what time is it 5 3/4 hours after 11:32pm
Answers
Answer:
So the time is 5:17 am
Related Questions
15 POINTS!!! (16*4^3*8^8)^5 Find the answer and show work how you got it
Answers
Answer:
2^170
Step-by-step explanation:
(16 x 4^3 x 8^8)^ 5
- start by converting it all to a common base
(2^4 x 2^3 x 2^24)^5
- calculate the product, by adding all the powers
(2^34)^5
= 2^170
If 1 can of ketchup contains 13 cups, how many are there in 3.5 cans
Answers
Answer:19.5
Step-by-step explanation:
Answer:
Step-by-step explanation:
Answer: 45.5
Step 1: 13 cups x 3.5 can = 45.5 cups
Rajan brought a book for Rs 180 and sold it to sajan at a profit of 20%. Sajan sold that book to Nirajan at a loss of20%. At what price Nirajan should sell the book to receive 5% profit.
Answers
Answer:
Ans: Rs 181.44.
Step-by-step explanation:
CAN SOMEONE PLEASE HELP ME I'M LITERALLY CRYING RIGHT NOW.

Answers
Answer:
I'm sorry this is hard, what grade is this?
Step-by-step explanation:
Find an equation of the tangent line at the given value of x. y= 0∫x sin(2t2+π2),x=0 y= ___
Answers
The equation of the tangent line at x=0 is y = x.
To find the equation of the tangent line at the given value of x, we need to find the derivative of the function y with respect to x and evaluate it at x=0.
Taking the derivative of y=∫[0 to x] sin(2t^2+π/2) dt using the Fundamental Theorem of Calculus, we get:
dy/dx = sin(2x^2+π/2)
Now we can evaluate this derivative at x=0:
dy/dx |x=0 = sin(2(0)^2+π/2)
= sin(π/2)
= 1
So, the slope of the tangent line at x=0 is 1.
To find the equation of the tangent line, we also need a point on the line. In this case, the point is (0, y(x=0)).
Substituting x=0 into the original function y=∫[0 to x] sin(2t^2+π/2) dt, we get:
y(x=0) = ∫[0 to 0] sin(2t^2+π/2) dt
= 0
Therefore, the point on the tangent line is (0, 0).
Using the point-slope form of a linear equation, we can write the equation of the tangent line:
y - y1 = m(x - x1)
where m is the slope and (x1, y1) is a point on the line.
Plugging in the values, we have:
y - 0 = 1(x - 0)
Simplifying, we get:
y = x
So, the equation of the tangent line at x=0 is y = x.
Learn more about Fundamental Theorem of Calculus here:
brainly.com/question/30761130
#SPJ11
Force f acts between a pair of charges, q1 and q2, separated by a distance d. for each of the statements, use the drop-down menus to express the new force in terms of f. q1 is halved, q2 is doubled, but the distance between the charges remains d. q1 and q2 are unchanged. the distance between the charges is doubled to 2d. q1 is doubled and q2 is tripled. the distance between the charges remains d.
Answers
The initial force between the two charges is given by:
\(F=k\frac{q_{1} q_{2} }{d^2}\)
where k is Coulomb's constant, q1 and q2 are the two charges, and d is their separation. Let's analyze now the other situations:
1. F
In this case, q1 is halved, q2 is doubled, but the distance between the charges remains d.
So, we have:
q'₁=q₁/2
q'₂=2q₂
d'=d
So, the new force is:
\(F'=k\frac{q'_{1}q'_{2} }{d^2} \\\\F'=k\frac{(\frac{q_{1} }{2})(\frac{q_{2} }{2}) }{d^2} \\\\F'=k\frac{q_{1}q_{2} }{d^2} =F\)
So the force has not changed.
2. F/4
In this case, q1 and q2 are unchanged. The distance between the charges is doubled to 2d.
So, we have:
q'₁=q₁
q'₂=q₂
d'=2d
So, the new force is:
\(\\F'=k\frac{q'_{1} q'_{2} }{d^2} \\\\F'=k\frac{q_{1}q_{2} }{2d^2} \\\\F'=\frac{1}{4} k\frac{q_{1}q_{2} }{d^2} \\\\F'=\frac{F}{4}\)
So the force has decreased by a factor of 4.
3. 6F
In this case, q1 is doubled and q2 is tripled. The distance between the charges remains d.
