes is selected to determine whether or not the machine is filling the boxes with an average of 100 straws per box. If the observed sample mean is not significantly different from the expected population mean, then the null hypothesis is accepted. However, if the observed sample mean is significantly different from the expected population mean, then the null hypothesis is rejected, and further investigation is required to determine the cause of the difference.
To know more about average visit :-
https://brainly.com/question/28873924
#SPJ11
Related Questions
HELP PLEASE I NEED THE ANWSER NOOOOOOW

Answers
Answer:
4
Hope this helps
evaluate the line integral along the path c given by x = 2t, y = 4t, where 0 ≤ t ≤ 1. c x 3y2 dy
Answers
To evaluate the line integral along the path C given by x = 2t, y = 4t, where 0 ≤ t ≤ 1, we can follow these steps:
1. Rewrite the given integral in terms of t using the parameterization of the path: C: x = 2t, y = 4t.
2. Compute the derivatives dx/dt and dy/dt.
3. Substitute the parameterization and derivatives into the line integral.
4. Evaluate the integral over the specified interval.
Step 1:
The integral in terms of t is: ∫(3y² dy)
Step 2:
dx/dt = 2
dy/dt = 4
Step 3:
Substitute the parameterization and derivatives:
∫(3(4t)² * 4 dt) over the interval [0, 1]
Step 4:
Evaluate the integral:
∫(3 * 16t² * 4 dt) from 0 to 1
= 192 ∫(t² dt) from 0 to 1
Now, integrate and evaluate the integral:
= 192 * [1/3 * t^3] from 0 to 1
= 192 * (1/3 * 1^3 - 1/3 * 0^3)
= 64
So, the value of the line integral along the path C is 64.
Learn more about derivatives: https://brainly.com/question/28376218
#SPJ11
solve this solution using elimination
-8x+6y=34
-8x-4y=44
Answers
Answer:
y=-1
x=-5
Step-by-step explanation:
Subtract the two equations together to eliminate the 8x
1) -8x+6y=34
-8x-4y=44
2) -8x+6y=34
+8x+4y=-44
3) 10y = -10
4) y=-1
Substitute: -8x+6(-1)=34
-8x=40
x=-5
Jasmine buys a toy horse for $36 the store increases their purchase by 10% what is the sales price of her toy horse
Answers
Answer:
39.6
Step-by-step explanation:
36*0.10 = 3.6
36+3.6=39.6
Consider a fractal line with fractal dimension D. The mean-square distance between monomers u and v along this line is ⟨(R(u)−R(v))2⟩=b2(v−u)2/D. Calculate the mean-square end-to-end distance R2 and radius of gyration Rg2 for this fractal line. Determine the ratio R2/Rg2 symbolically and then calculate this ratio for fractal dimensions D=1,1.7 and 2 .
Answers
The mean-square end-to-end distance for the fractal line is ⟨R2⟩ = b².L^(1-D).
The mean-square end-to-end distance for the fractal line is as follows.⟨R2⟩ = ⟨(R(u)- R(v))^2⟩ for u = 0 and v = L where L is the length of the line.⟨R2⟩ = b²/L^2.D.L = b².L^(1-D).
Thus, the mean-square end-to-end distance for the fractal line is ⟨R2⟩ = b².L^(1-D).
The radius of gyration Rg is defined as follows.
Rg² = (1/N)∑_(i=1)^N▒〖(R(i)-R(mean))〗²where N is the number of monomers in the fractal line and R(i) is the position vector of the ith monomer.
R(mean) is the mean position vector of all monomers.
Since the fractal dimension is D, the number of monomers varies with the length of the line as follows.N ~ L^(D).
Therefore, the radius of gyration for the fractal line is Rg² = (1/L^D)∫_0^L▒〖(b/v^(1-D))^2 v dv〗 = b²/L^2.D(1-D). Thus, Rg² = b².L^(2-D).
The ratio R²/Rg² is given by R²/Rg² = L^(D-2).
