R1 and R2 be relations on a set A represented by the matrices ?
Answers
R1 and R2 are relations on a set A, which means they define a set of ordered pairs of elements in A. The matrices that represent R1 and R2 can be thought of as a way to visualize these ordered pairs.
Each row and column of the matrix corresponds to an element in A. If there is a 1 in the ith row and jth column of the matrix for R1, then (i,j) is an ordered pair in R1. Similarly, if there is a 1 in the ith row and jth column of the matrix for R2, then (i,j) is an ordered pair in R2.
If there is a 0 in a particular position in the matrix, then the corresponding pair is not in the relation.
Let R1 and R2 be relations on a set A. These relations can be represented by matrices M1 and M2, respectively, with dimensions |A|x|A|, where |A| is the cardinality of set A. The elements of the matrices M1 and M2 are binary, indicating whether there is a relation between the corresponding elements of set A in R1 and R2, respectively. If there is a relation, the matrix element will be 1, and if there is no relation, the matrix element will be 0.
To know more about set, refer to the link below:
https://brainly.com/question/13088885#
#SPJ11
Related Questions
Write an equation in point-slope form for the line that passes through each point
with the given slope. Then graph the equation.
1. (-6, -3), m = -1
2. (-7, 6), m = 0
3. (-2, 11), m=4/3

Answers
The equation of the line passing through
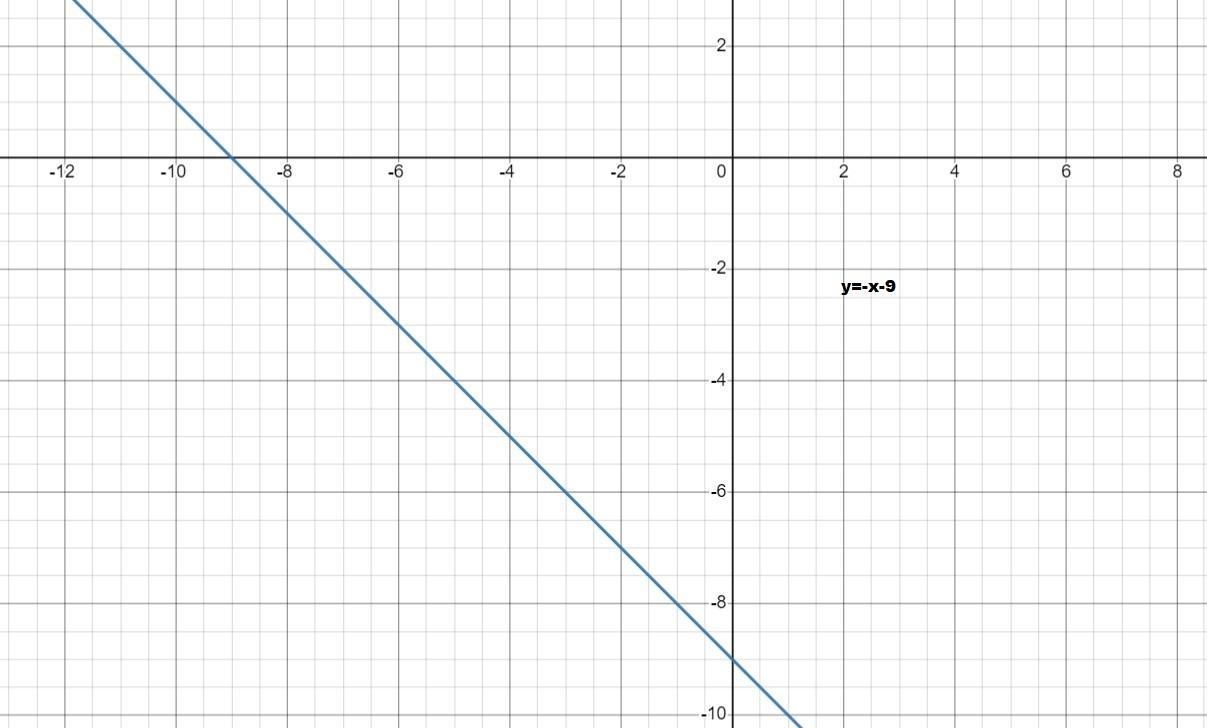
(1) point (-6, -3) and m = -1 is y = -x -9 .