So, we have:
q'₁=2q₁
q'₂=3q₂
d'=d
So, the new force is:
\(F'=k\frac{q'_{1} q'_{2} }{d^2} \\\\F'=k\frac{2q_{1}3q_{2} }{d^2}\\ \\F'=6k\frac{q_{1}q_{2} }{d^2} =6F\)
So the force has increased by a factor of 6.
To know more about the distance between charges:
https://brainly.com/question/12288272
#SPJ4
Answer:
1. F
2. F/4
3. 6F
Explain:
10 to the 3rd power
Answers
Answer:
1000
Step-by-step explanation:
just trust me <3
Graph the function.
h(x) = -1/5x^2+2x
Answers
Answer:
Hello there I would love to assist but could you give me a little more info I think I know the answer but I want to make sure I got it 100% correct unless you cant give me more info ill just tell you what I think it is but if u can give me more info before I give u the answer to make sure its correct would be appreciated
Step-by-step explanation:
Use the model to answer this question. 2/5x1/4 ?
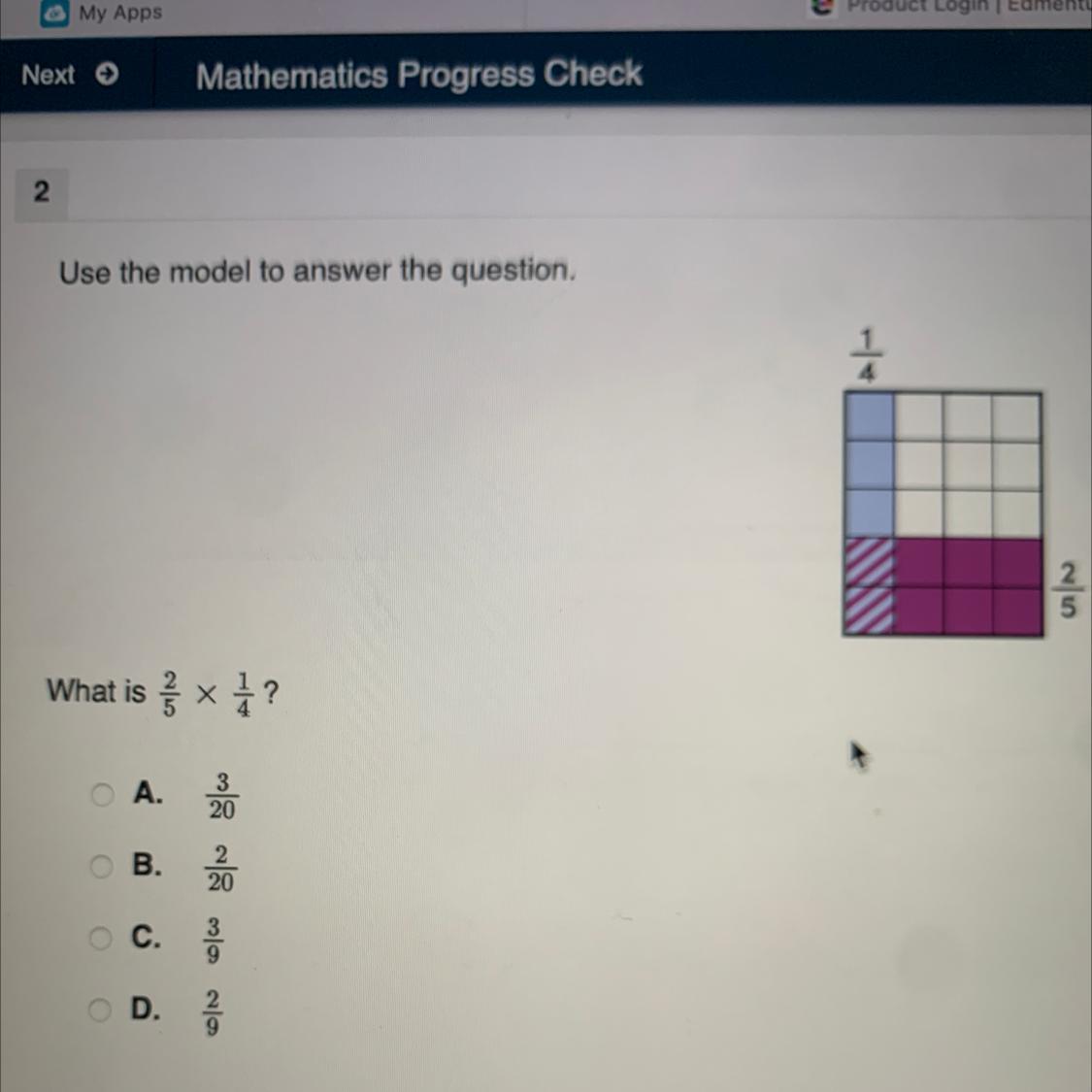
Answers
Find all the numbers that are power of 2 (such as 4, 8, 16, etc.) using a while loop. The numbers found should be less than or equal to 5000. Print all the numbers out. The numbers displayed should be exactly like the following in one line:
2 4 8 16 32 64 128 256 512 1024 2048 4096
Answers
This programming question requires you to use a while loop in a programming language to determine all the powers of two numbers that are less than or equal to 5000. All of the numbers should be separated by a space in the output, which should be written on a single line. The power of two numbers are ones that may be stated as 2 to the power of an integer, such as 2, 4, 8, 16, 32, and so on.