When D = 1, R²/Rg² = 1/L. When D = 1.7, R²/Rg² = 1/L^0.7. When D = 2, R²/Rg² = 1/L.
This provides information on mean-square end-to-end distance and radius of gyration for fractal line with a given fractal dimension.
Learn more about mean-square from the given link
https://brainly.com/question/30763770
#SPJ11
A roast turkey is taken from an oven when its temperature has reached 185°F and is placed on a table in a room where the temperature is 75°F. (Round your answers to the nearest whole number.)(a) If the temperature of the turkey is 150°F after half an hour, what is the temperature after 55 minutes?T(55) = 1 °F(b) When will the turkey have cooled to 105°?t = 2 min
Answers
Using unitary method, turkey's temperature after 55 minutes is 120.815° Also, it will take approximately 68 minutes for the turkey to cool down to 105°.
Now, According to the question:
What is unitary method?
The formula of the unitary method is to find the value of a single unit and then multiply the value of a single unit to the number of units to get the necessary value.
Reduction in temperature after 30 minutes = 185° - 150° = 35°
Reduction in temperature after 1 minute = 35/30 = 1.167°
Reduction in temperature after 55 minutes = 55 × 1.167 = 64.185°
Temperature after 50 minutes = 185° - 64.185° = 120.815°
Decrease in temperature when the turkey has cooled down to 105° = 185° - 105° = 80°
Time taken by the turkey to cool down 80° = 80/1.167 = 68.55 minutes.
Learn more about Temperature at:
https://brainly.com/question/12264337
#SPJ4
In a family with 7 children, excluding multiple births, what is the probability of having 7 boys? Assume that a girl is as likely as a boy at each birth. Let E be the event that the family has 7 boys, where the sample space S is the set of all possible permutations of girls and boys for 7 children. Find the number of elements in event E, n(E), and the total number of outcomes in the sample space, n(S). n(E) = n(S)=
Answers
The probability of having 7 boys in a family with 7 children is 1 out of 128, as there is only one favorable outcome out of 128 total possible outcomes.
To find the probability, we need to calculate n(E) and n(S).
In this case, event E represents the scenario where all 7 children are boys. The sample space S consists of all possible permutations of boys and girls for the 7 children, which is 2^7 = 128.
This is because each child has 2 possibilities (boy or girl), and we multiply these possibilities for all 7 children.
Since event E includes only one specific outcome (all boys), n(E) is equal to 1. Therefore, both n(E) and n(S) are 1 and 128, respectively. The probability of having 7 boys is given by n(E)/n(S) = 1/128.
Learn more about Probability click here : brainly.com/question/30034780
#SPJ11
A contest offers 20 prizes, with first prize worth $12,000 and each successive prize worth $400 less than the preceding prize.
Answers
The 20th prize is $4400.
It is a sequence where the difference between each consecutive terms is the same.
Example:
2, 4, 6, 8 is an arithmetic sequence.
We have,
First prize = $12,000
Successive prize worth $400 less than the preceding prize.
Now,
We can make an arithmetic sequence.
12,000, 11,600, 11,200, ...
So,
a = 12,000
d = -400
The nth term of an arithmetic sequence.
= a + (n - 1)d
So,
The 20th prize.
= 12,000 + (20 -1)400
= 12,000 - 19 x 400
= 12,000 - 7600
= 4400
Thus,
20th prize = $4400
Learn more about arithmetic sequence here:
https://brainly.com/question/10396151
#SPJ9
X1 and S 2 1 are the sample mean and sample variance from a population with mean µ1 and variance σ 2 1. Similarly, X2 and S 2 2 are the sample mean and sample variance from a second independent population with mean µ2 and variance σ 2 2. The sample sizes are n1 and n2, respectively. A) Show that X1 − X2 is an unbiased estimator of µ1 − µ2. B) Find the standard error of X1 − X2. How could you estimate the standard error?
Answers
a. X1 - X2 is an unbiased estimator of µ1 - µ2.
b. The standard error of X1 - X2 is √(S1²/n1 + S2²/n2).
