what is the mean of 76,88,100,75,95,100
Answers
Answer:89
Step-by-step explanation:add them all together and divide by however many numbers you have
Answer:
Hello, Hope your having a good day
Step-by-step explanation:
your Question; what is the mean of 76,88,100,75,95,100
The mean is 89
Median: 91.5
Mode: 100
What is a mean?
The mean of a data set is commonly known as the average. You find the mean by taking the sum of all the data values and dividing that sum by the total number of data values.
Hope this helped :)
pls like
Related Questions
The box that the kite came in is a rectangular prism with dimensions of 21/2” x 9 1/2” x 2”
Answers
The volume of the box is given as follows:
V = 199.5 in³.
How to obtain the volume of a rectangular prism?The volume of a rectangular prism, with dimensions length, width and height, is given by the multiplication of these dimensions, according to the equation presented as follows:
Volume = length x width x height.
The dimensions for this problem, in inches, are given as follows:
10.5, 9.5 and 2.
Hence the volume of the box is given as follows:
V = 10.5 x 9.5 x 2
V = 199.5 in³.
Missing InformationThe problem asks for the volume of the box.
More can be learned about the volume of a rectangular prism at brainly.com/question/22070273
#SPJ1
Noah, Preston, and Zach run a broken mechanical pencil disposal service. Noah works 2 hours more than Preston, and Zach works 4 hours less than twice the amount Preston does. If they work 94 hours total, how many hours does each of them work?
Answers
Noah, Preston, and Zach work for 26 hours, 24 hours and 44 hours respectively
How to determine how many hours each of them works?
A word problem is a mathematical exercise where significant background information on the problem is presented in ordinary language rather than in mathematical notation.
Let N, P and Z represent the number of hours Noah, Preston, and Zach work respectively. Thus, we can write:
N = P + 2 ---- (1)
Z = 2P - 4 ---- (2)
N + P + Z = 94 ---- (3)
Put (1) and (2) in (3):
N + P + Z = 94
P+2 + P + 2P-4 = 94
4P -2 = 94
4P = 94 + 2
4P = 96
P = 96/4
P = 24
Since N = P + 2,
N = 24 + 2 = 26
Since Z = 2P - 4,
Z = 2(24) - 4 = 44
Learn more about word problems on:
brainly.com/question/1781657
#SPJ1
What value of n makes the equation n/3 - 2 = 4 true?
Show your work.
Answers
Answer:
Step-by-step explanation:
n/3 - 2 = 4 Add 2 to both sides
n/3 - 2 + 2 = 4+2 Combine
n/3 = 6 Multiply both sides by 3
3*n/3 = 6 * 3
n = 18
Which of the following lists of ordered pairs is a function? A. (2,5), (3, 6), (6, 9) B. (-1,2), (2, 3), (3, 1), (2,5) C. (1,2), (4,0), (3,5),(4,3) D. (2,5), (3, 6), (2, 1)
Answers
Answer:
A. (2,5), (3,6), (6,9)
Step-by-step explanation:
In order to be a function, all inputs (x values) must go to only one output (y value). List A is the only list that obeys this rule. Therefore, List A is a function.
Find the value of x in the triangle at 36° x° x° the right.
Answers
The required measure of the angle x is 72° in the triangle.
Given that,
The value of x in the triangle at 36°, x°, and x° is to be determined.
The triangle is a geometric shape that includes 3 sides and the sum of the interior angle should not be greater than 180°
Here,
For the triangle sum of the internal angle is 180°,
36 + x + x = 180
2x = 144
x = 72°
Thus, the required measure of the angle x is 72° in the triangle.
Learn more about triangles here:
https://brainly.com/question/2773823
#SPJ1
Geometry: Help with assignment

Answers
The solution of A ∪ B for their set of data that can be derived using a Venn diagram is A ∪ B = {0, 1, 2, 3, 4, 5}, which makes option C correct.
What is Venn diagramVenn diagrams are commonly used in mathematics, statistics, and logic to illustrate relationships between sets of data. It consists of circles that overlap to show the similarities and differences between the sets like in the case of students data.