(2) point (-7 , 6) and m = 0 is y = 6 ,
(3) point (-2 , 11) and m = 4/3 is y = (4/3)x + 41/3 .
the graph of the line is shown below .
In the question ,
point on the line and slope of the line is given
So , equation will be
Part(1)
(-6, -3), m = -1
(y -(-3)) = -1(x -(-6))
y + 3 = -1(x + 6)
y + 3 = -x - 6
y = -x -6 -3
y = -x -9
the equation is y = -x -9 .
Part(2)
(-7, 6), m = 0
(y - 6) = 0(x -(-7))
y - 6 = 0(x + 7)
y - 6 = 0
y = 6
the equation is y = 6
Part(3)
(-2, 11), m=4/3
(y - 11) = (4/3)(x -(-2))
y - 11 = (4/3)x + 8/3
y = (4/3)x + 8/3 + 11
y = (4/3)x + 41/3
the equation is y = (4/3)x + 41/3
the graph of all the three equations are shown below .
Therefore , The equation of the line passing through
(1) point (-6, -3) and m = -1 is y = -x -9 .
(2) point (-7 , 6) and m = 0 is y = 6 ,
(3) point (-2 , 11) and m = 4/3 is y = (4/3)x + 41/3 .
Learn more about Equation Of Line here
https://brainly.com/question/21298390
#SPJ1


x2 - 2xy + y2 when x = 3 and y = 2
Answers
Answer:
1
Step-by-step explanation:
Substitute 3 for x and 2 for y:
3^2 - 2(3)(2) + 2^2
= 9 - 12 + 4
= 1
3^2−(2)(3)(2)+2^2
3^2−(2)(3)(2)+2^2
= 1
Find the y-intercept for the parabola defined by
this equation:
y=-6x² – 7x – 2
Separate the values with a comma.
Answers
Answer:
the y intercept will be the c value of the parabola so the y intercept is -2, (0,-2)
Step-by-step explanation:
Lenny bought a motorcycle. He paid 12.512.5% in tax. The tax added $1437.501437.50 to the price of the motorcycle. What was the price of the motorcycle, not including the tax?
Answers
The price of the Motorcycle, not including the tax, is $11,500
The price of the motorcycle before the tax, we need to subtract the tax amount from the total price, including the tax. Let's denote the price of the motorcycle before tax as P.
Given:
Tax rate = 12.5%
Tax amount = $1437.50
We know that the tax amount is equal to 12.5% of the price of the motorcycle:
Tax amount = 0.125 * P
We can set up the equation and solve for P:
0.125 * P = $1437.50
To isolate P, divide both sides of the equation by 0.125:
P = $1437.50 / 0.125
Performing the calculation:
P = $11,500
Therefore, the price of the motorcycle, not including the tax, is $11,500.
Tax amount = 0.125 * $11,500 = $1437.50
The tax amount matches the given information, confirming that the price of the motorcycle before tax is indeed $11,500.