The python program is as follows:
num = 1
while num <= 5000:
if (num & (num - 1)) == 0:
print(num, end=" ")
num = num * 2
This program will use a while loop to find all the numbers that are the power of 2 less than or equal to 5000 and print them out, exactly like the following in one line: 2 4 8 16 32 64 128 256 512 1024 2048 4096.
Learn more about programming:
https://brainly.com/question/26497128
#SPJ11
An online furniture store sells chairs for $150 each and tables for $650 each. Every day, the store can ship at most 16 pieces of furniture and must sell no less than $3900 worth of chairs and tables. If x represents the number of tables sold and y represents the number of chairs sold, write and solve a system of inequalities graphically and determine one possible solution.
Answers
Using graphical method to solve the system of linear inequalities, the solution are (x, y) 3, 13.
System of Linear InequalitiesA system of linear inequalities in two variables consists of at least two linear inequalities in the same variables. The solution of a linear inequality is the ordered pair that is a solution to all inequalities in the system and the graph of the linear inequality is the graph of all solutions of the system.
To solve this, we can write out the equations as
x + y ≤ 16 ...eq(i)
650x + 150y ≥ 3900 ...eq(ii)
Solving both equations with a graph.
Kindly find the attached graph to the problem.
Learn more on graph of linear inequality here;
https://brainly.com/question/25839052
#SPJ1

HELP PLS!!!
Find the surface area of the pyramid.

Answers
well, the hexagonal pyramid is really just six triangles with a base of 24 and a height of 24 as well, and a hexagonal base with an apothem of 12√3 and sides of 24.
\(\textit{area of a regular polygon}\\\\ A=\cfrac{1}{2}ap ~~ \begin{cases} a=apothem\\ p=perimeter\\[-0.5em] \hrulefill\\ a=12\sqrt{3}\\ p=\stackrel{(24)(6)}{144} \end{cases}\implies A=\cfrac{1}{2}(12\sqrt{3})(144) \\\\[-0.35em] ~\dotfill\\\\ \stackrel{ \textit{\LARGE Areas} }{\stackrel{\textit{six triangles}}{6\left[ \cfrac{1}{2}(\underset{b}{24})(\underset{h}{24}) \right]}~~ + ~~\stackrel{\textit{hexagonal base}}{\cfrac{1}{2}(12\sqrt{3})(144)}}\implies 1728+864\sqrt{3} ~~ \approx ~~ \text{\LARGE 3224}~m^2\)
the standard deviation of a point estimator is called the question 8 options: standard deviation. standard error. point estimator. variance of estimation.
Answers
The standard deviation of a point estimator is called the "standard error
What is standard deviation ?
Standard deviation is a statistical measure that describes the amount of variation or dispersion in a set of data. It is the square root of the variance, which is the average of the squared differences from the mean. A high standard deviation indicates that the data points are spread out over a wider range, while a low standard deviation indicates that the data points are clustered closer together. Standard deviation is commonly used in fields such as finance, engineering, and science to describe the variability of data and to make statistical inferences about a population based on a sample.
To calculate the standard deviation of a set of data, you can follow these steps:
Find the mean (average) of the data set.
For each data point, subtract the mean and square the result.
Sum the squared differences from step 2.
Divide the sum from step 3 by the number of data points minus one (this is called the sample variance).
Take the square root of the sample variance to get the standard deviation.