A ∪ B is read as A union B, which implies the set of all datas in set A and set B without repeating any data.
Given that set A = {0, 1, 2, 3, 4} and B = {1, 3, 5}
All data of set A and B are: 0, 1, 2, 3, 4, 5
so;
A ∪ B = {0, 1, 2, 3, 4, 5}
Therefore, the solution of A ∪ B that can be derived using a Venn diagram is A ∪ B = {0, 1, 2, 3, 4, 5}
Read more about venn here:https://brainly.com/question/24713052
#SPJ1
what’s this
hdhshxbbsncjdkckskxbsh

Answers
Answer:
i dunno what that means but i think maybe your keyboard broke so the type of letters is random??
-14 = -8m + 2
please help!
Answers
The height of the probability density function f(x) of the uniform distribution defined on the interval [a, b] is 1/(a-b). True False
Answers
The statement "The height of the probability density function f(x) of the uniform distribution defined on the interval [a, b] is 1/(a-b)" is False.
In a uniform distribution, the probability density function (PDF) is constant within the interval [a, b]. The height of the PDF represents the density of the probability distribution at any given point within the interval. Since the PDF is constant, the height remains the same throughout the interval.
To determine the height of the PDF, we need to consider the interval length. In a uniform distribution defined on the interval [a, b], the height of the PDF is 1/(b - a) for the PDF to integrate to 1 over the entire interval. This means that the total area under the PDF curve is equal to 1, representing the total probability within the interval [a, b].
Therefore, the correct statement is that the height of the probability density function f(x) of the uniform distribution defined on the interval [a, b] is not 1/(a - b), but rather it is a constant value necessary for the PDF to integrate to 1 over the interval, i.e., 1/(b - a).
Learn more about uniform distribution here:
https://brainly.com/question/32291215
#SPJ11
Which fraction is equivalent to 2/6?
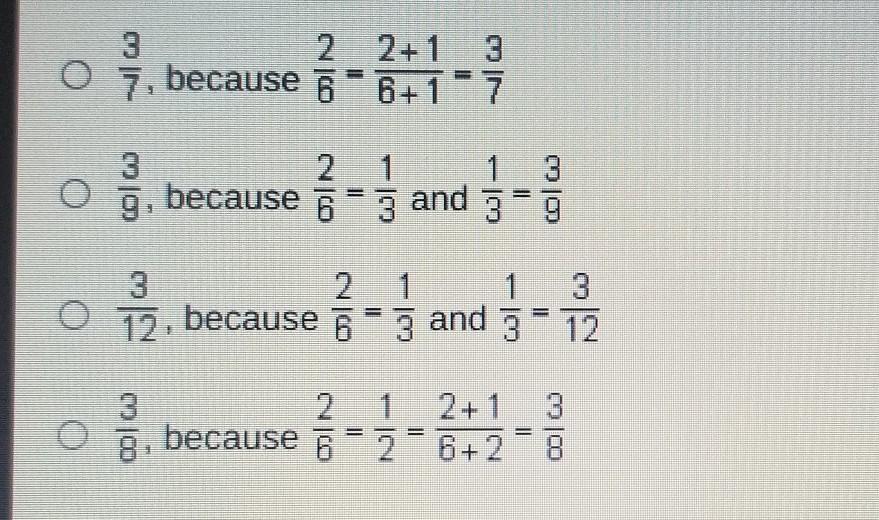
Answers
Answer:
1/3, 2/6, 3/9, 4/12
Step-by-step explanation:
Answer:
b
Step-by-step explanation:
if you simlpify 2/6 you would get one third times that by three its 3 ninths
explain the solution in details
"f(x)=ln(x−1/3x^2−2)⇒f′(x)=
Answers
The derivative of f(x) = ln(x - 1/3*x^2 - 2) is 1/(x - 1/3*x^2 - 2). This can be found using the quotient rule, which states that the derivative of f(x)/g(x) is (g(x)*f'(x) - f(x)*g'(x)) / g^2(x). In this case, f(x) = ln(x) and g(x) = x - 1/3*x^2 - 2.