To know more about Motorcycle.
https://brainly.com/question/29915026
#SPJ11
Will mark Brainlyest Use the properties of exponents to simplify the expression(y^3/2 X^-1/2)^4

Answers
Answer:
the answer would be y^6/x^2
Step-by-step explanation:
so (Y) to the sixth power over (X) to the second power
A researcher is studying the effect of a stress-reduction program on people's levels of cortisol (a stress hormone). She tests the cortisol levels of 50 people before starting the program, and then tests the participants' cortisol levels again after completing the program. She wants to test the claim that the stress-reduction program reduces cortisol levels. Which of the following describes the researcher's null and alternative hypotheses? a. null hypothesis: μ2 - μ1 = 0; alternative hypothesis: μ2 - μ1 <0 b. null hypothesis: μ2 - μ1 <0; alternative hypothesis: μ2 - μ1 > 0 c. null hypothesis: μD = 0; alternative hypothesis: μD <0 d. null hypothesis: μD <0; alternative hypothesis: μD = 0
Answers
Null hypothesis: μD = 0; alternative hypothesis: μD < 0 is the correct statement describes the researcher's null and alternative hypotheses. The correct answer is c.
In this scenario, the researcher is comparing the cortisol levels before and after the stress-reduction program for the same individuals. The null hypothesis (H0) states that there is no difference in the mean cortisol levels before and after the program, which is represented by μD = 0. The alternative hypothesis (Ha) suggests that the stress-reduction program reduces cortisol levels, indicating a decrease in the mean cortisol levels after the program, represented by μD < 0.
It is important to note that the symbol "μD" represents the population mean difference in cortisol levels before and after the program. The correct answer is c.
Learn more about null hypothesis
brainly.com/question/28920252
#SPJ11
S, T, and U are the midpoints of the sides of Triangle PQR.
Suppose QR= 28 SU= 50 and PR= 96. Find the lengths of PQ, TU, and PT.
Answers
Answer:
PQ = 100
TU = 48
PT = 50
Step-by-step explanation:
PQ = 2SU = 2(50) = 100
TU = (PR)/2 = 48
PT = (PQ)/2 = 50
Dan was thinking of a number. Dan halves the number and gets an answer of 18.8. Form an equation with x from the information.
Answers
Answer:
\(\dfrac{x}{2} = 18.8\)
Step-by-step explanation:
Let x represent the number Dan was thinking about.
Half of the number, x = 18.8
Therefore, when x is divided by 2, the result is 18.8
The equation which can be formed with the given information is therefore;
\(\dfrac{x}{2} = 18.8\)
Develop a full regression model based on all the predictor variables indicated. Choose the right model equation below
A. Assessed Value = 246.42+43.94*(Size) + 15.69*(Fireplace Coded)+8.25*(Bedrooms) B. Asking Price = 246.42+43.94*(Size) + 15.69*(Fireplace Coded)+8.25*(Bedrooms)
C. Assessed Value = 246.42+43.94*(Size) + 15.69*(Fireplace Coded)+0.9677*(Bathrooms) D. Assessed Value = 244.4325 + 43.5532*(Size)+ 8.1910*(Bedrooms)+ 0.9677*(Bathrooms)
Q2. A review of the t-test on the significance of individual independent variable suggests that, based on the p-values
A. Only one of the independent variable possibly needs to be retained B. Two of the independent variables possibly needs to be retained C. None of the independent variables could be retained D. Three of the independent variables could be retained
Q3:
Choose the right option below. Based on the full regression model involving all of the independent variables
A. VIF for Size = 2.336, VIF for Fireplace = 1.121, VIF for bedrooms = 1.979
B. VIF for Size = 5.3352, VIF for Fireplace = 10.1873, VIF for bedrooms = 2.7885
C. VIF for Fireplace = 1.1873, VIF for bedrooms = 1.9885
D. None of the above
Q4: Based on VIF values, there is concern for collinearity in this dataset
A. True B. False
Q5:
Based on the normal probability plot, the normality assumption seems to be met
A. True
B. False
Q:7: Based on conducting residual analysis the model seems
Group of answer choices
Adequate
Inadequate
Violates Independence Assumption
Not enough information to assess the LINE assumptions
Answers
Q.2: A review of the t-test on the significance of individual independent variable suggests that, based on the p-values. None of the independent variables could be retained. This is because if the p-value is high, it means the significance is low.
Q3: Choose the right option below. Based on the full regression model involving all of the independent variables. VIF for Size = 5.3352, VIF for Fireplace = 10.1873, VIF for bedrooms = 2.7885.