A) To show that X1 − X2 is an unbiased estimator of µ1 − µ2, we need to show that the expected value of X1 − X2 equals µ1 − µ2.
E[X1 − X2] = E[X1] − E[X2] (since expectation is linear)
= µ1 − µ2 (since X1 and X2 are unbiased estimators of µ1 and µ2, respectively)
Therefore, X1 − X2 is an unbiased estimator of µ1 − µ2.
B) The variance of X1 − X2 can be calculated as:
Var[X1 − X2] = Var[X1] + Var[X2] (since X1 and X2 are independent)
= σ1²/n1 + σ2²/n2
The standard error of X1 − X2 is the square root of the variance:
SE(X1 − X2) = √(σ1²/n1 + σ2²/n2)
To estimate the standard error, we can use the sample standard deviations S1 and S2 as estimators of the population standard deviations σ1 and σ2, respectively. Therefore, the estimated standard error of X1 − X2 is:
SE(X1 − X2) ≈ √(S1²/n1 + S2²/n2)
Learn more about the standard error at
https://brainly.com/question/13179711
#SPJ4
Which line contains the points (1,-2) and (-3,2)?
A. Y= -x+1
B. Y= -x-1
C. Y= 1/2x-1
D. Y= -1/2x+1
Answers
Answer: y = -x1 - 1
Step-by-step explanation:
Do both points satisfy this equation?:
(1,-2): -2 = -1 -1 Yes
(-3,2): 2 = -(-3)-1 [or 3-1=2] Yes
The line contains the points (1,-2) and (-3,2) is Y= -x-1. The correct option is B.
What is coordinate geometry?A coordinate plane is a 2D plane which is formed by the intersection of two perpendicular lines known as the x-axis and y-axis. A coordinate system in geometry is a method for determining the positions of the points by using one or more numbers or coordinates.
Given that the points are (1,-2) and (-3,2). The equation of the line will be the line which satisfies the given points.
Y= -x-1
At points (1,-2),
Y= -x-1
-2=-1-2
-2=-2
At point(-3,2).
Y =-x-1
2=3-1
2 = 2
The line Y= -x-1 is passing through the points (1,-2) and (-3,2). The correct option is B.
To know more about coordinate geometry follow
https://brainly.com/question/18269861
#SPJ5
One thing that many students think about when they register for classes at a university is how many textbooks they are going to have to buy for the class and how much the books are going to cost. To add to this, a lot of the students wonder if they are even going to use the books that they are required to buy. In fact, some students don’t buy books for their classes because they are convinced that they don’t really need them to achieve an acceptable grade.
This is exactly the line of thinking that textbook writers are afraid of—they want students to have to use their books to get good grades in their classes, and they want professors to think that students need their books so that they require them as part of their classes.
Even though textbooks have a definite value—they are available to students who use them when their professors are not—there is some debate on whether they are really needed as part of university classes.
Recently, a researcher conducted an experiment to address this question. In the experiment, the researcher compared two sections of his introductory statistics course, a course required for all liberal arts and sciences students. Students who were enrolled in the fall semester of the course were told that buying the textbook was optional, whereas students enrolled in the spring semester were told that buying the textbook was required. All 380 of the students (190 in the fall and 190 in the spring) completed the course, and they all took the final exam, which consisted of some calculations and several conceptual essay questions.
When the professor finished scoring the essays, he compared the final exam grades of both sections of the class. He found just what he thought he would—there were no differences in the scores on the exams between the section that thought the textbook was optional and the section that thought the textbook was required. The average grade for the fall semester was 84.3%, and for the spring semester it was 85.2%.
Based on this study, the researcher concluded that textbooks were not necessary or helpful for learning, since there were no differences in scores between the two sections.
No control or comparison group
No random assignment
Participant bias
Small sample size
Poor sample selection
Attrition or mortality
Experimenter bias
Confuse correlation with causality
DV is not reliable, precise or accurate
DV is not valid
DV is not objectively scored
Premature generalization of results
Answers
The study conducted by the researcher suffers from several limitations, including the absence of a control group, small sample size, participant bias, and experimenter bias. Furthermore, the sample selection is inadequate, as all the participants are students of one course in a single university.