The quotient rule can be used to find the derivative of any function that is the quotient of two other functions. In this case, f(x) = ln(x) and g(x) = x - 1/3*x^2 - 2. To use the quotient rule, we need to find the derivatives of f(x) and g(x). The derivative of f(x) is 1/x, and the derivative of g(x) is 1 - 2x.
Plugging these derivatives into the quotient rule, we get:
```
f'(x) = (g(x)*f'(x) - f(x)*g'(x)) / g^2(x)
= (x - 1/3*x^2 - 2)*(1/x) - ln(x)*(1 - 2x) / (x - 1/3*x^2 - 2)^2
= 1/(x - 1/3*x^2 - 2)
```
This is the derivative of f(x).
Learn more about quotient rule here:
brainly.com/question/30278964
#SPJ11
the slope of a fairly flat upward-sloping line will be a a. large negative number. b. small negative number. c. small positive number. d. large positive number.
Answers
The slope of a fairly flat upward-sloping line will be a small positive number. (option c)
This is because a slope measures the change in the y value for a given change in the x value. As the line is fairly flat, the change in y value will be small. Since the line is upward-sloping, the change in the y value will be positive. Therefore, the slope of the line will be a small positive number.
To calculate the slope mathematically, we can use the formula
m = (y2-y1)/(x2-x1).This formula gives us the slope of the line between two points (x1, y1) and (x2, y2). In our case, since the line is fairly flat, the difference in y values (y2-y1) will be small, resulting in a small positive number for the slope.
We can also visualize this mathematically. If we graphed the line, it would look like a flat line, because the difference in y values is small. Therefore, the slope of the line will be a small positive number.
Learn more about Slope:
https://brainly.com/question/16949303
#SPJ4
A store orders a batch of 2000 flashlights. The odds that a flashlight is defective are 0.15%. Let X be the number of defective flashlights in the batch. (a) What is the distribution of X? What is/ are the value(s) of the paramter(s) of this distribution? (b) What are expected value and standard deviation of X? (c) What is the probability that the batch contains no defective flashlights? One defective flashlight? More than two defective ones?
Answers
X follows a binomial distribution with n = 2000 and p = 0.0015. The chance that the batch contains no faulty flashlights is 0.8805 percent. The likelihood of one faulty flashlight in the batch is 1.5307. X has a standard deviation of 1.0708. The likelihood of more than two faulty flashlights in the batch is 0.0388.
What is probability?Probability is an area of mathematics that deals with numerical representations of how probable an event is to occur or how likely a statement is to be true. The probability of an occurrence is a number between 0 and 1, where 0 denotes the event's impossibility and 1 represents certainty.
Here,
(a) X has a binomial distribution with parameters n = 2000 and p = 0.0015. The binomial distribution is a discrete probability distribution that describes the number of successes in n independent Bernoulli trials, each with success probability p.
(b) The expected value (mean) of X is given by E(X) = n * p = 2000 * 0.0015 = 3. The standard deviation of X is given by sqrt(n * p * (1 - p)) = sqrt(2000 * 0.0015 * 0.9985) = 1.0708.
(c) The probability that the batch contains no defective flashlights is given by P(X = 0) = (2000 choose 0) * 0.0015^0 * (0.9985)^2000 = 0.8805. The probability that the batch contains one defective flashlight is given by P(X = 1) = (2000 choose 1) * 0.0015^1 * (0.9985)^1999 = 1.5307. The probability that the batch contains more than two defective flashlights is given by P(X > 2) = 1 - P(X <= 2) = 1 - P(X = 0) - P(X = 1) - P(X = 2) = 0.0388.
X has a binomial distribution with parameters n = 2000 and p = 0.0015. The probability that the batch contains no defective flashlights is 0.8805.The probability that the batch contains one defective flashlight is 1.5307. The standard deviation of X is 1.0708. The probability that the batch contains more than two defective flashlights is 0.0388.