Here's an example using a set of data: 4, 6, 8, 10, 12
Find the mean: (4 + 6 + 8 + 10 + 12) / 5 = 8
For each data point, subtract the mean and square the result:
(4 - 8)² = 16
(6 - 8)²= 4
(8 - 8)² = 0
(10 - 8)² = 4
(12 - 8)² = 16
Sum the squared differences: 16 + 4 + 0 + 4 + 16 = 40
Divide by the number of data points minus one: 40 / 4 = 10 (sample variance)
Take the square root of the sample variance: sqrt(10) = approximately 3.16
Therefore, the standard deviation of the data set is approximately 3.16.
and The standard deviation of a point estimator is called the "standard error
To know more about standard deviation visit :-
https://brainly.com/question/475676
#SPJ1
ewton's law of cooling states that the temperature of an object changes at a rate proportional to the difference between its temperature and that of its surroundings. suppose that the temperature of a cup of coffee obeys newton's law of cooling. if the coffee has a temperature of 200 200 degrees fahrenheit when freshly poured, and 2 2 minutes later has cooled to 188 188 degrees in a room at 80 80 degrees, determine when the coffee reaches a temperature of 143 143 degrees. the coffee will reach a temperature of 143 143 degrees in
Answers
The coffee will reach a temperature of 143 degrees Fahrenheit in approximately 18.67 minutes.
Newton's law of cooling states that the rate of cooling of an object is proportional to the temperature difference between the object and its surroundings. Mathematically, we can write this as:
dT/dt = -k(T - T_s)
where dT/dt is the rate of change of temperature with respect to time, T is the temperature of the object, T_s is the temperature of the surroundings, and k is a constant of proportionality.
In this problem, we are given that the coffee has a temperature of 200 degrees Fahrenheit when freshly poured and cools to 188 degrees Fahrenheit after 2 minutes in a room at 80 degrees Fahrenheit. Let's call the time at which the coffee reaches a temperature of 143 degrees Fahrenheit as t.
Using Newton's law of cooling, we can set up an equation as:
(dT/dt) = -k(T - T_s)
Integrating both sides, we get:
ln(T - T_s) = -kt + C
where C is a constant of integration.
Using the initial conditions, we can solve for C:
ln(200 - 80) = -k(0) + C
C = ln(120)
So the equation becomes:
ln(T - 80) = -kt + ln(120)
Now we can use the fact that the temperature of the coffee has cooled to 188 degrees Fahrenheit after 2 minutes to find the value of k:
ln(188 - 80) = -k(2) + ln(120)
k = (ln(120) - ln(108)) / 2
k ≈ 0.0776
Now we can solve for the time t when the coffee reaches a temperature of 143 degrees Fahrenheit:
ln(143 - 80) = -0.0776t + ln(120)
t ≈ 18.67 minutes
Therefore, the coffee will reach a temperature of 143 degrees Fahrenheit in approximately 18.67 minutes.
Learn more about Newton's law of cooling states here https://brainly.com/question/16244959
#SPJ4
19) Consider The Model Yi=B0+B1Xi+B2Ziui, If You Know The Variance Of Ui Is Σi2=Σ2zi2 How Would You Estimate The Regression?
Answers
To estimate the regression in the given model Yi = B0 + B1Xi + B2Ziui, where the variance of Ui is Σi^2 = Σ(zi^2), you can use the method of weighted least squares (WLS). The weights for each observation can be determined by the inverse of the variance of Ui, that is, wi = 1/zi^2.
In the given model, Yi = B0 + B1Xi + B2Ziui, the error term Ui is assumed to have a constant variance, given by Σi^2 = Σ(zi^2), where zi represents the individual values of Z.
To estimate the regression coefficients B0, B1, and B2, you can use the weighted least squares (WLS) method. WLS is an extension of the ordinary least squares (OLS) method that accounts for heteroscedasticity in the error term.
In WLS, you assign weights to each observation based on the inverse of its variance. In this case, the weight for each observation i would be wi = 1/zi^2, where zi^2 represents the variance of Ui for that particular observation.
By assigning higher weights to observations with smaller variance, WLS gives more importance to those observations that are more precise and have smaller errors. This weighting scheme helps in obtaining more efficient and unbiased estimates of the regression coefficients.
Once you have calculated the weights for each observation, you can use the WLS method to estimate the regression coefficients B0, B1, and B2 by minimizing the weighted sum of squared residuals. This involves finding the values of B0, B1, and B2 that minimize the expression Σ[wi * (Yi - B0 - B1Xi - B2Ziui)^2].