Moreover, the study fails to account for extraneous variables that might affect the results. Therefore, that textbooks are not necessary or helpful for learning is premature and cannot be generalized to other courses or universities. T he study is flawed, and more research is needed to assess the effect of textbooks on learning.
The study conducted by the researcher suffers from several limitations. First, there is no control group, which makes it difficult to determine whether the results are due to the absence or presence of the textbook. Second, the sample size is small, which reduces the generalizability of the findings.
Third, there is participant bias, as some students might have bought the textbook even though it was optional, while others might not have bought it even though it was required. Fourth, there is experimenter bias, as the professor who scored the essays knew which section had the textbook and which did not.
Fifth, the sample selection is inadequate, as all the participants are students of one course in a single university. Moreover, the study fails to account for extraneous variables that might affect the results, such as the students' prior knowledge, motivation, and study habits.
Therefore, the textbooks are not necessary or helpful for learning is premature and cannot be generalized to other courses or universities. The study is flawed, and more research is needed to assess the effect of textbooks on learning.
To know more about extraneous variables :
brainly.com/question/31561984
#SPJ11
Which statements are true regarding the diagram? Check all that apply.
1. ΔXYZ ≅ ΔLMN
2. ∠Y ≅ ∠M
3. ∠X ≅ ∠L
4. ∠Z ≅ ∠L
5. YZ ≅ ML
6. XZ ≅ LN

Answers
Answer:
1, 2, 3, 6
Step-by-step explanation:
I don't really know how to explain this but if the only change between the two triangles is that it was reflected, then there was no change of any of the angles or side lengths, you just have to make sure you match up the rights angles and the right sides.
Answer:
Hi how are you doing today Jasmine
Please help me to solve this question

Answers
Answer:
x = 64°, y = 32°
Step-by-step explanation:
The sum of the angles on a straight line = 180° , then angles on PS are
2x + y + 20 = 180 ( subtract 20 from both sides )
2x + y = 160 → (1)
Angles on QT are
x + 3y + 20 = 180 ( subtract 20 from both sides )
x + 3y = 160 → (2)
Solve (1) and (2) simultaneously
Rearrange (1) expressing y in terms of x by subtracting 2x from both sides
y = 160 - 2x → (3)
Substitute y = 160 - 2x into (2)
x + 3(160 - 2x) = 160 ← distribute and simplify left side
x + 480 - 6x = 160
- 5x + 480 = 160 ( subtract 480 from both sides )
- 5x = - 320 ( divide both sides by - 5 )
x = 64
Substitute x = 64 into (3)
y = 160 - 2(64) = 160 - 128 = 32
Then
x = 64°, y = 32°
A binomial experiment consists of 14 trials. The probability of success on trial 7 is 0. 55. What is the probability of success on trial 11?.
Answers
Answer: Using the conditions required for a binomial experiment, the probability of success is the same for each trial in the experiment, Hence, the probability of failure on trial 11 will be 0.16 . The probability of success, p = 0.84; the probability of failure can be expressed as; p(failure) = 1 - p(success) = 1 - 0.84 = 0.16 . The probability of success or failure in each and every trial of a binomial experiment is the same and hence, does not change from trial to trial. Therefore, the probability of failure in the 11th trial is 0.16.
Step-by-step explanation: Generally, one the attributes of a binomial experiment is that the probability of success and failure is constant every trial so given from the question that the probability of success is 0.84 for trial 7, then the probability of failure of trial 7 will be evaluated as => q=1-0.84. q=0.16. And from the attribute stated above the probability of failure of trial 11 is q=0.16
Find the surface area of the figure. Hint: the surface area from the missing prism inside the prism must be ADDED!
Answers
To find the surface area of the figure, we need to consider the individual surfaces and add them together.