To know more about probability,
https://brainly.com/question/30034780
#SPJ4
Find the measure of angle KMU

Answers
Answer:
140°
Step-by-step explanation:
The other angle inside is 40 so 180-40 is 140°
The measure of the angle KMU is 140 degrees.
What is an angle?It is formed by two rays or lines that share a common endpoint.
Given that for the triangle KLM, angle KLM is 90° and angle LKM is 50°.
The sum of the angles inside the triangle is 180°.
The angle KML is given by
angle KML = 180-(90+50) = 180 - 140 = 40
The angle KMU = 180 - 40= 140.
Hence the 140° is the measure of the angle KMU.
To learn more about angle, use the link given below:
https://brainly.com/question/17039091
#SPJ2
Please Solve:
x^2-4x-5=0
Answers
The standard error of the mean (also known as the standard deviation of the sampling distribution of the sample mean)
measures the variability of the mean from sample to sample.
is never larger than the standard deviation of the population.
decreases as the sample size increases.
All of these choices are true.
Answers
All of these choices are true. The standard error of the mean is a measure of how much the sample mean varies from sample to sample.
. As the sample size increases, the standard error of the mean decreases. This is because larger sample sizes give us more information about the population and make our estimates more accurate. However, the standard error of the mean is not larger than the standard deviation of the population. In fact, it is typically smaller than the standard deviation of the population, which is why we use it to estimate the population mean. In conclusion, the standard error of the mean is an important concept in statistics that helps us understand the variability of sample means and how accurate our estimates of the population mean are likely to be.
The standard error of the mean is a statistical measure that tells us how much the sample mean is likely to vary from sample to sample. It is the standard deviation of the sampling distribution of the sample mean. The sampling distribution is the distribution of all possible sample means that we could obtain by taking repeated samples from the same population. The standard error of the mean is calculated by dividing the standard deviation of the population by the square root of the sample size.
One important thing to note is that the standard error of the mean decreases as the sample size increases. This is because larger sample sizes give us more information about the population and make our estimates more accurate. When the sample size is small, there is a greater chance that the sample mean will be significantly different from the population mean. However, as the sample size increases, the sample mean becomes a more accurate estimate of the population mean, and the standard error of the mean decreases.
It is also important to note that the standard error of the mean is never larger than the standard deviation of the population. The standard deviation of the population is a measure of how much the individual data points vary from the population mean. The standard error of the mean is a measure of how much the sample mean varies from sample to sample. It is typically smaller than the standard deviation of the population because the sample mean is usually closer to the population mean than any individual data point.
In conclusion, the standard error of the mean is an important concept in statistics that helps us understand the variability of sample means and how accurate our estimates of the population mean are likely to be. As the sample size increases, the standard error of the mean decreases, making our estimates more accurate. However, the standard error of the mean is never larger than the standard deviation of the population, which is a measure of the variability of individual data points.
To know more about standard error visit:
brainly.com/question/14524236
#SPJ11
many elementary school students in a school district currently have ear infections. a random sample of children in two different schools found that 11 of 40 at one school and 12 of 30 at the other have ear infections. at the 0.05 level of significance, is there sufficient evidence to support the claim that a difference exists between the proportions of students who have ear infections at the two schools?
Answers
Since the p-value is greater than the significance level of 0.05, we fail to reject the null hypothesis. Therefore, there is not sufficient evidence to support the claim that a difference exists between the proportions of students who have ear infections at the two schools.
To determine if there is sufficient evidence to support the claim that a difference exists between the proportions of students who have ear infections at the two schools, we can use a two-sample z-test for the difference in proportions.
The null hypothesis is that there is no difference between the proportions of students with ear infections at the two schools, while the alternative hypothesis is that there is a difference.
Let p1 be the proportion of students with ear infections at the first school and p2 be the proportion at the second school. The test statistic is given by:
z = (p1 - p2) / sqrt(p_hat * (1 - p_hat) * (1/n1 + 1/n2))
where p_hat is the pooled proportion, n1 and n2 are the sample sizes from the first and second schools, respectively.