Q.4: Based on VIF values, there is concern for collinearity in this dataset. True
Q5: Based on the normal probability plot, the normality assumption seems to be met. True
Q7: Based on conducting residual analysis the model seems. Adequate.
Learn more about independent variable at
https://brainly.com/question/7228371
#SPJ11
can someone answer this question really quick
Simplify the expression by combining like terms.
43a−12b+13a+52b
Enter your answer as an expression, like this: 42x+53
Answers
Answer:
56a+40b
Step-by-step explanation:
43a plus 13a is 56a, -12b + 52b is 40b, together it's 56a+40b
For a recent paint job, Josh mixed red and white paint to make two different shades of pink. When the job was done, Josh ended up with leftover paint: 5 gallons of dark pink paint (80% red) and 4 gallons of light pink paint (30% red). Josh wants to make a medium pink color (50% red) to paint his daughter's bedroom. He will need 3 gallons to completely cover the walls. How much of each of the leftover paints should Josh mix to achieve his desired color?
? gallons of dark pink paint
? gallons of light pink paint
Answers
Josh should mix 1.2 gallons of dark pink paint and 1.8 gallons of light pink paint to achieve the desired medium pink color.
To find out how much of each leftover paint Josh should mix to achieve a medium pink color (50% red), we can set up a system of equations based on the percentages of red in the paints.
Let's assume that Josh needs x gallons of dark pink paint and y gallons of light pink paint to achieve the desired color.
The total amount of paint needed is 3 gallons, so we have the equation:
x + y = 3
The percentage of red in the dark pink paint is 80%, which means 80% of x gallons is red. Similarly, the percentage of red in the light pink paint is 30%, which means 30% of y gallons is red. Since Josh wants a 50% red mixture, we have the equation:
(80/100)x + (30/100)y = (50/100)(x + y)
Simplifying this equation, we get:
0.8x + 0.3y = 0.5(x + y)
Now, we can solve this system of equations to find the values of x and y.
Let's multiply both sides of the first equation by 0.3 to eliminate decimals:
0.3x + 0.3y = 0.3(3)
0.3x + 0.3y = 0.9
Now we can subtract the second equation from this equation:
(0.3x + 0.3y) - (0.8x + 0.3y) = 0.9 - 0.5(x + y)
-0.5x = 0.9 - 0.5x - 0.5y
Simplifying further, we have:
-0.5x = 0.9 - 0.5x - 0.5y
Now, rearrange the equation to isolate y:
0.5x - 0.5y = 0.9 - 0.5x
Next, divide through by -0.5:
x - y = -1.8 + x
Canceling out the x terms, we get:
-y = -1.8
Finally, solve for y:
y = 1.8
Substitute this value of y back into the first equation to solve for x:
x + 1.8 = 3
x = 3 - 1.8
x = 1.2
Therefore, Josh should mix 1.2 gallons of dark pink paint and 1.8 gallons of light pink paint to achieve the desired medium pink color.
for such more question on medium
https://brainly.com/question/14532771
#SPJ8
Given:
Prove:
Three lines AD, CF, and BE are intersecting each other at the midpoint O
Complete the proof.
It is given that
and
. By the
,
. Therefore,
. By the
,
, and by the
,
. After application of the
,
.
Answers
∠CFA ≅ ∠EDA (By Transitive Property of Congruence).
Given:
Three lines AD, CF, and BE are intersecting each other at the midpoint O.
To prove:
∠CFA ≅ ∠EDA
Proof:
Given that AD, CF, and BE intersect at the midpoint O.
By definition of a midpoint, OA ≅ OD, OB ≅ OE.
OA = OD and OB = OE.
Triangle OAD ≅ Triangle OBE (By Side-Side-Side congruence).
∠OAD ≅ ∠OBE (By Corresponding Parts of Congruent Triangles are Congruent).