First, let's identify the surfaces of the figure:
The lateral surface area of the larger prism (excluding the base)
The two bases of the larger prism
The lateral surface area of the smaller prism (excluding the base)
The two bases of the smaller prism
The lateral surface area of a prism is given by the formula: perimeter of the base multiplied by the height.
The bases of the prisms are rectangles, so their areas can be calculated by multiplying the length by the width.
To find the missing prism's surface area, we need to consider that it is a smaller prism nested inside the larger prism. The lateral surface area and bases of the missing prism should also be included.
Once we have calculated the individual surface areas, we add them together to find the total surface area of the figure.
Without specific measurements or dimensions of the figure, it is not possible to provide a numerical answer. Please provide the necessary measurements or dimensions to calculate the surface area.
Learn more about surface here
https://brainly.com/question/16519513
#SPJ11
for breakfast you eat a bowl of oatmeal and 1/4 cup of added raisins, for lunch, a turkey sandwich and a glass of fresh orange juice. how many servings of fruit and cereal have you had?
Answers
For breakfast, you have had 1/2 a serving of cereal and 1/4 cup of raisins, which count as one serving of fruit.
For breakfast, you have had one serving of cereal and one serving of fruit. In general, one serving of cereal is considered to be one cup, while one serving of fruit is considered to be one half cup. Therefore, in your bowl of oatmeal, you would have had two servings of cereal, and in your quarter cup of raisins, you would have had one serving of fruit. For lunch, you have had one serving of fruit in your glass of orange juice.
Learn more about fruit at : https://brainly.com/question/13048056
#SPJ4
Write the nth term of the following sequence in terms of the first term of the sequence.
10, 20, 40, . . .
Answers
Answer:
5120 or 2560.One of these
Step-by-step explanation:
1. 10*2=20
2. 20*2=40
3. 40*2=80
4. 80*2=160
5. 160*2=320
6. 320*2=640
7. 640*2=1280
8. 1280*2=2560
9. 2560*2=5120
Answer:
2360
Step-by-step explanation:
(One Question..Uhm..nth? I'm assuming Ninth)
10, 20, 40, 80, 160, 320, 640, 1280, 2360
Its just doubling every time
The problem solved plan identified steps to organize your information which of the following answers choose are included in the steps organize your information
Answers
Note that the answer choice that are included in the steps to organize information are:
Organize the problem and find the question. (Option A)Write the facts, organize your thoughts and define your strategy. (Option C)Organize the steps and underline the question. (Option D)What is the rationale for the above response?A. Organizing the problem and determining the question is an important step in problem-solving because it allows you to comprehend the problem and what you need to discover.
C. Writing down the facts, organizing your thoughts, and defining your strategy is also an important step in problem-solving because it allows you to see what information you have and how you will approach the problem.
D. Organizing the steps and underlining the question is also important in problem-solving because it allows you to have a clear understanding of the various steps you must take and the question you must answer.
B. Although it is not included in the steps to organize your information, solving the problem and changing your strategy if necessary is an important step.
Learn more about Organizing Information:
https://brainly.com/question/12677167
#SPJ1
Full Question:
The problem-solving plan identifies steps to organize your information. Which of the following answer choices are included in the steps to organize your information?
A. Organize the problem and find the question.
B. Solve the problem and change your strategy if necessary.
C. Write the facts, organize your thoughts and define your strategy.
D. Organize the steps and underline the question.
What is the GCF of 18 and 54?
Answers
Answer:
its 18 because 18 goes into 18 and 54. goes in 54 3 times
Step-by-step explanation:
.A backpack manufacturer wants to know if students in high school carry more books than college students do. Company researchers take a simple random sample from each group and record the number of textbooks each subject is carrying. They get the following data:
High school: (5, 3, 2, 5, 6, 4, 7, 6, 5, 4, 3, 2, 1, 4, 3, 0, 2)
College: (5, 3, 2, 4, 1, 0, 0, 3, 6, 2, 1, 3, 1, 2, 4, 4, 2)
Using high-school students as sample 1 and college students as sample 2, the researchers compute the following sample statistics and t statistic:
= 3.647, s1 = 1.9, n1 = 17
= 2.529, s2 = 1.7, n2 = 17
t = 1.808
Answers
Step-by-step explanation:
The t statistic, t = 1.808, is calculated using the sample statistics from the high school (sample 1) and college (sample 2) groups. In order to determine if high school students carry more books than college students, we need to perform a hypothesis test.