By using the weights derived from the inverse of the variance of Ui, WLS allows you to estimate the regression in the presence of heteroscedasticity, leading to more accurate and robust results.
Learn more about variance here: brainly.com/question/31432390
#SPJ11
$350 at 3 1/2% for 3 years
2
Answers
Answer:
The answer is
Step-by-step explanation:
principal = 100× I/R×T
=100×350/7/2×3
if the volume of an orange is 288pl cm2, the what is the radius of the fruit?
Answers
The radius of an orange with a volume of 288 cubic centimeters is approximately 3.81 cm.
To find the radius of the orange, we need to use the formula for the volume of a sphere, which is (4/3)πr^3, where r is the radius. In this case, the volume is given as 288 cubic centimeters. We can now solve for the radius:
288 = (4/3)πr^3
First, we need to isolate the r^3 term by dividing both sides of the equation by (4/3)π:
288 / ((4/3)π) = r^3
Now, we can find the cube root of both sides of the equation to solve for r:
r = ∛(288 / ((4/3)π))
r ≈ 3.81 cm
So, the radius of the fruit is approximately 3.81 cm.
know more about volume of a sphere click here:
https://brainly.com/question/16686115
#SPJ11
The blank is the greatest of the common factor of two or more numbers
Answers
Answer:
The greatest common factor (GCF) of a set of numbers is the largest factor that all the numbers share. For example, 12, 20, and 24 have two common factors: 2 and 4. The largest is 4, so we say that the GCF of 12, 20, and 24 is 4. GCF is often used to find common denominators.
What is the measure of angle 1?
Write the answer without the degree.

Answers
Answer: 70
90+20=110
180-110=70
I hope this is good enough:
Answer:
70
Step-by-step explanation:
Everything needs to add up to 180. So you have 90 and 20 you will add them and you’ll get 110. Since you want to find the missing measurement you will subtract 180-110 and you’ll get 70. The missing angle is 70. To check: 90+20+70=180
The equation of line 2 is y = 4x - 7. Find line 1 given that line 1 is parallel to line 2 and has y-intercept (0,2).
PLEASE HELP ASAP
Answers
Answer:
hi! this may all seem confusing but don't worry it's easy once you get it!
so we have a line this line y=4x-7 is what we will use to plugin our point
and (0,2) is your point!
2=4(0)+b
2=b
and usually you don't have to do that (HINT: if it's 0,a number it's already b like the number that isn't 0 is b aka the y intercept)
y=4x + 2 would be the answer!
REMEMBER: Parallel is always the same so you will use the SAME SLOPE!
Well what is the slope? Slope is always mx! you can find it using the slope formula if it is not given, like this equation it was given
If this said PERPENDICULAR then it would be negative reciprocal of your slope and same equation!
hope this helps :)
new question: write an equation of the line that contains the point (1,5) and have the same y-intercept as the line 2x+3y=6
so we need to move this from standard form to slope intercept
2x + 3y=6
-3y= -2x + 6
y= 2/3x - 2
now we've solved! our y intercept is now -2 and slope is 2/3x
okay and now let's plug it in!
again let's plugin our point
5= 2/3 (1) + b
4 1/3= b
so! y= 2/3x - 4 1/3
In the function y=-3x^2+1 what effect does the negative sign have on
the graph, as compared to the graph of Y=x^2 help please
Answers
Answer:
The negative sign in the function will make it a downward-opening parabola, and its vertex will be its highest point.
Answer:
It reflects the graph across x-axis
Step-by-step explanation:
It's a vertical reflection.
Determine the pattern in the table and write the function rule.
Please help asap.

Answers
you need to find how much the output changes for each unit change in the input. (ie from an input change from 5 to 6 the output changes by three units and an input change of 3 (2 - 5 ) units the output changes by 9 units). This will give you the gradient of the equation. then you have to find out the y intercept by finding what the output is when the input is 0. Do this by multiplying the input by the gradient and then subtracting it from that inputs output. This will give you the answer A) 3x
(Sorry, its a bit wordy :) )
Answer
Step-by-step explanation:
this is simple we simply divide saying
6 ÷2=3
15÷5=3
18÷6=3
24÷8=3
33÷11=3
so the pattern is ×3
The t-statistic or t-ratio is used to test the statistical significance overall regression model used to test the statistical significance of each β i used to test to see if an additional variable which has not been observed should be included in the regression model is close to zero when the regression model is statistically significant none of the above
Answers
The correct statement is:
The t-statistic or t-ratio is used to test the statistical significance of each β_i in a regression model.