∠CFA and ∠EDA are vertical angles.
∠OAD ≅ ∠CFA and ∠OBE ≅ ∠EDA (By Vertical Angles are Congruent).
Therefore, ∠CFA ≅ ∠EDA (By Transitive Property of Congruence).
Hence, it is proven that ∠CFA ≅ ∠EDA.
for such more question on Congruence
https://brainly.com/question/1675117
#SPJ8
9 m
3 m
3 m
What is the area, in square meters, of the shaded region in the diagram?
Answers
Answer:
Notice that the side length of the square is 38 m.
area of square = (side length)2 = (38 m)2 = 1444 m2
Notice that the diameter of the circle is 38 m .
And its radius = diameter / 2 = 38m / 2 = 19 m
area of circle = pi * radius2 = pi * (19m)2 = pi * 361 m2 ≈ 1133.54 m2
So......
area of shaded region = area of square - area of circle
area of shaded region ≈ 1444 m2 - 1133.54 m2
area of shaded region ≈ 310.46 m2
Step-by-step explanation:
Notice that the side length of the square is 38 m.
area of square = (side length)2 = (38 m)2 = 1444 m2
Notice that the diameter of the circle is 38 m .
And its radius = diameter / 2 = 38m / 2 = 19 m
area of circle = pi * radius2 = pi * (19m)2 = pi * 361 m2 ≈ 1133.54 m2
So......
area of shaded region = area of square - area of circle
area of shaded region ≈ 1444 m2 - 1133.54 m2
area of shaded region ≈ 310.46 m2
How is field data aggregated? Number of failed parts Number of failures Hours of operation Maintenance time Mark for follow up Question 3 of \( 7 . \) Data collection extends over a large number of it
Answers
Field data aggregation is the process of summarizing, combining, and analyzing data that has been collected from various sources. The following are some of the common ways that field data is aggregated: Count of Failures: A count of how many times a failure has occurred within a given period of time,
such as a day or a week. Number of Failed Parts: The number of parts that have failed over a given period of time, such as a day or a week. Hours of Operation: The amount of time that a machine or system was operational during a given period of time, such as a day or a week. Maintenance Time: The amount of time that was spent maintaining a machine or system during a given period of time, such as a day or a week.
Mark for Follow-Up: An indication of which issues need to be addressed or followed up on to prevent future failures or improve performance. Field data aggregation is the process of summarizing, combining, and analyzing data that has been collected from various sources. The following are some of the common ways that field data is aggregated: Count of Failures: A count of how many times a failure has occurred within a given period of time,
To know more about summarizing visit:
https://brainly.com/question/20058250
#SPJ11
Use the triangle to answer the question. What is the value of x?

Answers
Answer:
B). 48
Step-by-step explanation:
48•64=3072
3072÷64=48
Answer:
value of X=180-(48+48)
=180-96
=84
Carrie walks 525 feet from her house to jay's house. Then, she walks another 280 feet to asha's house.
Answers
Answer:
\(Total = 805ft\)
Step-by-step explanation:
Given
\(Jay's = 525ft\)
\(Asha's = 280ft\)
Required [Missing from the question]
The total distance walked
To do this, we simply add up the distance walked to Jay's and then to Asha's house.
So, we have:
\(Total = Jay's + Asha's\)
\(Total = 525ft + 280ft\)
\(Total = 805ft\)
what is 7 divided by -14
Answers
A forester shows the accompanying histogram of tree diameters he used in analyzing 27 trees in a large woods that was for sale. Was he justified in using a Normal model to analyze the woods? Explain, citing some specific concerns
Choose the correct answer below
A. Yes, because the histogram is unimodal and symmetric.
B. No, because while the histogram is unimodal, it is not symmetric
C. No, because the histogram is not unimodal or symmetric.
D. No, because while the histogram is symmetric, it is not unimodal
Answers
Yes, the forester was justified in using a Normal model to analyze the woods, because the histogram is unimodal and symmetric. So option A is correct.