Let's set up the hypotheses:
Null hypothesis (H0): The mean number of books carried by high school students is equal to the mean number of books carried by college students.
Alternative hypothesis (Ha): The mean number of books carried by high school students is greater than the mean number of books carried by college students.
Next, we'll perform a one-tailed independent samples t-test to compare the means of the two groups using the given t statistic, degrees of freedom (df), and alpha level (α).
Given the t statistic of 1.808 and the degrees of freedom (df) calculated as df = n1 + n2 - 2 = 17 + 17 - 2 = 32, we can consult a t-distribution table or use statistical software to find the critical value corresponding to our desired alpha level.
Finally, by comparing the calculated t statistic to the critical value, we can determine whether to reject or fail to reject the null hypothesis. If the calculated t statistic is greater than the critical value, we reject the null hypothesis and conclude that high school students carry more books than college students. Otherwise, if the calculated t statistic is less than or equal to the critical value, we fail to reject the null hypothesis and conclude that there is not enough evidence to support the claim that high school students carry more books than college students.
#SPJ11
May 03, 2023
i) y = -1/2x² + 6x + 5
2
Answers
Step-by-step explanation:
To evaluate y when x = 2 in the equation y = -1/2x² + 6x + 5, we simply substitute x = 2 into the equation and solve for y:
y = -1/2(2)² + 6(2) + 5
y = -1/2(4) + 12 + 5
y = -2 + 12 + 5
y = 15
Therefore, when x = 2, y = 15 in the equation y = -1/2x² + 6x + 5.
What is the value of x?
K
83°
L
M
(9x + 40)
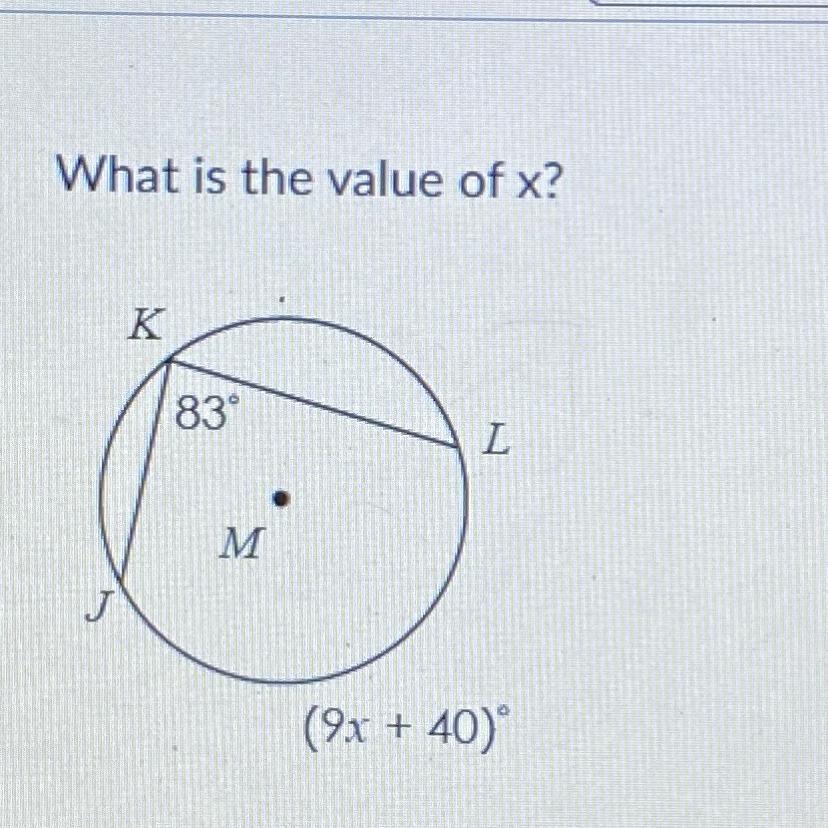
Answers
Answer:
This inscribed angle is half of the intercepted arc JL, so 2(83)= 9x +40.