The t-statistic is calculated by dividing the difference between the sample mean and the hypothesized population mean by the standard error of the sample mean.
The formula for the t-statistic is as follows:
t = (sample mean - hypothesized population mean) / (standard error of the sample mean)
The t-statistic or t-ratio is used to test the statistical significance of each β_i (regression coefficient) in a regression model. It measures the ratio of the estimated coefficient to its standard error and is used to determine if the coefficient is significantly different from zero.
Learn more about t-statistic or t-ratio:
https://brainly.com/question/30466889
#SPJ11
A private and a public university are located in the same city. For the private university, 1046 alumni were surveyed and 643 said that they attended at least one class reunion. For the public university, 804 out of 1315 sampled alumni claimed they have attended at least one class reunion. Is the difference in the sample proportions statistically significant
Answers
Answer:
To find if the difference is statistically significant, we'll find the p-value and compare it to the significance level. If it's smaller, then it's significant.
Because the problem didn't state a specific significance level, I'm going to use the most common one p = 0.05.On a graphing calculator, I conducted a 2-Proportion Z-test. It resulted in zTest_2Prop 643,1046,804,1315,0: stat.results and the p-value is shown as around 0.869485.
Set p₁ ≠ p₂ as we're trying to show that the two proportions are far in value, not whether one is greater/lesser than another.Since 0.869 > 0.05, the difference in the sample proportions is not statistically significant.
Mike used of a cup of vinegar in his salad dressing recipe. He made 3 salad dressing recipes. Between which two whole numbers does the number of cups of vinegar that Mike used lie?
Answers
The number of cups of vinegar that Mike used lies between the whole numbers 2 and 4
If Mike used one cup of vinegar for each salad dressing recipe, then he used a total of 3 cups of vinegar (1 cup x 3 recipes = 3 cups).
However, the question states that he used "a cup of vinegar" in each recipe, which could mean that he used slightly less than one cup, exactly one cup, or slightly more than one cup.
Assuming that Mike used at least 3/4 cup of vinegar in each recipe (which is still close to "a cup"), then he used a minimum of 2 and 1/4 cups of vinegar in total (3/4 cup x 3 recipes = 2 and 1/4 cups).
Assuming that Mike used at most 1 and 1/4 cups of vinegar in each recipe (which is still close to "a cup"), then he used a maximum of 3 and 3/4 cups of vinegar in total (1 and 1/4 cups x 3 recipes = 3 and 3/4 cups).
Learn more about whole numbers here
brainly.com/question/19161857
#SPJ4
Not sure how to do this need it asap thanks <3

Answers
The value of the exponential function is g ( x ) = ( 1/4 )ˣ and the graph is plotted
What are the laws of exponents?When you raise a quotient to a power you raise both the numerator and the denominator to the power. When you raise a number to a zero power you'll always get 1. Negative exponents are the reciprocals of the positive exponents.
The different Laws of exponents are:
mᵃ×mᵇ = mᵃ⁺ᵇ
mᵃ / mᵇ = mᵃ⁻ᵇ
( mᵃ )ᵇ = mᵃᵇ
mᵃ / nᵃ = ( m / n )ᵃ
m⁰ = 1
m⁻ᵃ = ( 1 / mᵃ )
Given data ,
Let the exponential equation be represented as A
Now , the equation will be
Substituting the values in the equation , we get
g ( x ) = ( 1/4 )ˣ
when x = 0
g ( 0 ) = ( 1/4 )⁰
g ( 0 ) = 1
Now , when x = 1
Substitute the value of x = 1 in the equation , we get
g ( 1 ) = ( 1/4 )¹
g ( 1 ) = ( 1/4 )
Now , when x = 2
Substitute the value of x = 2 in the equation , we get
g ( 2 ) = ( 1/4 )²
g ( 2 ) = ( 1/16 )
Now , when x = 3
Substitute the value of x = 3 in the equation , we get
g ( 3 ) = ( 1/4 )³
g ( 3 ) = ( 1/64 )
Now , when x = 4
Substitute the value of x = 1 in the equation , we get
g ( 4 ) = ( 1/4 )⁴
g ( 4 ) = ( 1/256 )
Hence , the equation is g ( x ) = ( 1/4 )ˣ and the graph is plotted
To learn more about exponents click :
https://brainly.com/question/28966438
#SPJ1

Two dice are rolled. What is the probability of having both faces the same (doubles) or a total of 4 ? round to the nearest hundreth.