A histogram is a type of graph that uses vertical bars to show the distribution of a set of data. This particular histogram is unimodal, meaning that it has one peak which is an indication that the data is distributed normally. Additionally, the histogram is symmetric, which is another indication that the data is normally distributed.
Using a Normal model to analyze the woods is a valid approach because it allows the forester to identify the average diameter of the trees, as well as the spread of the data. It also allows him to check for any outliers, or points that fall outside the normal range. With this information, the forester can determine if the woods is suitable for sale, or if the buyer should be aware of any unexpected features.
Overall, the histogram is an effective way for the forester to analyze the data and determine if a Normal model is appropriate. By noting the unimodal and symmetric nature of the histogram, the forester can be sure that a Normal model will accurately represent the data, allowing him to make an informed decision about the woods.
For more such questions on histogram
https://brainly.com/question/18198700
#SPJ11
Please help me on my hw It’s all one question

Answers
(a)
The model of the profit y (in dollars) as a function of the number of cooktops produced per month is:
y = 10x + 0.5x² - 0.001x³ - 4000, for 0 ≤ x ≤ 450
We can see the intersection of this graph and the axis:
For the y axis: x = 0
y(x = 0) = 10*0 + 0.5*0² - 0.001*0³ - 4000 = -4000
For the x axis: y = 0
0 = 10x + 0.5x² - 0.001x³ - 4000
Solving for x: x = {-91.1503, 87.0538, 504.096}
From these values, only x = 87.0538 lies in 0 ≤ x ≤ 450.
Finally, we calculate the final value: x = 450
y = 10*450 + 0.5*450² - 0.001*450³ - 4000 = 10 625
From these results, the graph is:
(b)
To begin generating a profit, we must find an x value such that y(x) > 0.
From item (a), we found that such value is x = 87.0538 or x = 88 (to the bigger whole number). That is, values beyond 88 for the number of cooktops will generate a profit, as we can see from the graph, where for x ≥ 88 the function is positive.
Answer: 88
(c)
We need to solve the inequality:
y > 15 000
10x + 0.5x² - 0.001x³ - 4000 > 15 000
If we solve the equality first:
10x + 0.5x² - 0.001x³ - 4000 = 15 000
We get: x = {-175.3, 262.64, 412.66}
Only 262.64 and 412.66 lie in 0 ≤ x ≤ 450. So, rounding to the nearest whole number, the interval is:
x ∈ [263, 412]
*x is a whole number*

H0 describes the expected result of a statistical test if there is no difference between two or more groups being compared. True False
Answers
If there is no difference between any of the two or more groups being compared, H0 indicates the anticipated outcome of a statistical test. This statement is true.
H0, or the null hypothesis, represents the assumption that there is no significant difference between the groups being compared in a statistical test. It is the default hypothesis that is tested against an alternative hypothesis, H1, which states that there is a significant difference between the groups.
The null hypothesis is essential in hypothesis testing as it serves as the basis for determining whether the results of the test are statistically significant or due to chance. The statistical test is designed to reject the null hypothesis if the calculated p-value is less than the pre-determined significance level, indicating that the observed results are unlikely to have occurred by chance alone.
The acceptance or rejection of the null hypothesis has important implications for decision-making in various fields, such as medicine, psychology, and business. Therefore, it is crucial to carefully construct and test the null hypothesis to ensure that the results are accurate and meaningful.
To learn more about statistical tests
https://brainly.com/question/28957899
#SPJ4
numbers that do not form a fact family
Answers
The numbers that do not form a fact family are solved
Given data ,
A fact family consists of a set of related addition and subtraction facts that use the same numbers. For example, the numbers 3, 5, and 8 form a fact family because:
3 + 5 = 8
5 + 3 = 8
8 - 5 = 3
8 - 3 = 5
Numbers that do not form a fact family are any set of numbers that do not follow this pattern. For example, the numbers 2, 4, and 7 do not form a fact family because no combination of addition and subtraction using these numbers produces the other two numbers.