166 -40 = 9x, x=14.
Step-by-step explanation:
The value of x in the given figure is 14 which we obtain by inscribed angle is half of the intercepted arc.
The inscribed angle is half of the intercepted arc.
83 = 1/2(9x+40)
Now let us find the value for x
83= 9/2x + 20
Subtract 20 from both sides to isolate the x variable
83-20=9/2x
63=9/2x
126=9x
Divide both sides by 9
14 is value of x
x=14
To learn more on Angles click:
https://brainly.com/question/28451077
#SPJ2
what do -4 (x+7)-4 equal
Answers
Answer:
-4x-32 Can i please get a brainliest because this correct.
Step-by-step explanation:
−4(x+7)−4
Distribute:
=(−4)(x)+(−4)(7)+−4
=−4x+−28+−4
Combine Like Terms:
=−4x+−28+−4
=(−4x)+(−28+−4)
=−4x+−32
Answer:
=−4x−32
find the surface area of each rectangular prism

Answers
1) SA= 2[(9*13)+(3*13)+(3*9)] = 366 mm^2
2) SA = 2[(4*20)+(6*20)+(6*4)] = 448 cm^2
3) SA= 2[(6*5)+(14*5)+(14*6)] = 368 m^2
4) SA= 2[(4*17)+(14*17)+(14*4)] = 724 ft^2
5) SA= 2[(4*13)+(19*13)+(19*4)] = 750 in^2
6) SA = 2[(3*9)+(14*9)+(14*3)] = 390 mm^2
Help
Need the steps >.

Answers
Answer:
x = 3
Step-by-step explanation:
using the rule of exponents
\(4^{x}\) = \((\frac{1}{2}) ^{x-9}\)
\((2^2)^{x}\) = \((2^{-1}) ^{x-9}\)
\(2^{2x}\) = \(2^{-1(x-9)}\) = \(2^{9-x}\)
suince the bases on both sides are equal, then equate the exponents
2x = 9 - x ( add x to both sides )
3x = 9 ( divide both sides by 3 )
x = 3
Say that the economy is in a recession, which is causing the value of gold to fall by three percent. If you have gold reserves which were previously worth $8,590, how much value have you lost as a result of this recession, to the nearest cent? a. $590.00 b. $286.33 c. $257.70 d. $250.19 Please select the best answer from the choices provided A B C D
Answers
The value lost as a result of the recession is $8,332.30.
From the given answer choices, the closest value to $8,332.30 is option c) $257.70.
So, the correct answer is option c) $257.70.
To calculate the value lost as a result of the recession, we need to find three percent of the initial value of the gold reserves and subtract it from the initial value.
First, let's find three percent of $8,590:
(3/100) * $8,590 = $257.70
This means that the value of the gold reserves has decreased by $257.70 due to the recession.
To find the value lost, we subtract this amount from the initial value:
$8,590 - $257.70 = $8,332.30
Therefore, the value lost as a result of the recession is $8,332.30.
From the given answer choices, the closest value to $8,332.30 is option c) $257.70.
So, the correct answer is option c) $257.70.
In conclusion, the value lost as a result of the recession is approximately $257.70.
For similar question on recession.
https://brainly.com/question/532515
#SPJ8
Evaluate These Equations.
(x - 12) = y + z
for x = -23, y=-5, and z=-10
Answers
Substituting the given values of x, y, and z into the equation (x - 12) = y + z, we get -23 - 12 = -5 - 10. Simplifying the equation, we get -35 = -15. However, this equation is not true, which means that there is no solution for this system of equations.