Answers
When two dice are rolled, the probability of having both faces the same (doubles) or a total of 4 is 0.33 (rounded to the nearest hundredth). The probability of getting a double is 1/6 since there are 6 possible outcomes for the first die and 1 outcome for the second die that will result in a double.
Similarly, the probability of getting a total of 4 is 1/12, since there are three ways to get a total of 4: (1,3), (2,2), and (3,1). Therefore, the probability of getting either doubles or a total of 4 is P(doubles or total of 4) = P(doubles) + P(total of 4) - P(doubles and total of 4)= (1/6) + (1/12) - (1/36)= 0.33 (rounded to the nearest hundredth).
Therefore, the probability of having both faces the same (doubles) or a total of 4 when two dice are rolled is 0.33.
Learn more about probability at https://brainly.com/question/28105230
#SPJ11
Find the value of x. Round your answer to the nearest tenth.

Answers
Answer:20
Step-by-step explanation:
A data set consists of 10 values: 9, 6, 2, 0, 2, 3, 5, 2, 1, 5. Determine the mean. Purchasing agent Angela Rodriguez reported the number of sales calls she received from suppliers on each of the past 14 days. Compute the variance for her daily calls during the 14-day period. Treat the data as a sample Number of calls and the number of days Calls (x) Number of days f(x) 4 1 5 3 6 4 7 4 8 2 The relative frequency table below shows the closing share price changes for the 100 most actively traded SP500 stocks. Use the grouped data table to approximate the mean for the data represented. SP500 price changes, interval midpoints and proportion of stocks Price Change Interval Midpoint Proportion of Stocks -1.00 to under -.60 -0.80 0.03 -.60 to under -.20 -0.40 0.03 -.20 to under .20 0.00 0.2 .20 to under .60 0.40 0.44 .60 to under 1.00 0.80 0.16 1.00 to under 1.40 1.20 0.06 1.40 to under 1.80 1.60 0.05 1.80 to under 2.20 2.00 0.03
Answers
The mean of the given data set is 3.5, the variance is 5.056, and the approximate mean using the grouped data table is 0.428.
The average of a set of values is referred to as the mean. To calculate the mean of a dataset, add up all of the values and divide by the number of values.
We can calculate the mean of the given data set as follows:
Mean = (9 + 6 + 2 + 0 + 2 + 3 + 5 + 2 + 1 + 5)/10
Mean = 3.5
Variance:Variance is a measure of how much a set of data varies. In other words, variance tells us how far each value in the dataset is from the mean. The variance formula is as follows:
σ² = (Σ(x - μ)²) / N
Where σ² is the variance, Σ is the sum, x is each value in the data set, μ is the mean of the data set, and N is the number of values in the data set.
Using the above formula, we can calculate the variance for the given data as follows:
First, we need to calculate the mean of the data set.x f(x)
xf(x)4 1 45 3 15 6 4 24 7 4 28 8 2 16
Total 14 128
Mean (μ) = 128 / 14 = 9.14
σ² = (Σ(x - μ)²) / N
σ² = [1(4 - 9.14)² + 3(5 - 9.14)² + 4(6 - 9.14)² + 4(7 - 9.14)² + 2(8 - 9.14)²] / 14
σ² = 5.056
Approximating the Mean:
We can use the midpoint of each interval as an approximate value for the entire interval. We can calculate the approximate mean as follows:
Mean = Σ(midpoint × proportion of stocks)
Mean = (-0.80 × 0.03) + (-0.40 × 0.03) + (0.00 × 0.2) + (0.40 × 0.44) + (0.80 × 0.16) + (1.20 × 0.06) + (1.60 × 0.05) + (2.00 × 0.03)
Mean = 0.428
Therefore, the mean of the given data set is 3.5, the variance is 5.056, and the approximate mean using the grouped data table is 0.428.
To know more about variance visit:
brainly.com/question/29253308
#SPJ11
Find the lengths of all segments in the diagram.
AB =
BC =
BD =
AC =

Answers
Answer:
Since we know that AD =12
AC=1/2*AD
AC=6
AB=BC=1/2*AC
AB=BC=3
hope you like the answer
please Mark as brainlist