To learn more about fact family click :
https://brainly.com/question/11585082
#SPJ1
T/F: Nonsampling errors reduce the overall quality of data regardless of the data collection method.
Answers
True. Nonsampling errors refer to errors that occur during the data collection process that are not related to the sampling method used. These errors can occur in any type of data collection method, whether it be through surveys, experiments, or observational studies.
Nonsampling errors can arise due to a variety of reasons, such as poor survey design, biased sampling methods, inadequate training of surveyors, errors in data entry or processing, or even deliberate fraud.
Nonsampling errors can have a significant impact on the quality of the data collected, as they can introduce biases and inaccuracies into the results. These errors can result in incorrect conclusions and decisions based on the data, which can have serious consequences. Therefore, it is important to take steps to minimize nonsampling errors during the data collection process, such as carefully designing surveys, ensuring proper training of surveyors, and conducting thorough quality checks on the data collected.
Learn more about Nonsampling here:
https://brainly.com/question/15396688
#SPJ11
Help help help help

Answers
The indicated pairs of angles are congruent by;
1) ∠1 and ∠2 are complementary angles.
2) ∠1 and ∠2 are vertical angles.
3) ∠1 and ∠2 are supplementary angles
How to interpret congruent angles?The congruent angles given in the options are vertical angles, complementary angles and supplementary angles.
1) Vertical angles are defined as the angles formed that are opposite each other when two lines cross each other. Vertical angle means that they share the same vertex.
2) Complementary angles are simply defined as angles that sum up to 90 degrees.
3) Supplementary angles are simply defined as angles that sum up to 180 degrees.
Now, the first image shows a right angle which is 90 degrees and is divided into ∠1 and ∠2. Since ∠1 and ∠2 sum up to 90 degrees, then we say that they are complementary angles.
The second image shows two angles form as a result of intersection of two lines and so they are vertical angles.
The third image shows two angles on a straight line and since the sum of angles on a a straight line is equal to 180 degrees, then both angles are supplementary angles.
Read more about congruent angles at; https://brainly.com/question/14791175
#SPJ1
small p-values indicate that the observed sample is inconsistent with the null hypothesis. T/F?
Answers
True. Small p-values support the rejection of the null hypothesis and provide evidence in favor of an alternative hypothesis.
Small p-values indicate that the observed sample data provides strong evidence against the null hypothesis. The p-value is a measure of the strength of evidence against the null hypothesis in a hypothesis test. It represents the probability of observing the obtained sample data, or more extreme data, if the null hypothesis is true.
When the p-value is small (typically less than a predetermined significance level, such as 0.05), it suggests that the observed sample data is unlikely to have occurred by chance under the assumption of the null hypothesis. In other words, a small p-value indicates that the observed data is inconsistent with the null hypothesis.
Conversely, when the p-value is large (greater than the significance level), it suggests that the observed sample data is likely to occur by chance even if the null hypothesis is true. In such cases, there is not enough evidence to reject the null hypothesis. Therefore, small p-values support the rejection of the null hypothesis and provide evidence in favor of an alternative hypothesis.
Learn more about P-value here:
https://brainly.com/question/30461126
#SPJ11
the probability of serena serving an ace in tennis is 0.15, and the probability that she double faults is 0.25. (note that you cannot both ace and double fault at the same time.) what is the probability that serena does not serve an ace or a double fault?
Answers
The probability that Serena does not serve an ace or a double fault is 0.6, when the probability of Serena serving an ace in tennis is 0.15, and the probability that she double faults is 0.25.
Define probability.The formula of the favorable outcome over the total outcomes is used to describe probability. The likelihood of flipping a coin heads is one example. Given that there is only one head and two total sides, 50% of the time, a head will land up-side-down.