To evaluate the equation (x - 12) = y + z for the given values of x, y, and z, we substitute the values into the equation as follows:
(-23 - 12) = -5 - 10
Simplifying the left-hand side, we get:
-35 = -5 - 10
Simplifying the right-hand side, we get:
-35 = -15
This equation is not true, which means that there is no solution for this system of equations. In other words, there is no value of x, y, and z that satisfy the equation (x - 12) = y + z when x = -23, y = -5, and z = -10.
One way to see why this is the case is to rearrange the equation as follows:
x = y + z + 12
If we substitute the given values of y and z into this equation, we get:
x = -5 - 10 + 12
Simplifying, we get:
x = -3
However, this value of x does not satisfy the original equation (x - 12) = y + z, since:
(-3 - 12) ≠ -5 - 10
Therefore, we can conclude that there is no solution for this system of equations.
Learn more about Equation:
brainly.com/question/29538993
#SPJ11
What prime is 4 greater than a perfect square and 7 less than the next perfect square?
Answers
Answer:
29
Step-by-step explanation:
The squares cannot be very big. For example the difference between 10^ and 11^2 = 100 to 121 which is a difference of 21.
What you are talking about is x + 4 prime + 7 next square.
Write the squares
1
4
9
16
25
36
add 4 to get to the prime, add 7 to get to the next square. That's 12
1 and 4 have a difference of 3 too small
4 and 9 have a difference of 5 too small
9 and 16 have a difference of 7 which is too small
16 and 25 have a difference of 9 which just a little too small.
25 and 36 has a difference of 11. Just right
25 + 4 = 29
29 + 7 = 36
Just right.
Simplify: 3(4x-5) - (3x+2)
Answers
Answer:
Step-by-step explanation:
3(4x-5)-3x+2 work the ()
12x-15-3x+2 combine like terms
9x-13
Suppose X and Y are independent exponential random variables with the same parameter λ, i.e. f
X
(x)=λe
−λx
, for x≥0;f
Y
(y)=λe
−λy
, for y≥0 Let Z=X+Y. Find the PDF of the random variable Z.
Answers
The PDF of random variable Z is given by:
\(f_Z(z) = 0 for z < 0\)
To find the probability density function (PDF) of the random variable Z = X + Y, where X and Y are independent exponential random variables with the same parameter λ, we can use convolution.
The convolution of two random variables is given by the integral of the product of their individual probability density functions.
Let's calculate the convolution for Z.
Let \(f_Z(z)\) be the PDF of Z.
We can express Z as the sum of X and Y:
Z = X + Y+
To find \(f_Z(z)\), we need to compute the convolution integral:
\(f_Z(z) = [f_X(x) * f_Y(z - x)] dx\)
where\(f_X(x)\) and \(f_Y(y)\) are the PDFs of X and Y, respectively.
Substituting the exponential PDFs:
\(f_Z\)(z) = ∫[\(λe^\)(-λx) * \(λe^\)(-λ(z - x))] dx
Simplifying:
\(f_Z\)(z) = \(λ^2\)∫[e^(-λx) * e^(-λz + λx)] dx
\(f_Z\)(z) = \(λ^2\) ∫e^(-λz) dx
\(f_Z\)(z) = \(λ^2\) e^(-λz) ∫ dx
\(f_Z\)(z) = \(λ^2\) e^(-λz) [x] + C
Since Z is a non-negative random variable, the range of integration is from 0 to infinity.
Therefore, we evaluate the integral with the limits:
\(f_Z\)(z) = λ^2 e^(-λz) [0 to ∞]
As x approaches infinity, the value of \(e^(-λx)\) goes to 0.
Therefore, the upper limit of the integral contributes 0 to the result.
\(f_Z\)(z) = \(λ^2\) e^(-λz) [0]
\(f_Z(z) = 0\)
Hence, the PDF of Z is given by:
\(f_Z(z) = 0 for z < 0\)
This means that Z follows a degenerate distribution, concentrated at zero.
The sum of independent exponential random variables with the same parameter λ is always a degenerate random variable with zero probability density except at zero.
Learn more about probability density function from this link:
https://brainly.com/question/31039386
#SPJ11