The pooled proportion is given by:
p_hat = (x1 + x2) / (n1 + n2)
where x1 and x2 are the number of students with ear infections in each school.
Using the given data, we have:
n1 = 40, n2 = 30
x1 = 11, x2 = 12
p1 = x1/n1 = 11/40 = 0.275
p2 = x2/n2 = 12/30 = 0.4
p_hat = (x1 + x2) / (n1 + n2) = (11 + 12) / (40 + 30) = 0.355
The test statistic is:
z = (0.275 - 0.4) / sqrt(0.355 * 0.645 * (1/40 + 1/30)) = -1.197
Using a standard normal table or calculator, the p-value for a two-tailed test with a test statistic of -1.197 is approximately 0.231.
To know more about null hypothesis,
https://brainly.com/question/17157597
#SPJ11
How many seconds are in 4.98 minutes? Round your answer to the nearest tenth (to one decimal point)
Answers
Answer: 298.8 seconds
Step-by-step explanation: 4.98*60=298.8
Answer:
298.8
Step-by-step explanation:
4.98x60=298.8 so you have been understand
Please explain how to solve these equations.
m+j=58
11m+10j
Answers
I’m going to solve for m
M+J=58 (Subtract J on both sides)
M=58+J
Now substitute for M in the second equation.
11(58+j)+10j
638 + 11j + 10j
638 + 21j
Given: ABCD is a parallelogram and A ABC = ADCB.
Prove: AB I BC.
somebody pls tell me what step 4 is and the reason

Answers
Answer:
Step-by-step explanation:
Angle ABC is a right angle because all interior angles of a rectangle are right angles.
Find the difference: (y^2-4y+9)-(3y^2-6y-9)
Answers
Answer:
-2y² + 2y + 18-----------------------
Solve in steps:
(y² - 4y + 9) - (3y² - 6y - 9) = Open parenthesisy² - 4y + 9 - 3y² + 6y + 9 = Group like terms(y² - 3y²) + (- 4y + 6y) + (9 + 9) = Simplify-2y² + 2y + 18 AnswerThe difference of the polynomial expression (y^2 - 4y + 9) - (3y^2 - 6y - 9) is -2y^2 + 2y + 18.
How to Find the Difference of Polynomial Expressions?To find the difference of the polynomial expression (y² - 4y + 9) - (3y² - 6y - 9), we need to distribute the negative sign to every term within the parentheses:
= y² - 4y + 9 - 3y² + 6y + 9
Next, let's combine like terms by adding or subtracting coefficients of similar variables:
= (y² - 3y²) + (-4y + 6y) + (9 + 9)
Simplifying the expression further, we have:
= -2y^2 + 2y + 18
Thus, the difference is: -2y^2 + 2y + 18
Learn more about Difference of Polynomial Expressions on:
https://brainly.com/question/30194245
#SPJ1
Find the measure of the indicated angle to
the nearest degree! please help

Answers
Answer:
A 54°
Step-by-step explanation:
Sorry if its wrong <3
PLS HELP ASAPP I WILL GIVE BRAINLEST ALL MY POINTS
An expression is shown below:
4m3 + 12xm2 − 8m2 − 24xm
Part A: Rewrite the expression by factoring out the greatest common factor. (4 points)
Part B: Factor the entire expression completely. Show the steps of your work. (6 points)
Answers
The greatest common factor of 4m³ + 12xm² - 8m² - 24xm is 4m. The factorization gives 4m(m + 3x)(m - 2)
What is an equation?An equation is an expression that shows the relationship between two or more numbers and variables.
An independent variable is a variable that does not depends on other variable while a dependent variable is a variable that depends on other variable.