Given,
Serve tennis probability = 0.15
No ace probability = 1-0.15
No ace probability = 0.85
Double fault probability = 0.25
No double fault probability = 1-0.25 = 0.75
No double fault probability = 0.75
The probability of not receiving an Ace or Double Fault: is
= 0.75 ×0.85
= 0.6.
The probability that Serena does not serve an ace or a double fault is 0.6.
To learn more about probability, visit:
https://brainly.com/question/11234923
#SPJ4
Plz help me will give crown and 20 points I really need help on this and can you answer all the questions

Answers
Answer:
The answer will be
1 c
2 e
3 b
4 a
5 d

PLEASE HELP BRO ITS THE LAST QUESTION FROM MY HOMEWORK

Answers
Answer:7
Step-by-step explanation:
just gotta add it up all good
Answer:
7
Step-by-step explanation:
In terms of ln(4) and ln(5), rewrite the expression: ln 500
Answers
Answer:
2ln5 + ln4 + ln5
Step-by-step explanation:
Think about how we can write 500 in terms of 4 and 5.
\(500 = 5^2*(4*5)\)
So ln(500) can be written as ln(5^2*4*5)
Using log rules \(log_b(x*y)=log_b(x)+log_b(y)\\logb(x^a)=a*log(x)\)
we can rewrite ln(500) to 2ln5 + ln4 + ln5
Gandalf the Grey started in the Forest of Mirkwood at a point with coordinates and arrived in the Iron Hills at the point with coordinates (3, 4). If he began walking in the direction of the vector and changes direction only once, when he turns at a right angle, what are the coordinates of the point where he makes the turn?
Answers
Since the equation does not equal zero, our initial guess was incorrect. We would need to solve the equation using other methods such as factoring, completing the square, or using the quadratic formula to find the precise coordinates where Gandalf makes the turn.
To determine the coordinates where Gandalf the Grey makes the turn, we need to find a vector that represents the direction from the Forest of Mirkwood to the Iron Hills.
The vector representing the direction can be obtained by subtracting the coordinates of the starting point (Forest of Mirkwood) from the coordinates of the destination point (Iron Hills). Therefore:
Direction vector = (3, 4) - (x, y)
Since Gandalf makes a right-angle turn, the direction vector will be perpendicular to the vector between the turn point and the starting point.
For two vectors to be perpendicular, their dot product must be zero. The dot product of two vectors (a, b) and (c, d) can be calculated as ac + bd.
Using this information, we can set up the equation:
(3, 4) - (x, y) dot (x, y) = 0
Expanding the equation, we get:
(3 - x) * x + (4 - y) * y = 0
Simplifying further, we have:
3x + 4y - x^2 - y^2 = 0
Since Gandalf changes direction only once, we can assume that the turn point is within reasonable proximity to the starting point. Hence, we can make an educated guess to solve the equation. Let's assume x = 1 and y = 2 as an example.
Substituting these values into the equation:
3(1) + 4(2) - (1^2) - (2^2) = 0
3 + 8 - 1 - 4 = 6 - 5 = 1
Know more about vector here:
https://brainly.com/question/24256726
#SPJ11
The larger number i 18 more than twice the maller. If the un of the number i 93 find both number
Answers
Both a smaller and a bigger number are 25 and 68
What is sum of numbers?The outcome or conclusion we get at when we add two or more integers is known as the SUM. example the total of the addends, 6, and 4, is 10. In other words, we may argue that 8 plus 5 equals 13 or that 8 plus 5 equals 13.
Here, we've been given two numbers, one smaller and one bigger, where the smaller number is X and the larger number is 18 more than twice the smaller number.
2X + 18 is the greater number.
Because the total is now 93, X + (2X+18) = 93
3X = 93 - 18 .
X = 25
larger number will be 2(25) + 18 = 68
Thus the numbers are smaller number is 25 and larger number is 68.
To know more about sum of numbers:
brainly.ph/question/19095889
#SPJ4