Given the equation:
4m³ + 12xm² - 8m² - 24xm
The greatest common factor is 4m, hence:
= 4m(m² + 3xm - 2m - 6x)
= 4m(m(m - 2) + 3x(x - 2))
= 4m(m + 3x)(m - 2)
The greatest common factor of 4m³ + 12xm² - 8m² - 24xm is 4m. The factorization gives 4m(m + 3x)(m - 2)
Find out more on equation at: https://brainly.com/question/2972832
#SPJ1
2x34x56
im in -8ht garde and me no know multipcacion pls hulp
Answers
Answer:
Step-by-step explanation:
3,808
Answer: 3808
Step-by-step explanation:
2 times 34 = 68
68 times 56 = 3808
Answer is 3808
You start at (8, 2). You move down 2 units. Where do you end
Answers
Answer:
(6, 2)
Step-by-step explanation:
I did this over 10 times it's so easy it is like a breeze
Answer:(-2,5)
Step-by-step explanation:
1 and 2 is all I need and you guys would help me from not getting beat

Answers
Answer:
1. -10
2. -11
Step-by-step explanation:
Si 60 personas representan el 25% del total de espectadores que fueron a un evento, ¿Cuántas personas representan el 100%?
3 puntos
Answers
Answer:
240 people
Step-by-step explanation:
\(\frac{60}{25} =\frac{x}{100}\) (x represents people)
60×100= 6000 , 25 × \(x\) = 25\(x\)
\(\frac{25x}{25x}=x\) \(\frac{6000}{25x} = 240\)
x=240
If the same condition is described as both acute (subacute) and chronic, and separate subentries exist in the Index at the same indentation level, code_____.
Answers
If the same condition is described as both, as separate subentries exist in the Index at the same indentation level, code both the acute/subacute and chronic codes.
When a condition is described as both acute and chronic, and separate subentries for each descriptor exist in the Index, it is appropriate to code both the acute/subacute and chronic codes. This is because the two descriptors refer to different stages or phases of the same condition. For example, a patient may have both acute and chronic bronchitis, with the acute exacerbations superimposed on a chronic underlying condition.
In such cases, it is important to capture both aspects of the condition to ensure accurate documentation and appropriate reimbursement for healthcare services provided. Therefore, coders should consult the guidelines and the Index to Diseases and Injuries to determine which codes are appropriate for reporting.
For more questions like Chronic Code visit the link below:
https://brainly.com/question/30038725
#SPJ11
the region bounded by the parabolas r=t,4t2 and r=t,45−t2, for −3≤t≤3 question content area bottom part 1 set up the line integral for the boundary. since both curves use the same parameter range, the two integrals can be combined into one
Answers
The region bounded by the parabolas r=t,4t2 and r=t,45−t2, for −3≤t≤3 question content area bottom part 1 set up the line integral for the boundary
the combined parameterization of the boundary curves, f(x, y) represents the function being integrated, and ds represents the differential arc length.
To set up the line integral for the boundary of the region bounded by the parabolas, we need to parameterize the curves. Let's go through the process step by step.
1. Parameterize the curves:
For the curve r = t, 4t^2, we can parameterize it as:
x = t
y = 4t^2
For the curve r = t, 45 - t^2, we can parameterize it as:
x = t
y = 45 - t^2
2. Determine the limits of the parameter:
In this case, the parameter t ranges from -3 to 3 as given in the question: -3 ≤ t ≤ 3.
3. Combine the parameterizations:
Since both curves use the same parameter range, we can combine them into a single parameterization.
Let's call the combined parameterization (x(t), y(t)):
x(t) = t
y(t) = 4t^2 for -3 ≤ t ≤ 3
y(t) = 45 - t^2 for -3 ≤ t ≤ 3
4. Set up the line integral:
The line integral for the boundary of the region can be represented as:
∮C f(x, y) ds
where C represents the combined parameterization of the boundary curves, f(x, y) represents the function being integrated, and ds represents the differential arc length.
To know more about parabolas refer here:
https://brainly.com/question/11911877#
#SPJ11
The number of pieces of cat food in a one-cup scoop is approximately Normally distributed with a mean of 344 pieces and a standard deviation of 16 pieces. If a random sample of 28 scoops of cat food is selected, what is the probability that the mean number of pieces will be more than 350 pieces? 0.0236 0.3538 0.6462 0.9764
Answers
Answer:
0.0236
Step-by-step explanation:
took the quiz